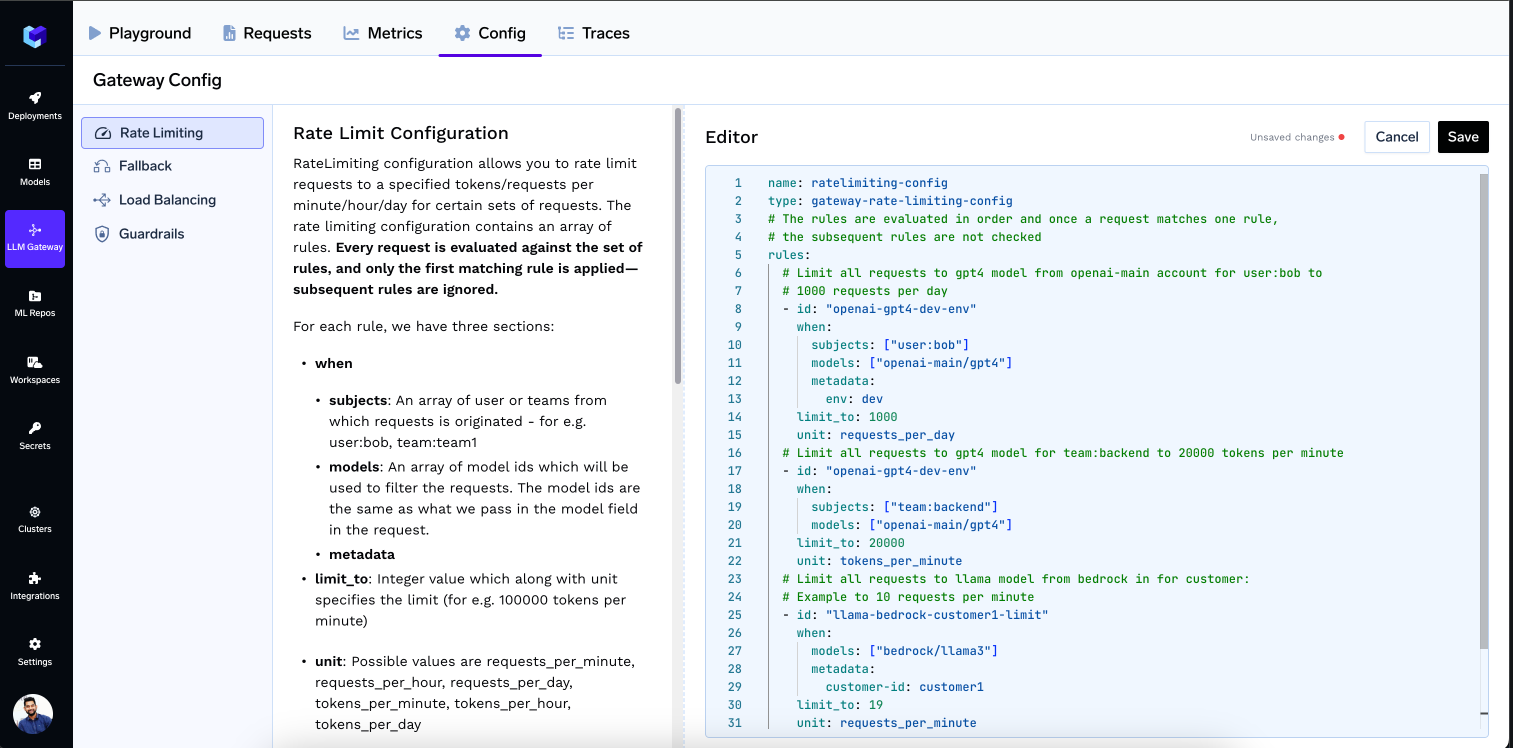
Rate Limiting
RateLimiting configuration allows you to rate limit requests to a specified tokens/requests per minute/hour/day for certain sets of requests. The rate limiting configuration contains an array of rules. Every request is evaluated against the set of rules, and only the first matching rule is applied—subsequent rules are ignored. So keep generic ones at bottom, specialised configs at top.
For each rule, we have three sections:
- when
- subjects: An array of user, teams or virutal accounts from which requests is originated - for e.g. user:[email protected], team:team1, virtualaccount:virtualaccountname
- models: An array of model ids which will be used to filter the requests. The model ids are the same as what we pass in the model field in the request.
- metadata.
- limit_to: Integer value which along with unit specifies the limit (for e.g. 100000 tokens per minute)
- unit: Possible values are requests_per_minute, requests_per_hour, requests_per_day, tokens_per_minute, tokens_per_hour, tokens_per_day
Let's say you want to rate limit requests based on the following rules:
- Limit all requests to gpt4 model from openai-main account for user:[email protected] to 1000 requests per day
- Limit all requests to gpt4 model for team:backend to 20000 tokens per minute
- Limit all requests to gpt4 model for virtualaccount:virtualaccount1 to 20000 tokens per minute
- Limit all models to have a limit of 1000000 tokens per day
- Limit all users to have a limit of 1000000 tokens per day
- Limit all users to have a limit of 1000000 tokens per day for each model
Your rate limit config would look like this:
name: ratelimiting-config
type: gateway-rate-limiting-config
# The rules are evaluated in order, and all matching rules are considered.
# If any one of them causes a rate limit, the corresponding ID will be returned.
rules:
# Limit all requests to gpt4 model from openai-main account for user:[email protected] to
# 1000 requests per day
- id: "openai-gpt4-dev-env"
when:
subjects: ["user:[email protected]"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# Limit all requests to gpt4 model for team:backend to 20000 tokens per minute
- id: "openai-gpt4-dev-env"
when:
subjects: ["team:backend"]
models: ["openai-main/gpt4"]
limit_to: 20000
unit: tokens_per_minute
# Limit all requests to gpt4 model for virtualaccount:virtualaccount1 to 20000 tokens per minute
- id: "openai-gpt4-dev-env"
when:
subjects: ["virtualaccount:virtualaccount1"]
models: ["openai-main/gpt4"]
limit_to: 20000
unit: tokens_per_minute
# Limit all models to have a limit of 1000000 tokens per day
- id: "{model}-daily-limit"
when: {}
limit_to: 1000000
unit: tokens_per_day
# Limit all users to have a limit of 1000000 tokens per day
- id: "{user}-daily-limit"
when:{}
limit_to: 1000000
# Limit all users to have a limit of 1000000 tokens per day for each model
- id: "{user}-{model}-daily-limit"
when: {}
limit_to: 1000000
unit: tokens_per_dayConfigure Ratelimit on Gateway
It's straightforward—simply go to the Config tab in the Gateway, add your configuration, and save.
Example to Setup Rate Limits for User, Teams and Virtual Accounts
TrueFoundry allows you to setup rate limit for specific users, teams and virtual accounts.
Setup rate limit for users
Say you want to limit all requests to gpt4 model from openai-main account for users [email protected] and [email protected] to 1000 requests per day
name: ratelimiting-config
type: gateway-rate-limiting-config
# The rules are evaluated in order, and all matching rules are considered.
# If any one of them causes a rate limit, the corresponding ID will be returned.
rules:
# Limit all requests to gpt4 model from openai-main account for user:[email protected] and user:[email protected] to 1000 requests per day
- id: "openai-gpt4-dev-env"
when:
subjects: ["user:[email protected]", "user:[email protected]"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_daySetup rate limit for teams
Say you want to limit all requests for team frontend to 5000 requests per day
name: ratelimiting-config
type: gateway-rate-limiting-config
# The rules are evaluated in order, and all matching rules are considered.
# If any one of them causes a rate limit, the corresponding ID will be returned.
rules:
# Limit all requests for team frontend to 5000 requests per day
- id: "openai-gpt4-dev-env"
when:
subjects: ["team:frontend"]
limit_to: 5000
unit: requests_per_daySetup rate limit for virtual accounts
Say you want to limit all requests for virtual account va-james to 1500 requests per day
name: ratelimiting-config
type: gateway-rate-limiting-config
# The rules are evaluated in order, and all matching rules are considered.
# If any one of them causes a rate limit, the corresponding ID will be returned.
rules:
# Limit all requests for virtual account va-james to 1500 requests per day
- id: "openai-gpt4-dev-env"
when:
subjects: ["virtualaccount:va-james"]
limit_to: 1500
unit: requests_per_dayUpdated 29 days ago