Fallback
Fallback a request to another model on failure from one model
Fallback allows users to configure fallback models in case failures happen for certain models. This is useful specially in cases, where we have the same model from multiple providers and we want to fallback to the other provider in case one provider is down or has rate limits. It helps provide higher reliability to end users.
The fallback configuration contains an array of rules. Every request is evaluated against the set of rules and only the first matching rule is evaluated - the subsequent rules are ignored.
For each rule, we have three sections:
- when
- subjects: An array of user or teams from which requests is originated - for e.g. user:[email protected], team:team1
- models: An array of model ids which will be used to filter the requests. The model ids are the same as what we pass in the model field in the request.
- metadata
- response_status_codes: The response status on which the fallbacks will be executed. This is important since we only want to retry on recoverable errors codes like rate limit exceeded (429), etc.
- fallback_models:
- target: The model ID to which traffic should be routed
- override_params (optional): A key-value object used to modify or extend the request body when falling back to the target model. Each key corresponds to a parameter name, and the associated value specifies what should be sent to the target. This allows you to override existing parameters from the original request or introduce entirely new ones, enabling flexible customization for each target model during fallback.
Let's say you want to setup fallback based on following rules:
- Fallback to gpt-4 of azure, aws if openai-main/gpt-4 fails with 500 or 503. The azure target also overrides a few request parameters like temperature and max_tokens.
- Fallback to llama3 of azure, aws if bedrock/llama3 fails with 500 or 429 for customer1.
Your fallback config would look like this:
name: model-fallback-config
type: gateway-fallback-config
# The rules are evaluated in order and once a request matches one rule,
# the subsequent rules are not checked
rules:
# Fallback to gpt-4 of azure, aws if openai-main/gpt-4 fails with 500 or 503. The openai-main target also overrides a few request parameters like temperature and max_tokens
- id: "openai-gpt4-fallback"
when:
models: ["openai-main/gpt4"]
response_status_codes: [500, 503]
fallback_models:
- target: openai-main/gpt-4
override_params:
temperature: 0.9
max_tokens: 800
# Fallback to llama3 of azure, aws if bedrock/llama3 fails with 500 or 429 for customer1.
- id: "llama-bedrock-customer1-fallback"
when:
models: ["bedrock/llama3"]
metadata:
customer-id: customer1
response_status_codes: [500, 429]
fallback_models:
- target: aws/llama3
- target: azure/llama3
Configure Fallback on Gateway
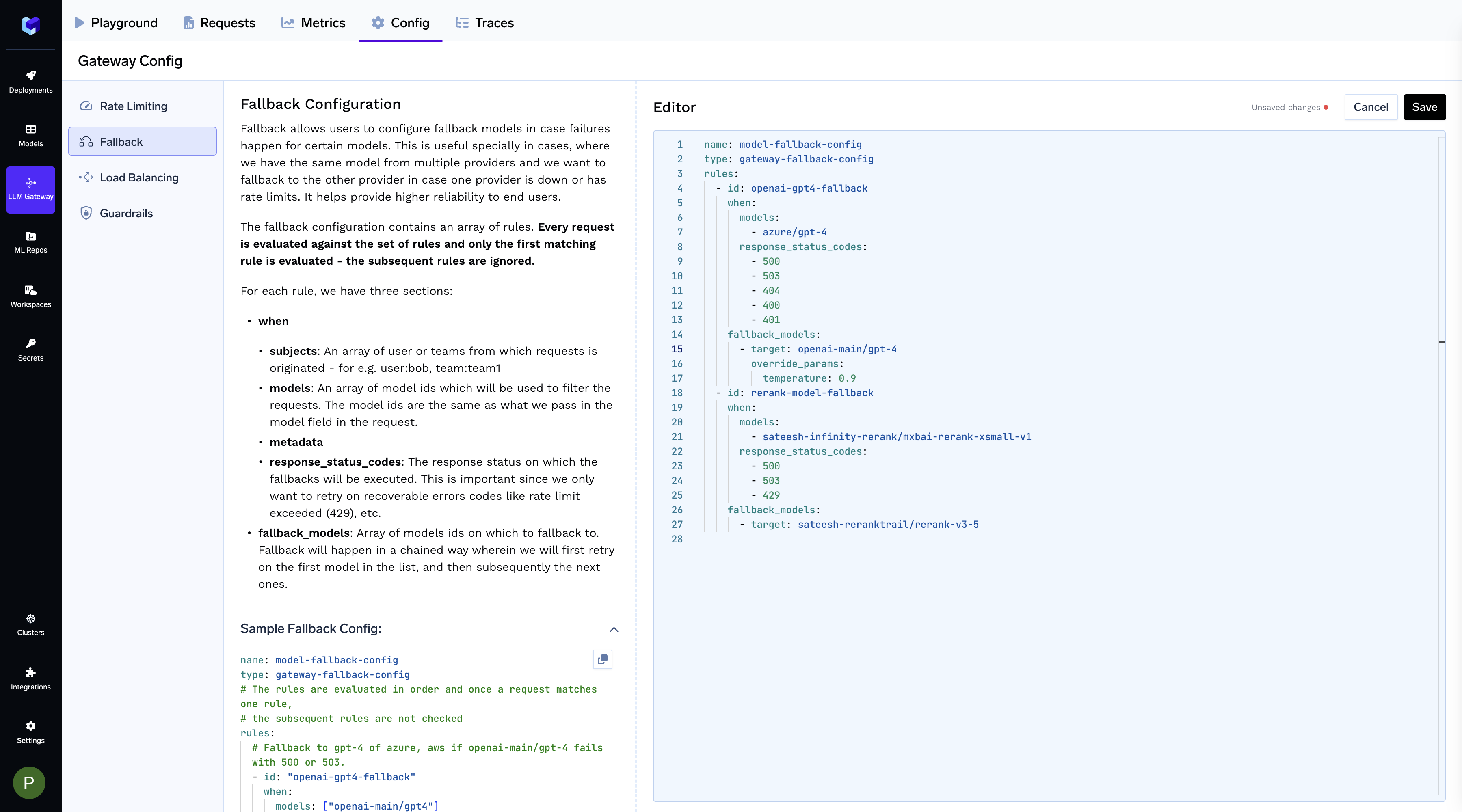
It's straightforward—simply go to the Config tab in the Gateway, add your configuration, and save.
Updated 7 days ago