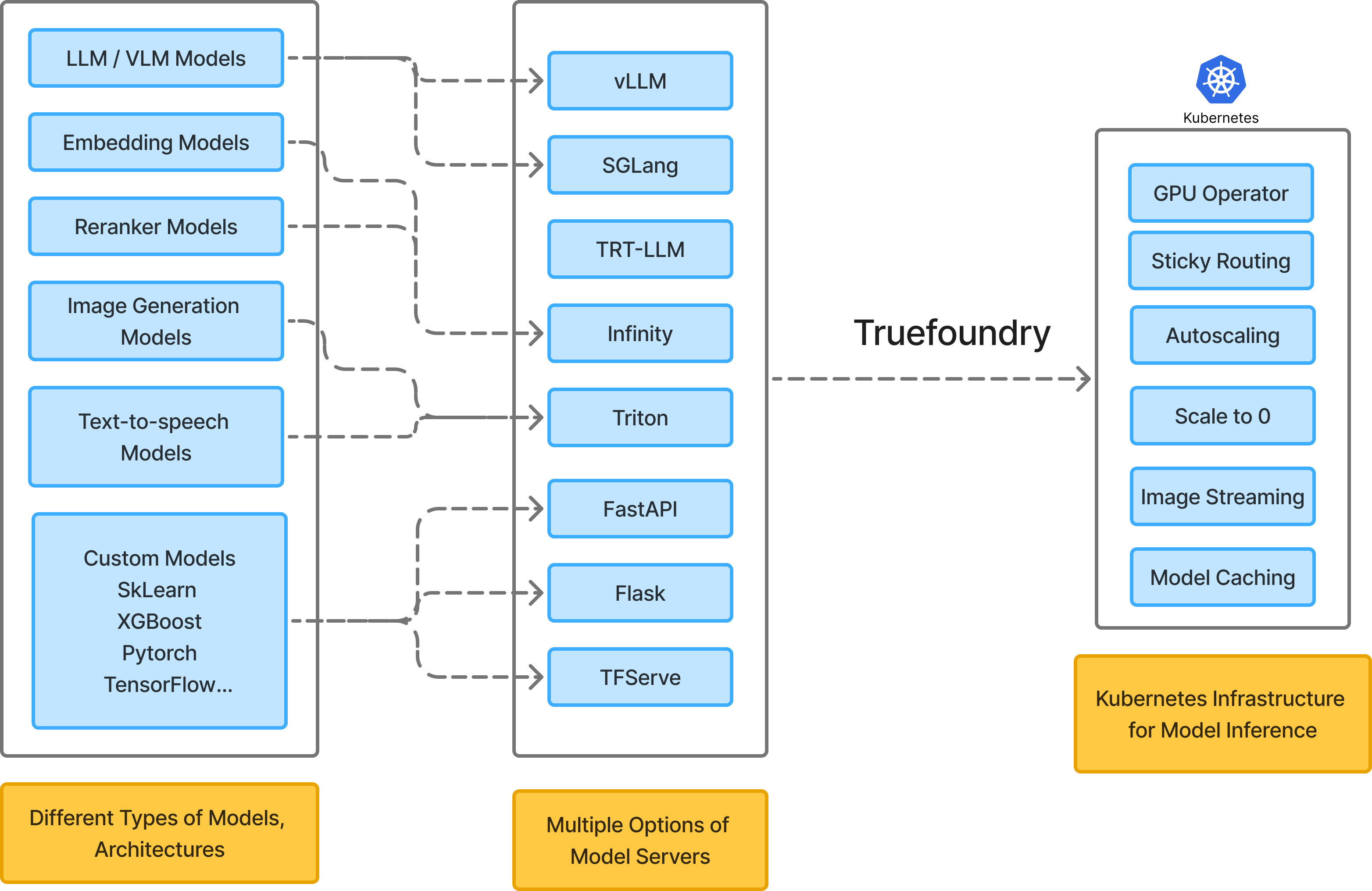
Model Deployment Options
Bring your own inference code and model in any framework
TrueFoundry can deploy model inference code in any framework that you are using. Here are a few examples of deploying models in most commonly used frameworks and model servers:HuggingFace
Deploy Transformers / Diffusers models with vLLM, SGLang, Nvidia Triton, etc.
Scikit Learn & XGBoost
Deploy Scikit Learn and XGBoost models with FastAPI or Nvidia PyTriton.
FastAPI
Most flexible option that can wrap any inference code.
LitServe
Wrap any model with LitServe with optional features like dynamic batching and advanced features.
AWS Multi Model Server
Deploy models with AWS Multi Model Server.
TorchServe
Deploy Pytorch models with TorchServe.
TensorFlow Serve
Deploy TensorFlow models with TensorFlow Serve.
Mlflow Serve
Deploy Mlflow models with Mlflow Serve.