1. Add the cloud specific code access the service in your code
- AWS
- GCP
- Azure
2. Authenticate your service to access the cloud service
We need to provide the correct credentials to our code so that it can authenticate and connect to the cloud services. The exact approach depends on the cloud provider. Here’s how you can do it for the most common cloud providers:- AWS
- GCP
- Azure
There are two ways to authenticate your service to access AWS services:
The value of OIDC_ISSUER_URL will be the OIDC provider URL. It will be something like:
1. Access Key and Secret Access Key
This involves setting theAWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables. AWS SDKs will automatically pick these up from the environment variables and authenticate with the corresponding AWS service. The accesskey and secretaccesskey can be found in the AWS console and can be generated by your Infra team.2. IAM Role-Based Access through Service Account (Recommended)
This approach typically involves creating IAM roles, associating them with Kubernetes service accounts, and configuring your deployments to use those service accounts. Here’s a detailed breakdown:Key Concepts- Kubernetes Service Accounts (SA): These are identities for processes running inside a pod. They provide a way to authenticate your pods with other Kubernetes services and external resources.
- IAM Roles: IAM roles are sets of permissions that define what actions an AWS entity (like a user, application, or service) can perform.
- IAM Roles for Service Accounts (IRSA): This is the key technology that allows you to map a Kubernetes service account to an IAM role. It uses AWS’s OpenID Connect (OIDC) provider capability.
How to create an IAM role and service account?
How to create an IAM role and service account?
1
Get cluster and accountdetails
We will need the name of the cluster, AWS account ID, region, namespace (workspace in Truefoundry) in which the application is to be deployed. Set the following variables:
2
Get Cluster's OIDC Provider URL
oidc.eks.YOUR_REGION.amazonaws.com/id/YOUR_OIDC_ID3
Create an IAM Policy
Create an IAM policy with the required permissions. This example grants full access to S3. It’s strongly recommended to scope down the permissions to only what’s necessary for security best practices.Replace your-bucket-name with the actual name of your S3 bucket. You can also use wildcards to specify multiple buckets or prefixes within a bucket.Create the policy using the AWS CLI:
s3-access-policy.json
4
Create an IAM Role
Create the assume role policy file.Create an IAM role using this assume role policy:
5
Attach the IAM Policy to the Role
6
Create and Apply the Kubernetes Service Account
Create a Kubernetes service account in your desired namespace. You can apply this either via Kubectl or using the Truefoundry UI.This is a simple YAML file (e.g., Apply using Kubectl:or using the Truefoundry UI:TODO: Add supademo link here
service-account.yaml):service-account.yaml
7
Verify the Service Account
Run a pod and test if you are able to perform operations on the AWS S3 bucketKubectl exec into the pod and test if you are able to perform operations on the AWS S3 bucketRun the command
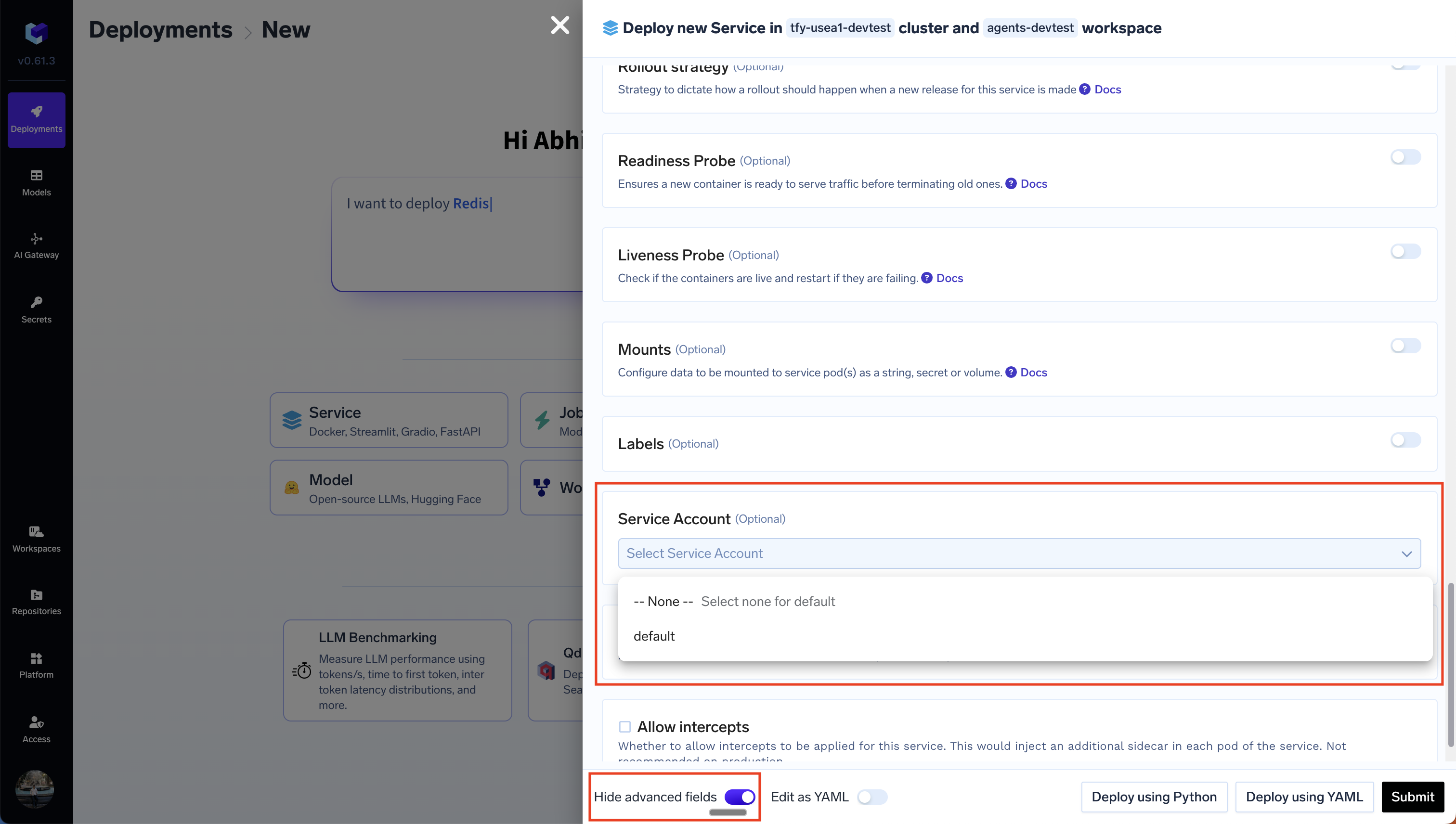
aws s3 ls to verify if you are able to access the S3 bucket.3. Select the service account for the service
Once you’ve configured the Service Account in Kubernetes following the steps above, you can select the service account for the service in the Truefoundry UI. This can be viewed after switching on the advanced options in the service deployment form.