- The docker image size can become huge if the model file is big.
- We will need to rebuild the docker image if the model file changes.
- Every time the pod needs to come up on a new machine, it will end up downloading the model file again.
- In this case, every time a pod comes up, we need to download the model first which leads to high startup time.
- It also means more networking costs every time the models are downloaded.
- Smaller docker image size leads to faster startup
- Faster loading of models from volume leads the faster startup times
- Cost savings because of not having to download the model repeatedly.
- Upgrading requires manual intervention of having to download the new version of the model on the volume.
- If we swap the older model on the volume with the newer model, and a pod restarts just after that, it will lead to one pod using the newer version of the model, even though we haven’t started the deployment process.
Artifacts Download feature in TrueFoundry which automatically provisions a volume, downloads the model onto the volume, mounts the volume and also handles upgrades safely. The way this works during the first deployment is:

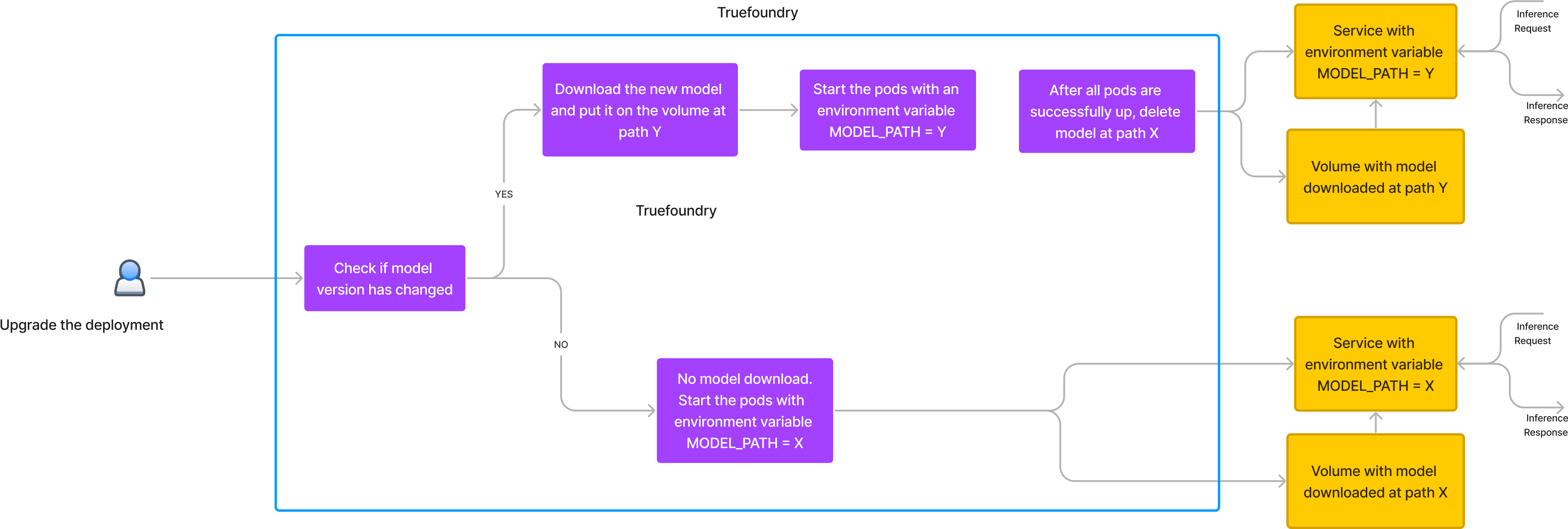
Using Artifact Download Feature to cache models
Using the Cached Model
In your Service code, to use the cached model, you can utilize theDownload Path Environment Variable you specified while configuring the Download and Cache Artifact.
You can do one of these two things, Get it directly in your code using os.environ.get() or Pass it as a command-line argument if your service needs it that way.
-
Read the download path from environment variable
MODEL_ID_1 as theDownload Path Environment Variable, to download model.joblib file, you can access the cached model like this:
-
Pass the download path as a command-line argument
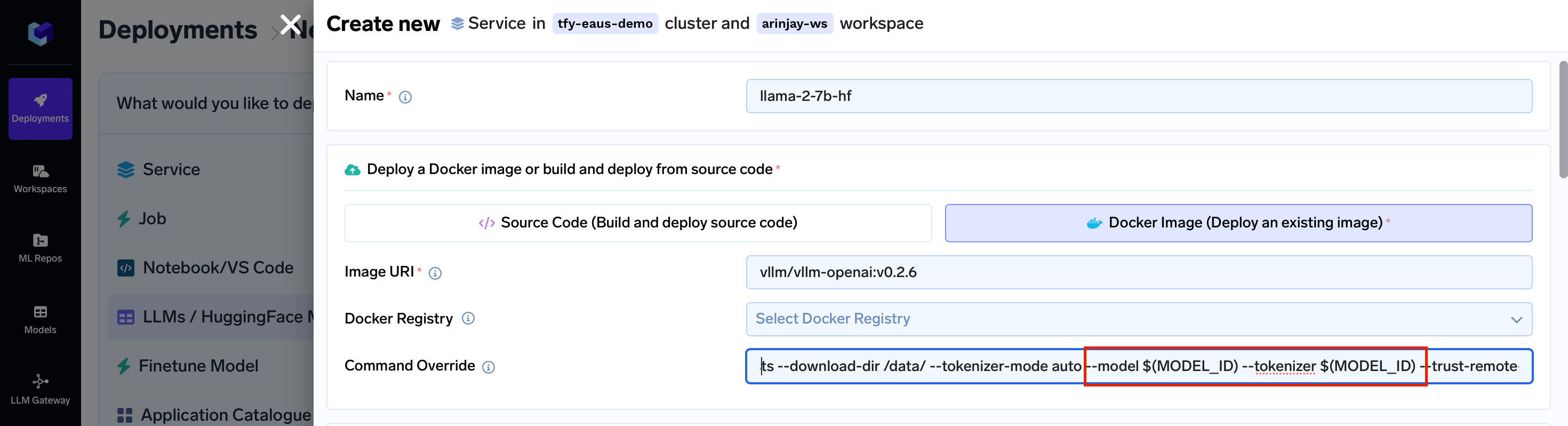
vllm/vllm-openai:v0.2.6 docker image. The following takes the model and tokenizer as a command-line argument.
You can pass the Download Path Environment Variable in the arguments.