Uploading files and directories as Models. Downloading models to disk.
Model comprises of model file/folder and some metadata. Each Model can have multiple versions. In essence they are just Artifacts with special type model
This is an example of storing an sklearn model. To log a model we start a run and then give our model a name and pass in the model saved on disk and the framework instance.
Copy
Ask AI
from truefoundry.ml import get_client, SklearnFramework, infer_signatureimport joblibimport numpy as npfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVCX = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])y = np.array([1, 1, 2, 2])clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))clf.fit(X, y)joblib.dump(clf, "sklearn-pipeline.joblib")client = get_client()client.create_ml_repo( # This is only required once name="my-classification-project", # This controls which bucket is used. # You can get this from Integrations > Blob Storage. storage_integration_fqn='<storage_integration_fqn>')model_version = client.log_model( ml_repo="my-classification-project", name="my-sklearn-model", description="A simple sklearn pipeline", model_file_or_folder="sklearn-pipeline.joblib", framework=SklearnFramework(), metadata={"accuracy": 0.99, "f1": 0.80},)print(model_version.fqn)
This will create a new model my-sklearn-model under the ml_repo and the first version v1 for my-sklearn-model.
Once created the model version files are immutable, only fields like description, framework, metadata can be updated using CLI or UI.
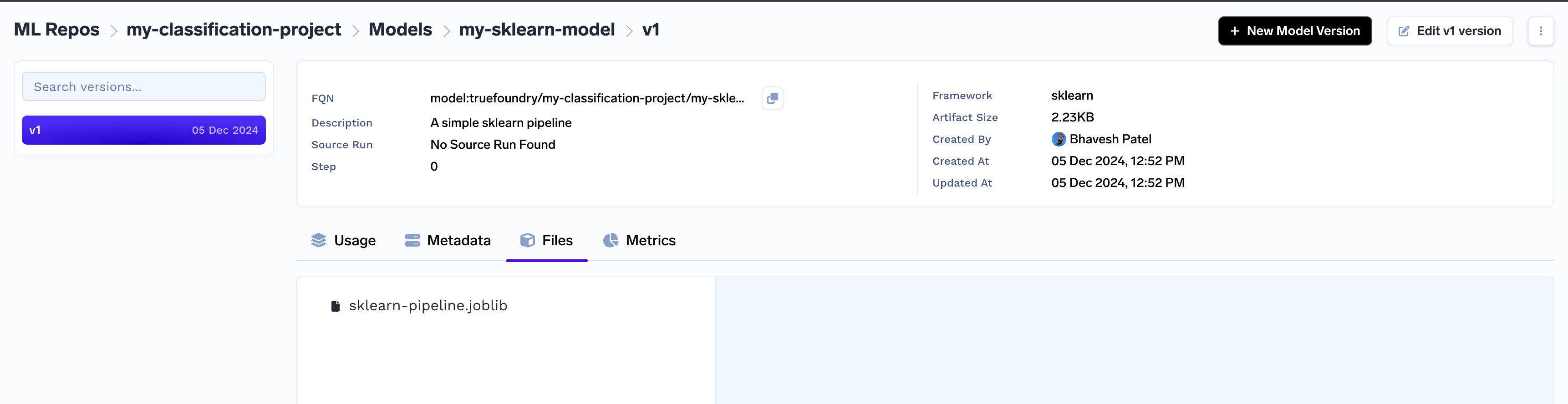
Once created, a model version has a fqn (fully qualified name) which can be used to retrieve the model later - E.g. model:truefoundry/my-classification-project/my-sklearn-model:1Any subsequent calls tolog_model with the same name would create a new version of this model - v2, v3 and so on.The logged model can be found in the dashboard in the Models tab under your ml_repo.
You can view the details of each model version from there on.
You can first get the model using the fqn and then download the logged model using the fqn and then use thedownload() function. From here on you can access the files at download_info.download_dir
Copy
Ask AI
import osimport tempfileimport joblibfrom truefoundry.ml import get_clientclient = get_client()model_version = client.get_model_version_by_fqn( fqn="model:truefoundry/my-classification-project/my-sklearn-model:1")# Download the model to disktemp = tempfile.TemporaryDirectory()download_info = model_version.download(path=temp.name)print(download_info.model_dir)# Deserialize and Loadmodel = joblib.load( os.path.join(download_info.model_dir, "sklearn-pipeline.joblib"))
You may want to update fields like description, framework, metadata on an existing model version.
You can do so with the .update() call on the Model Version instance. E.g.
Copy
Ask AI
from truefoundry.ml import get_client, SklearnFrameworkclient = get_client()model_version = client.get_model_version_by_fqn( "model:truefoundry/my-classification-project/my-sklearn-model:1")model_version.description = "This is my updated description"model_version.metadata = {"accuracy": 0.98, "f1": 0.85}model_version.framework = SklearnFramework( model_filepath="sklearn-pipeline.joblib", serialization_format="joblib")# Updates the model fields for existing model version.model_version.update()