TrueFoundry allows you to tweak the most common parameters of the deployment through the service spec. However, there might be situations in which you might want to override some fields that are not exposed in the TrueFoundry Service spec. You can then use Kustomize to add, patch or delete the Kubernetes resources that TrueFoundry deploys on the cluster.Kustomize enables you to
Patch the rendered Kubernetes resources generated by the TrueFoundry Application. E.g. Adding extra annotations for Prometheus / Datadog
Add extra Kubernetes resources along with your TrueFoundry Application. E.g. Adding extra ConfigMap, Secret, Istio VirtualService, etc
Truefoundry doesn’t allow you to use Kustomize to create cluster level resources like ClusterRole, ClusterRoleBinding or non-namespace scoped resources like EnvoyFilter and WasmPlugin. You can create these resources only if you are cluster admin for the cluster, else the deployment will fail. This prevents the scenario where a user who has access to a certain workspace can create cluster level resources and impact other workloads in the cluster.
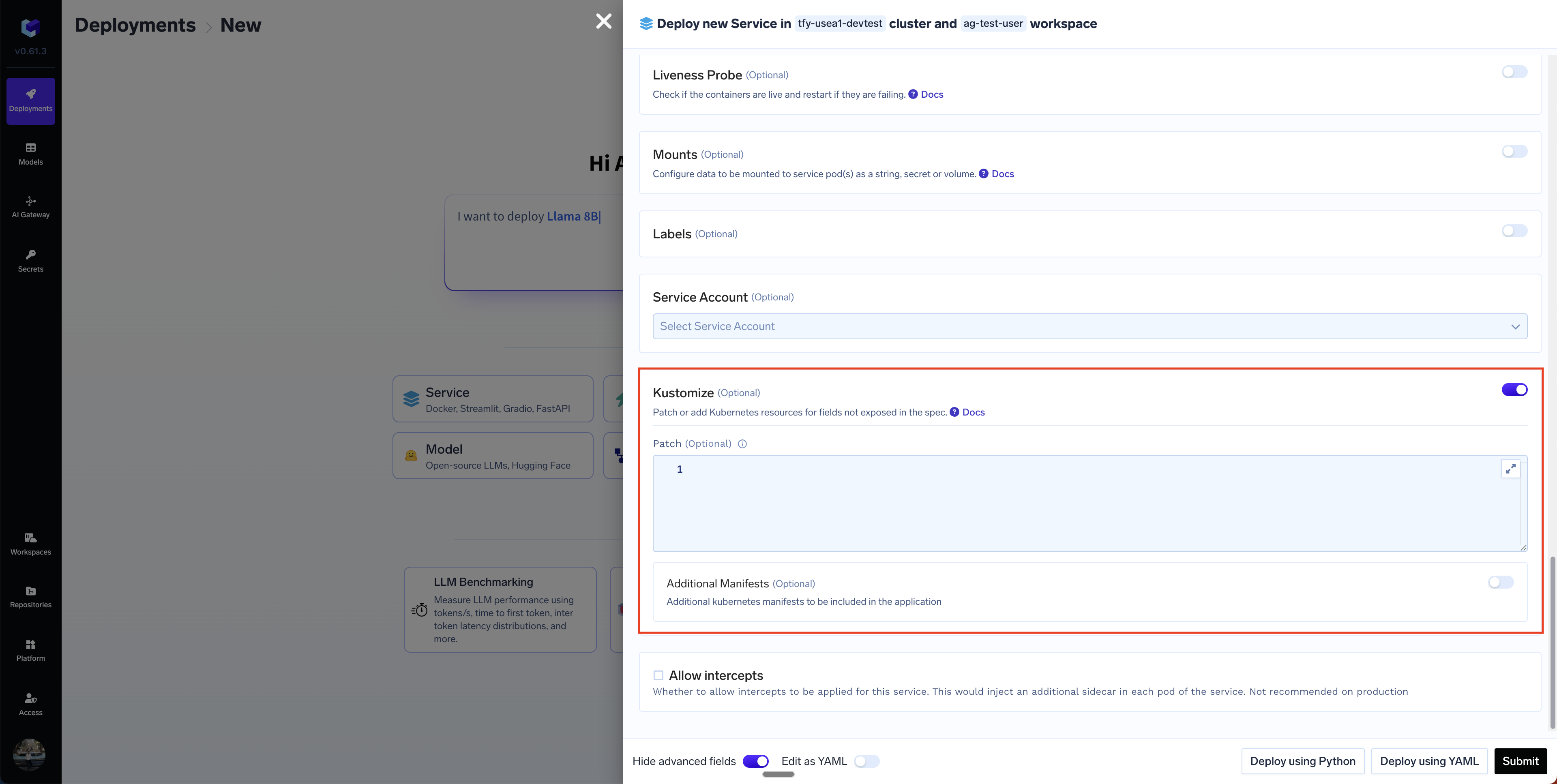
You can add patches and resources using the kustomize field in the service deployment form.There are two sections:
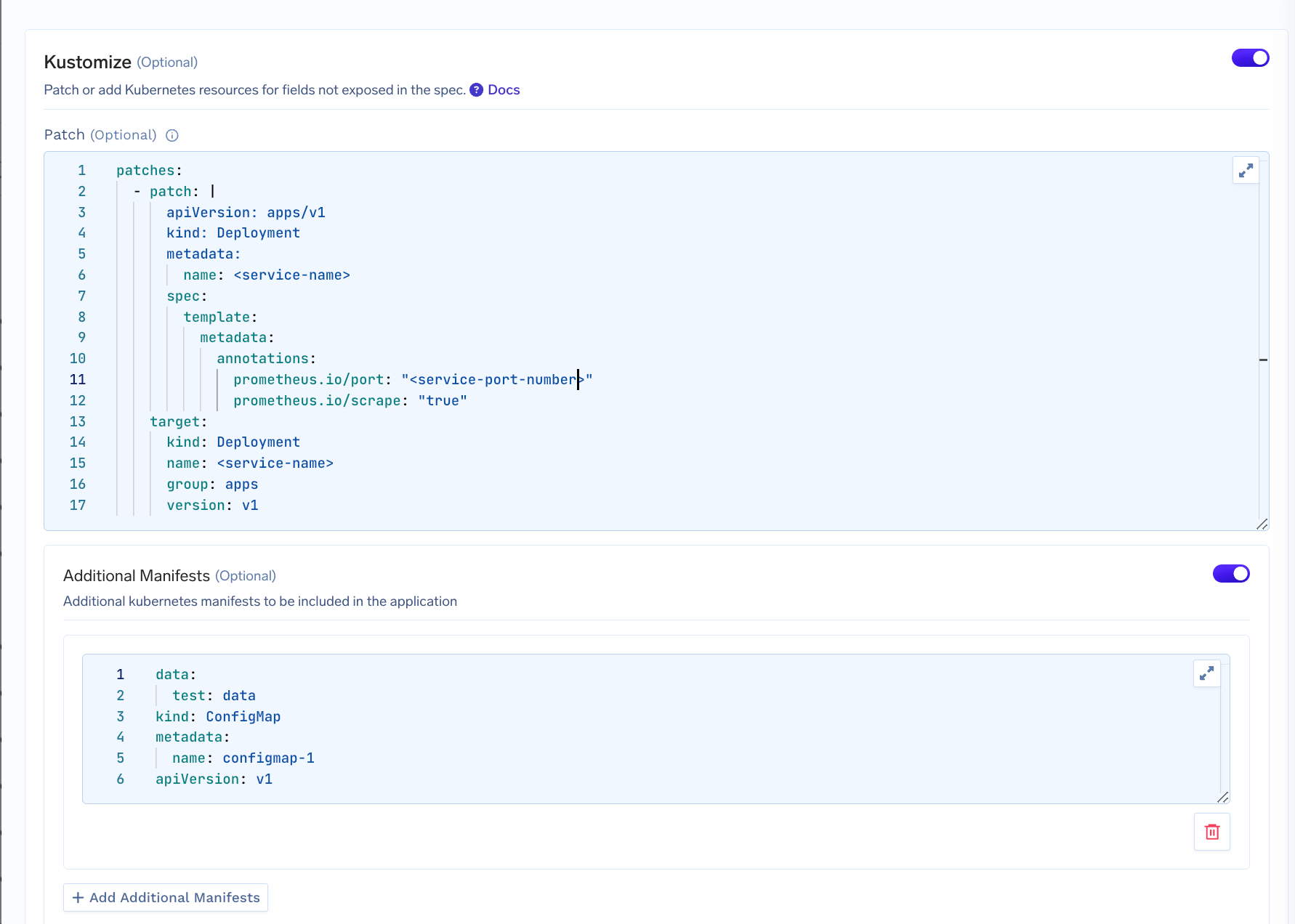
Patch: We define an array of patches to be applied to the rendered Kubernetes resources generated by the TrueFoundry Application. For e.g. this Kustomize patch adds Prometheus scraping annotations to the pod template metadata of a Deployment named “my-service”. Specifically, it configures Prometheus to scrape metrics from port 8000 by setting prometheus.io/port to “8000” and enabling scraping with prometheus.io/scrape set to “true”.
Additional Manifest: This section allows you to add new Kubernetes resources to the deployment. The example below adds a new ConfigMap to the deployment.
Enter the Keda ScaledObject spec in the Additional Manifest section:
Copy
Ask AI
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata: name: <scaledobject-name> namespace: defaultspec: scaleTargetRef: name: <your-deployment-name> # Replace with your deployment name triggers: - type: memory metadata: # You can use either "Utilization" or "AverageValue" type: Utilization value: "70" # Scale when average memory usage is above 70% # Or, if using AverageValue: # value: "2Gi" # Scale when average memory usage is 2Gi minReplicaCount: 1 maxReplicaCount: 10
To add any custom autoscaling like based on queue length, you can checkout Keda documentation to get
the ScaledObject spec.