Deploy NIM Models from New Deployment MenuWhile this guide is useful to deploy any container image from NGC Catalog, if you are looking to deploy NIM Models, we have a dedicated deployment option for them. Please check Deploying NVIDIA NIM docs page
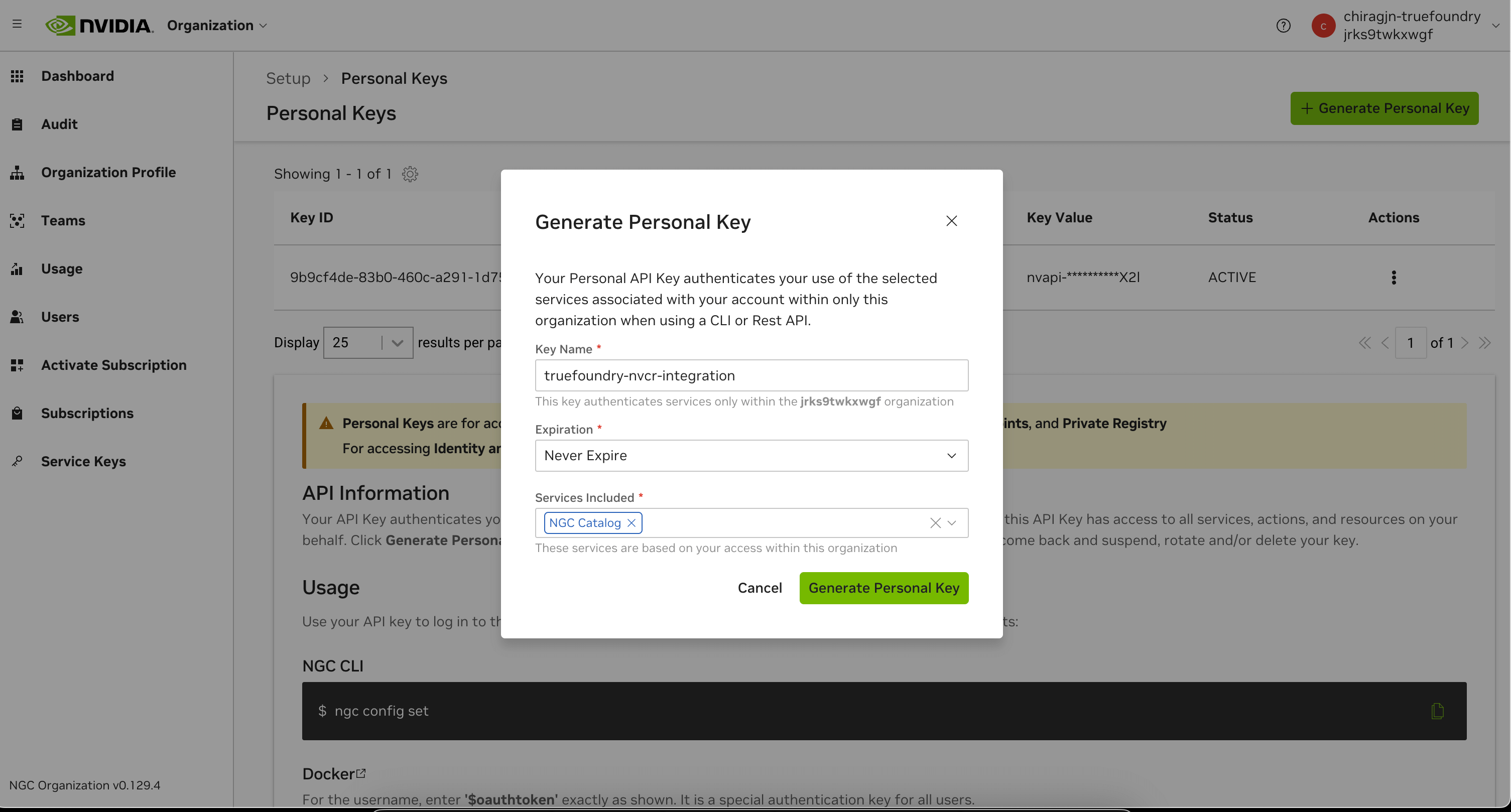
Create a NGC Personal Token
- Sign up at https://ngc.nvidia.com/
- Generate a Personal Key from https://org.ngc.nvidia.com/setup/api-keys
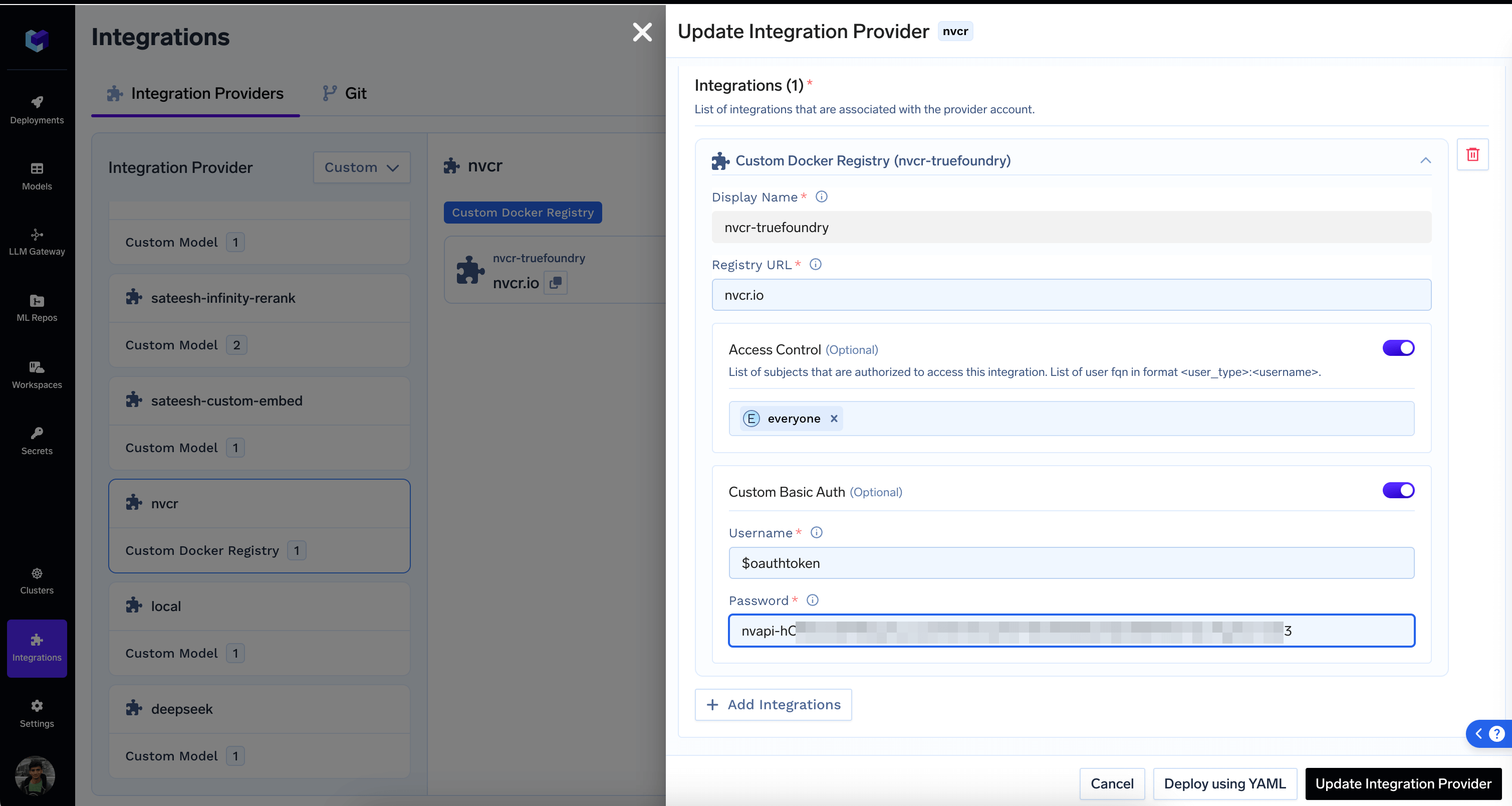
Add nvcr.io as Custom Docker Registry
- Under Integrations Tab, Click
+Add Integration Provideron top right - Under Integrations, select Custom Docker Registry and enter as follows:
- Registry URL:
nvcr.io - Username:
$oauthtoken - Password: Enter the Personal Token you created earlier
- Registry URL:
- Save
Use the Integration - E.g. Deploying Nvidia NIM Container
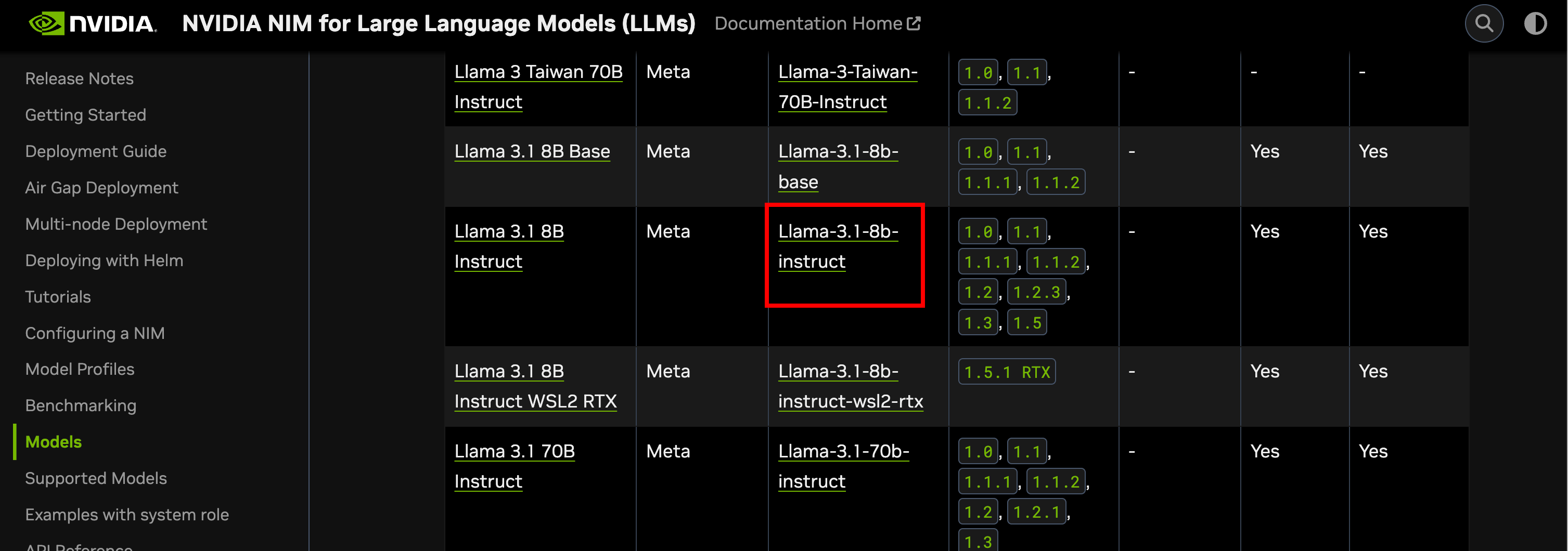
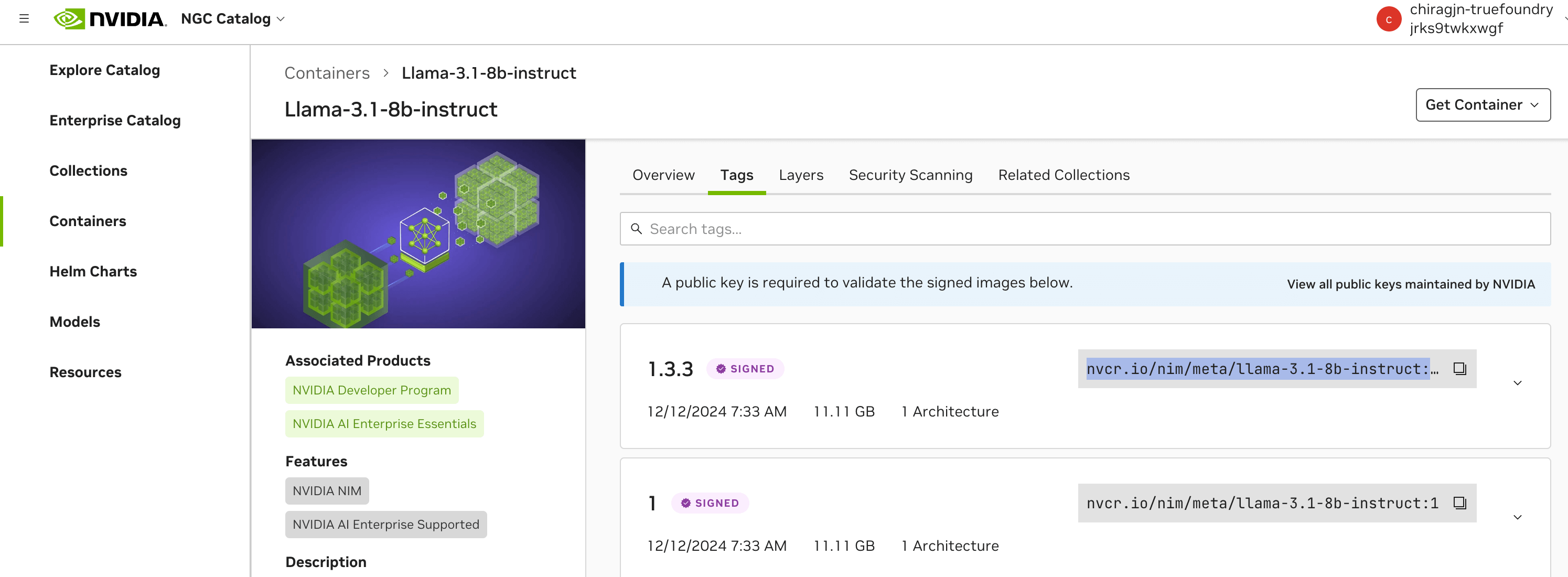
We can now deploy a Nvidia NIM LLM Container for Inference. You can find the list of all Supported Models from the docs page
- We will pick the Llama 3.1 8B Instruct model as an example. From the list of models page, click the NGC Catalog link
-
From the Container page, copy the image tag
-
Next, Start a new Service deployment on TrueFoundry
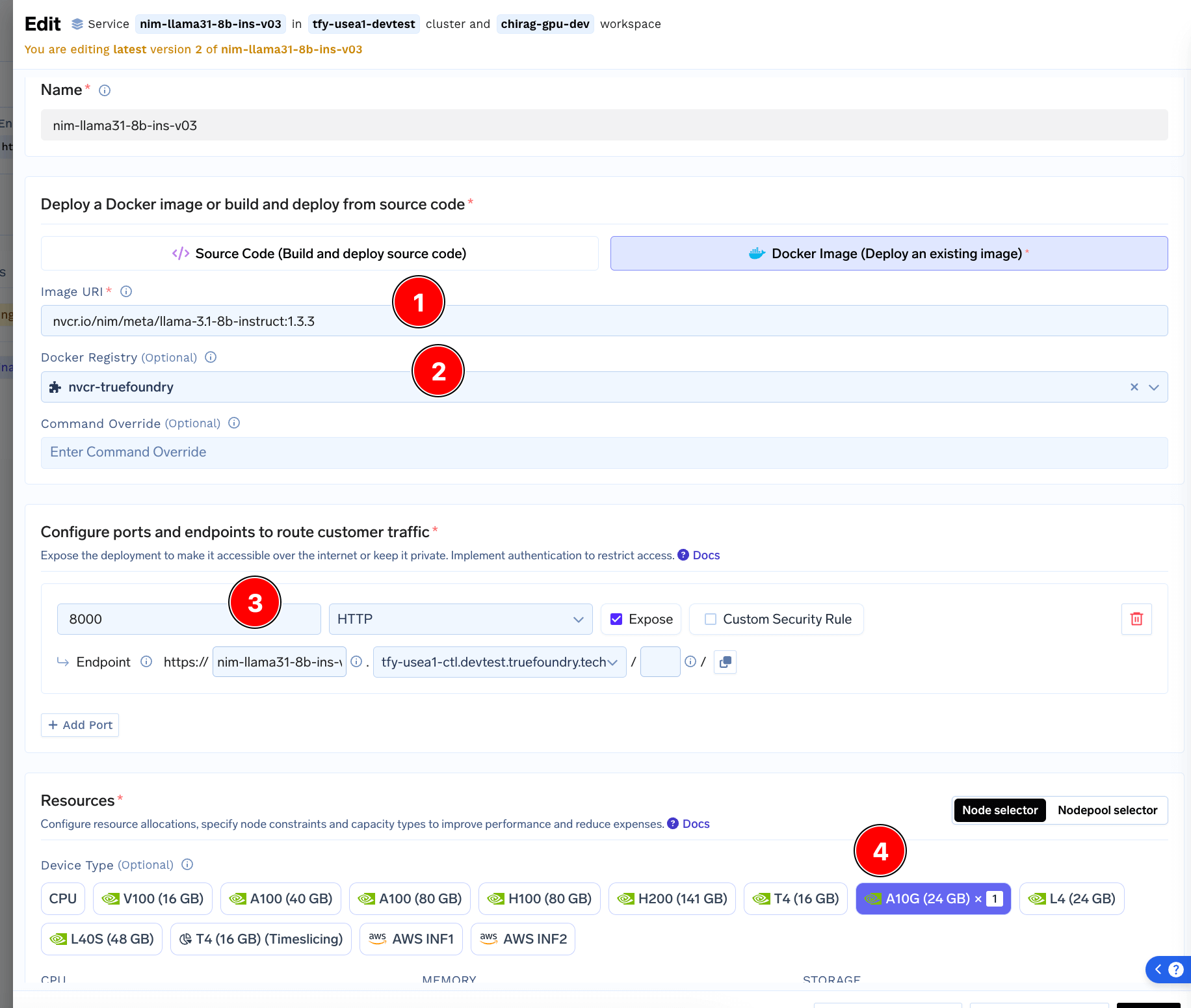
- In the Image Section, add the Image URI we copied from NGC Page
- Select the nvcr Docker Registry we added earlier
- Enter
8000for port - Select a GPU
- Optionally add Environment Variables (See Configuring NIM docs page)
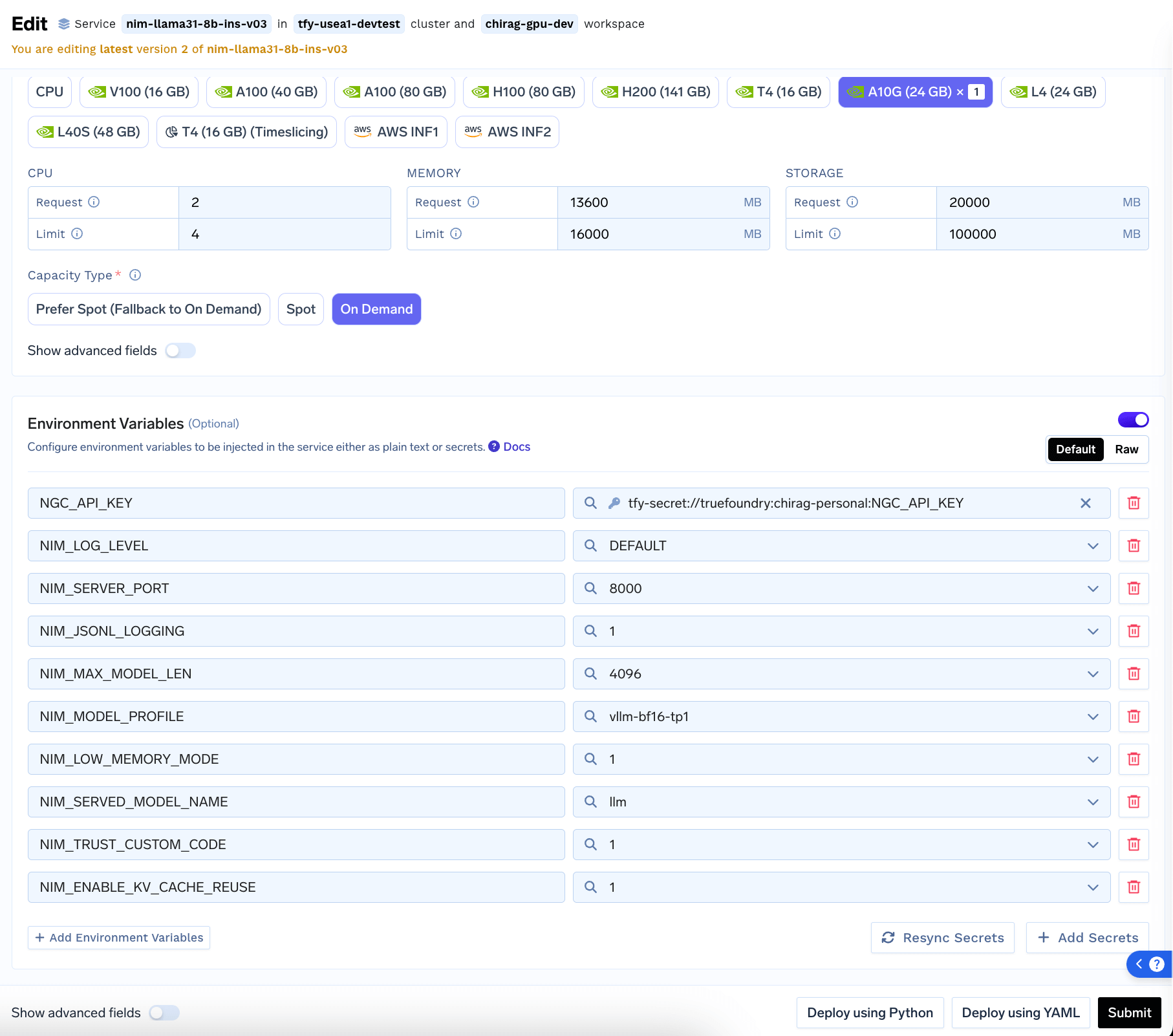
- Submit
-
Once Deployed and ready, you can visit
/docsroute on the endpoint to try it out\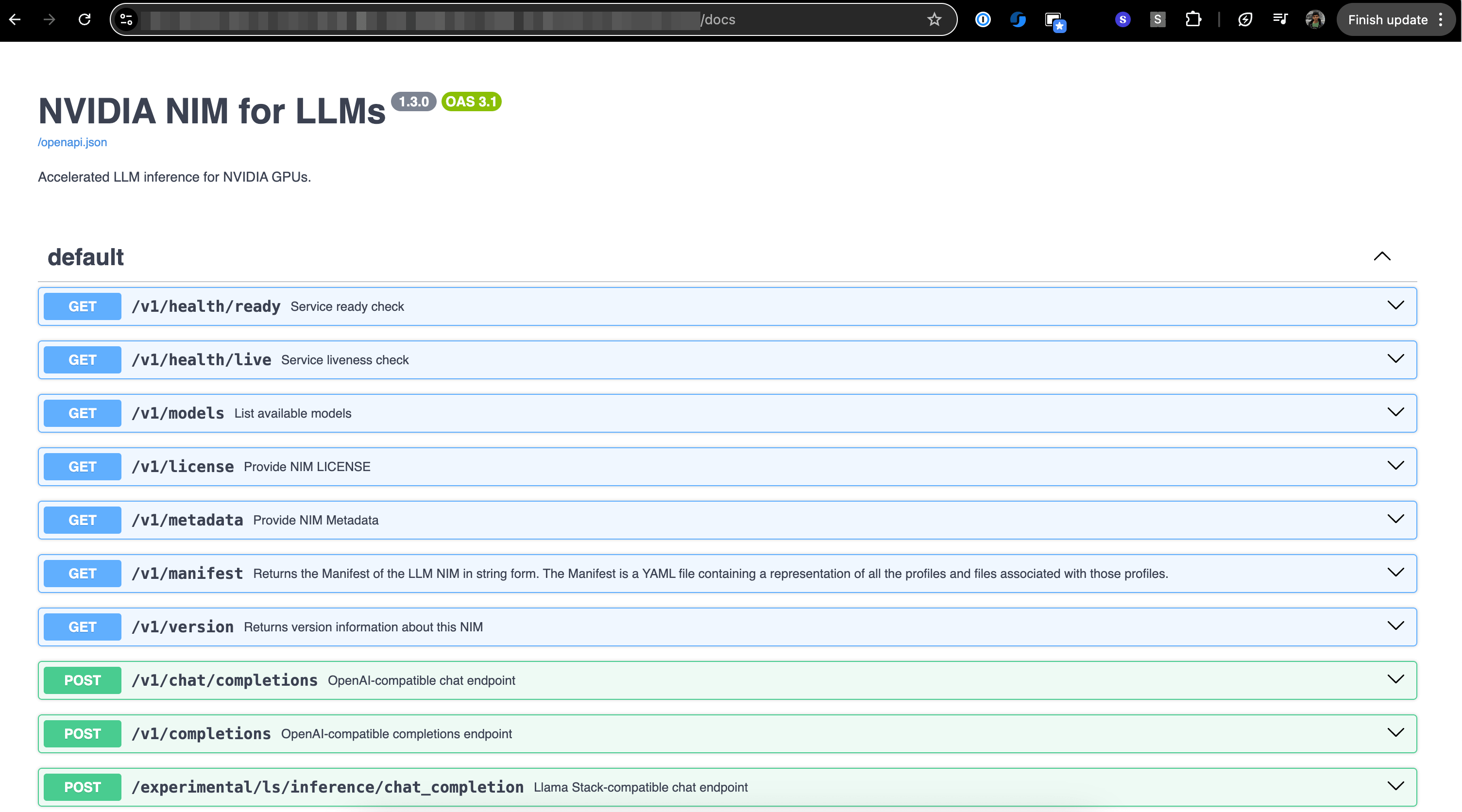
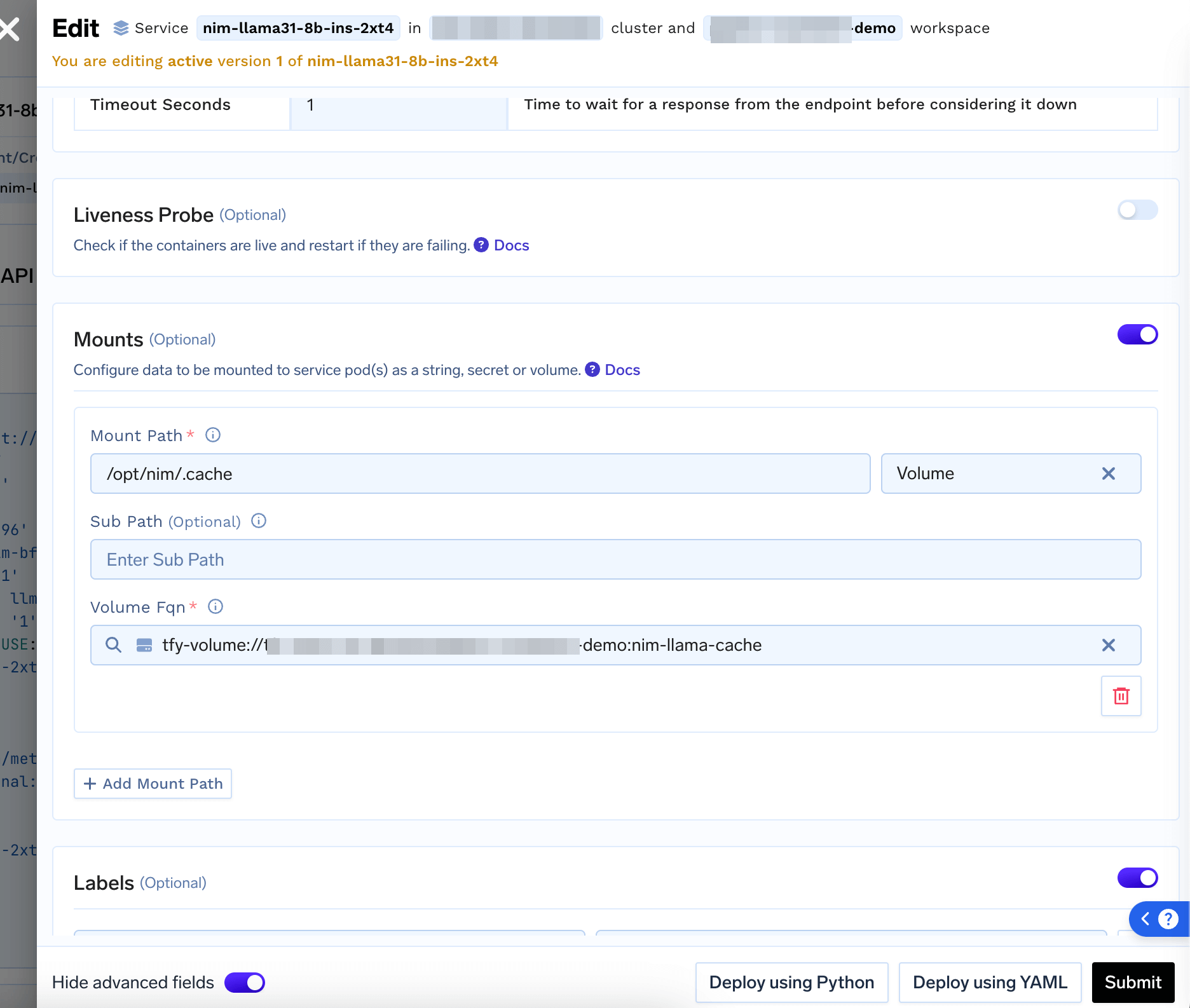
Model Caching using a Volume
To ensure fast startup , you can Create a Read Write Many Volume in the same workspace and mount the volume at/opt/nim/.cache (the value of NIM_CACHE_PATH environment variable) to cache the model weights.