- Liveness probe: Checks whether the service’s replica is currently healthy. If the service is not healthy, the replica will be terminated and another one will be started.
- Readiness probe: Checks whether the service’s replica is ready to receive traffic. Until the readiness probe succeeds, no incoming traffic will be routed to this replica.
How to add Liveness and Readiness Probes to your deployed services
To add liveness and readiness probes to your deployed service, you will need to:- Create two endpoints in your service, one for the liveness probe and one for the readiness probe. The endpoints should return a successful response if the service is healthy and a failed response if the service is unhealthy.
- Configure your deployment to use the health check endpoints. You can do this via the user interface (UI) or via the Python SDK.
Example FastAPI health check endpoints
The following example shows two simple FastAPI health check endpoints/livez and /readyz that will be used by the Health Checks:
Configuring Health Check for your Service
Here are the parameters for liveness and readiness probes:| Parameter | Description |
|---|---|
| path | The path to the health check endpoint. |
| port | The port on which the health check endpoint is listening. |
| initial_delay_seconds | Number of seconds to wait after the container has started before checking the endpoint. |
| period_seconds | How often to check the endpoint. |
| timeout_seconds | Number of seconds to wait for a response from the endpoint before considering it to be down. |
| success_threshold | Number of times in a row the endpoint must respond successfully before the container is considered to be healthy. |
| failure_threshold | Number of times in a row the endpoint can fail to respond before the container is considered to be down. |
| Parameter | Value |
|---|---|
| path | /health |
| port | 8080 |
| initial_delay_seconds | 10 |
| period_seconds | 5 |
| timeout_seconds | 2 |
| success_threshold | 3 |
| failure_threshold | 2 |
Setting Liveness / Readiness Probes via the UI
Viewing health check logs
You can go to the Pods tab on the dashboard, and then click on the logs.
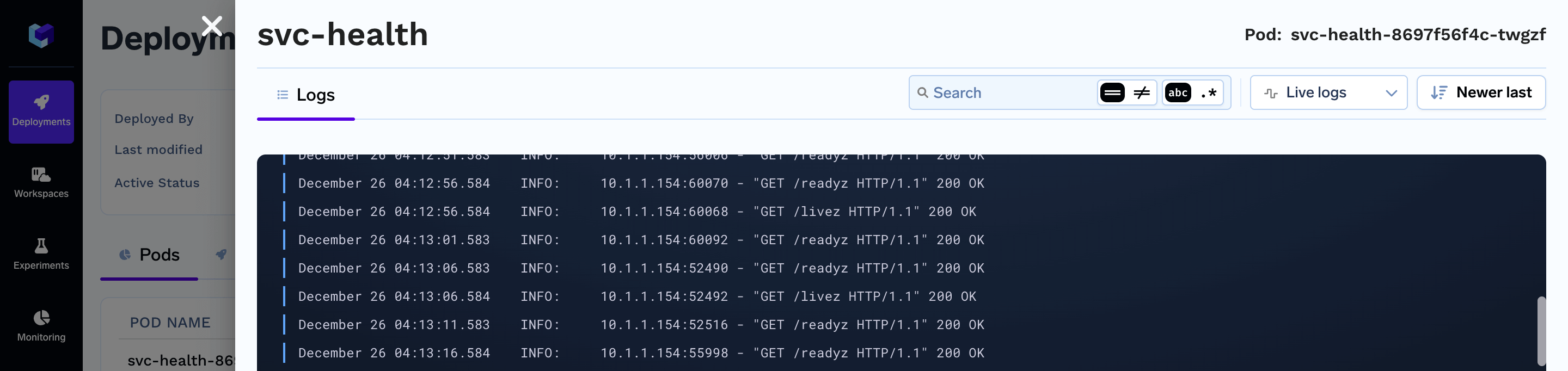
GET /livez and GET /readyz giving 200 OK messages indicate that the health checks are passing and that the service is healthy.