Tracing
TrueFoundry offers robust monitoring for applications by collecting traces, metrics, and logs to deliver real-time insights into performance, efficiency, and cost. At its core, TrueFoundry has built its own tracing solution based on the OpenTelemetry (OTel) standard, ensuring compatibility and flexibility.
While TrueFoundry does not rely on Traceloop, we recommend using the Traceloop client SDK to push traces, as it supports a wide range of modes and provides a seamless developer experience for AI and LLM-based applications.
Key Concepts
Trace
A trace would represent the complete lifecycle of a request or task as it flows through the various services and components that interact with the LLM. This could involve multiple stages, such as receiving input from the user, sending the input to the model for inference, processing the model’s output, and delivering the result back to the user.
The trace provides a holistic view of how the LLM application processes the request and where any delays or issues may arise in the overall flow, whether it's the input, the model's computation, or the output handling.
Span
A span represents an individual unit of work or operation that occurs within the trace. In the context of an LLM application, spans are used to capture each distinct task or action that is performed during the lifecycle of a request.
Each span provides granular insights into specific stages of the request lifecycle, and together they allow you to understand not only how the LLM system performs overall but also where performance optimizations or troubleshooting may be needed in individual components or operations.
For Example:
Imagine a user queries an LLM for a recommendation. The trace would look something like this:
- Trace: Tracks the entire user request from input to response.
- Span 1: Input preprocessing (parsing and tokenizing the user query).
- Span 2: Model inference (running the LLM to generate a recommendation).
- Span 3: Post-processing (formatting the recommendation output).
- Span 4: Output delivery (returning the recommendation to the user).
By using traces and spans in LLM applications, you gain end-to-end visibility of how well your LLM-based system is performing, where the bottlenecks might be, and how to improve the efficiency and responsiveness of the system.
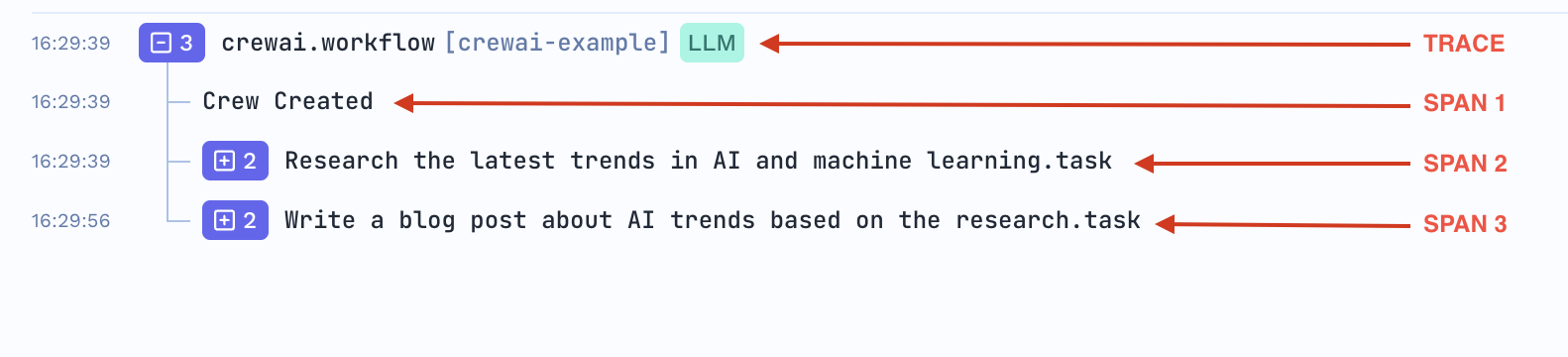
TrueFoundry's Tracing UI
Getting Started [Supported Providers & Frameworks]
If you are using any of the supported Providers and Frameworks then adding tracing is pretty simple. You just need to install, import and initialise the Traceloop SDK. It will automatically log traces your requests.
Say for example you are using OpenAI client the follow these steps:
lnstall dependencies:
First, you need to install the following
pip install traceloop-sdk==0.38.12Setup environment variables:
Add the necessary environment variables to enable tracing
OPENAI_API_KEY=sk-proj-*
TRACELOOP_BASE_URL=<<control-plane-url>>/api/otel
TRACELOOP_HEADERS="Authorization=Bearer <<api-key>>Generate API key from here
OpenAI Completion Example
from openai import OpenAI
#Import Traceloop SDK
from traceloop.sdk import Traceloop
api_key = "Enter your API Key here"
#Initialise the Traceloop SDK
Traceloop.init(
app_name="openai-example",
disable_batch=True, #This is recommended, only if you are trying this in local machine. This helps to push the traces immediately, without waiting for batching
)
client = OpenAI(api_key=api_key, base_url="https://internal.devtest.truefoundry.tech/api/llm/api/inference/openai")
stream = client.chat.completions.create(
messages = [
{"role": "system", "content": "You are an AI bot."},
{"role": "user", "content": "Enter your prompt here"},
],
model= "openai-main/gpt-4o",
stream=True,
temperature=0.7,
max_tokens=256,
top_p=0.8,
frequency_penalty=0,
presence_penalty=0,
stop=["</s>"],
extra_headers={
"X-TFY-METADATA": '{"tfy_log_request":"true"}'
}
)
for chunk in stream:
if chunk.choices and len(chunk.choices) > 0 and chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Logged trace on TrueFoundry UI:
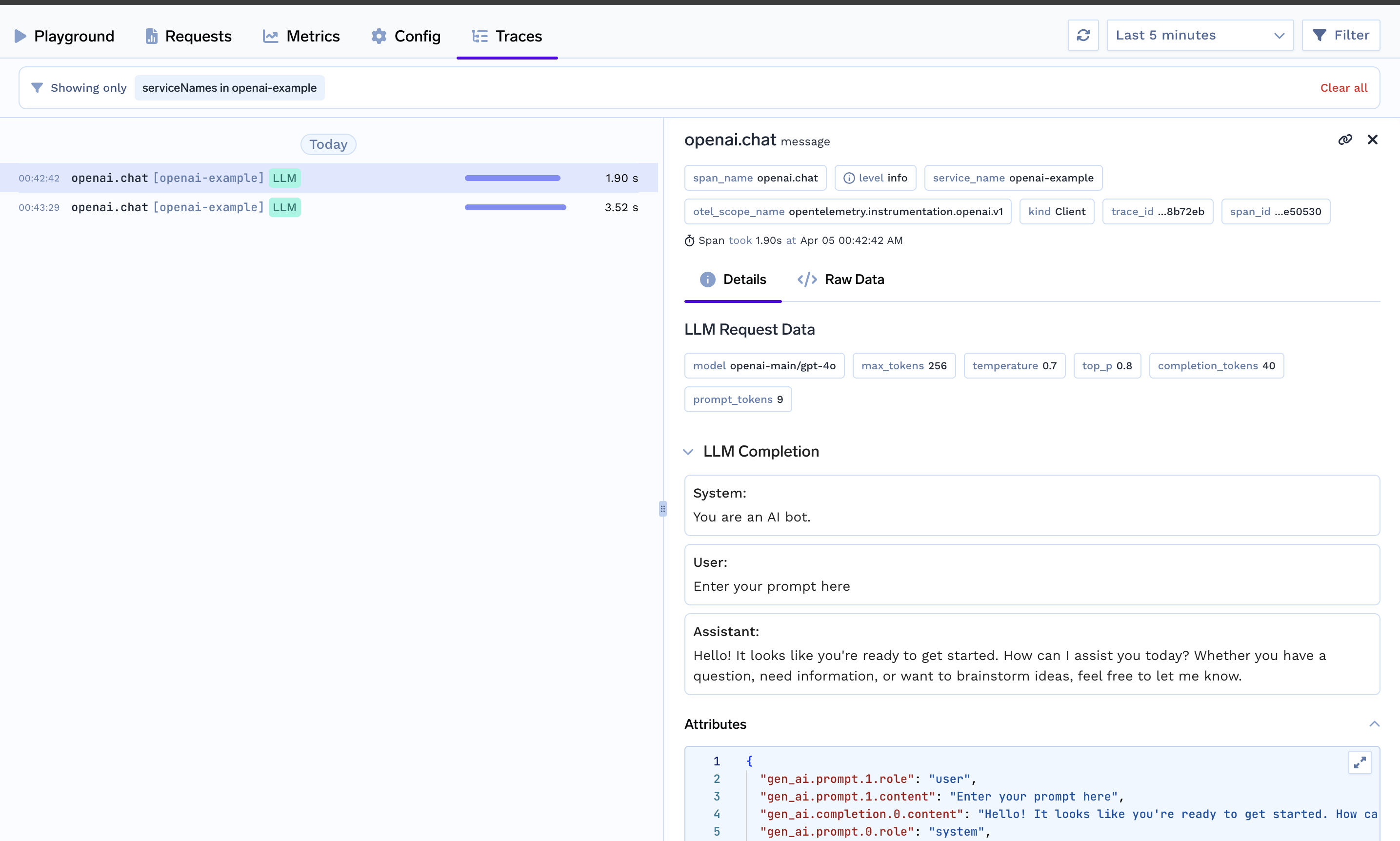
If you want are using any of the following frameworks then follow these:
Getting Started [Non-Supported Providers & Frameworks]
Can you still log traces on TrueFoundry even if you are not using any of the supported provider or framework? YES!
Follow these steps and get instant monitoring:
lnstall dependencies:
First, you need to install the following
pip install traceloop-sdk==0.38.12Setup environment variables:
Add the necessary environment variables to enable tracing
OPENAI_API_KEY=sk-proj-*
TRACELOOP_BASE_URL=<<control-plane-url>>/api/otel
TRACELOOP_HEADERS="Authorization=Bearer <<api-key>>Generate API key from here
Initialise Traceloop
In your LLM app, initialize the Traceloop tracer like this:
from traceloop.sdk import Traceloop
Traceloop.init()
Traceloop.init(disable_batch=True) #This is recommended, only if you are trying this in local machine. This helps to push the traces immediately, without waiting for batchingAnnotate your Workflows, Agents and Tools
For complex workflows or chains, annotating them can help you gain better insights into their operations. With TrueFoundry, you can view the entire trace of your workflow for a comprehensive understanding.
Traceloop offers a set of decorators to simplify this process. For instance, if you have a function that renders a prompt and calls an LLM, you can easily add the @workflow decorator to track and annotate the workflow. Let's say your workflow calls more functions you can annotate them as @task
from openai import OpenAI
from traceloop.sdk.decorators import workflow, task
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
(name="joke_creation")
def create_joke():
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Tell me a joke about opentelemetry"}],
)
return completion.choices[0].message.content
(name="signature_generation")
def generate_signature(joke: str):
completion = openai.Completion.create(
model="davinci-002",[]
prompt="add a signature to the joke:\n\n" + joke,
)
return completion.choices[0].text
(name="pirate_joke_generator")
def joke_workflow():
eng_joke = create_joke()
pirate_joke = translate_joke_to_pirate(eng_joke)
signature = generate_signature(pirate_joke)
print(pirate_joke + "\n\n" + signature)Similarly, when working with autonomous agents, you can use the @agent decorator to trace the agent as a single unit. Additionally, each individual tool within the agent should be annotated with the @tool decorator.
from openai import OpenAI
from traceloop.sdk.decorators import agent, tool
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
(name="joke_translation")
def translate_joke_to_pirate(joke: str):
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": f"Translate the below joke to pirate-like english:\n\n{joke}"}],
)
history_jokes_tool()
return completion.choices[0].message.content
(name="history_jokes")
def history_jokes_tool():
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": f"get some history jokes"}],
)
return completion.choices[0].message.contentUpdated 1 day ago