Deploy a LLM (Llama 2 7B Chat) with Huggingface Text-Generation-Inference
Advanced Guide
This guide is generally meant for advanced usage and involves more steps but also provides more configuration flexibility. For quick start, we recommend Deploying using the Model Catalogue
Huggingface TGI enables high throughput LLM inference using a variety of techniques like Continuous Batching, Tensor Parallelism, FlashAttention, PagedAttention and custom kernels. It also supports running quantized models with GPTQ and bitsandbytes.
In this guide, we will deploy NousResearch/Llama-2-7b-chat-hf
Compatibility
Model ArchitecturesTGI is still relatively a new project and under active development. As such when new models with new architectures or techniques are released it might take a while for them to land in TGI.
TGI has a list of officially supported architectures - These architectures are optimized for inference. All other architectures are supported on a best effort basis without special optimisations like flash attention, tensor parallelism, etc.
This also means different models would need different minimum version of TGI
Hardware
- Since v0.9.3, TGI uses FlashAttention v2 which is only supported Ampere and newer Nvidia GPUs
- For older versions, TGI uses FlashAttention v1 which is only supported Turing and newer Nvidia GPUs
- FlashAttention can be disabled by setting
USE_FLASH_ATTENTION=Falsein environment but it reduces the gains from continuous batching and some architectures only support sharding across GPUs with FlashAttention
License change since TGI 1.x
Since version 1.0 TGI switched to a custom license
HFOIL. Please review the license and the following links before making a decision:
- https://github.com/huggingface/text-generation-inference/releases/tag/v1.0.0
- https://github.com/huggingface/text-generation-inference/issues/726
- https://github.com/huggingface/text-generation-inference/issues/744
In such cases we recommend either using TGI up to version 0.9.4 or using vLLM
Deploying using UI
On the Deployments Page, click New Deployment on the top right and select a workspace
New Deployment on the top right and select a workspace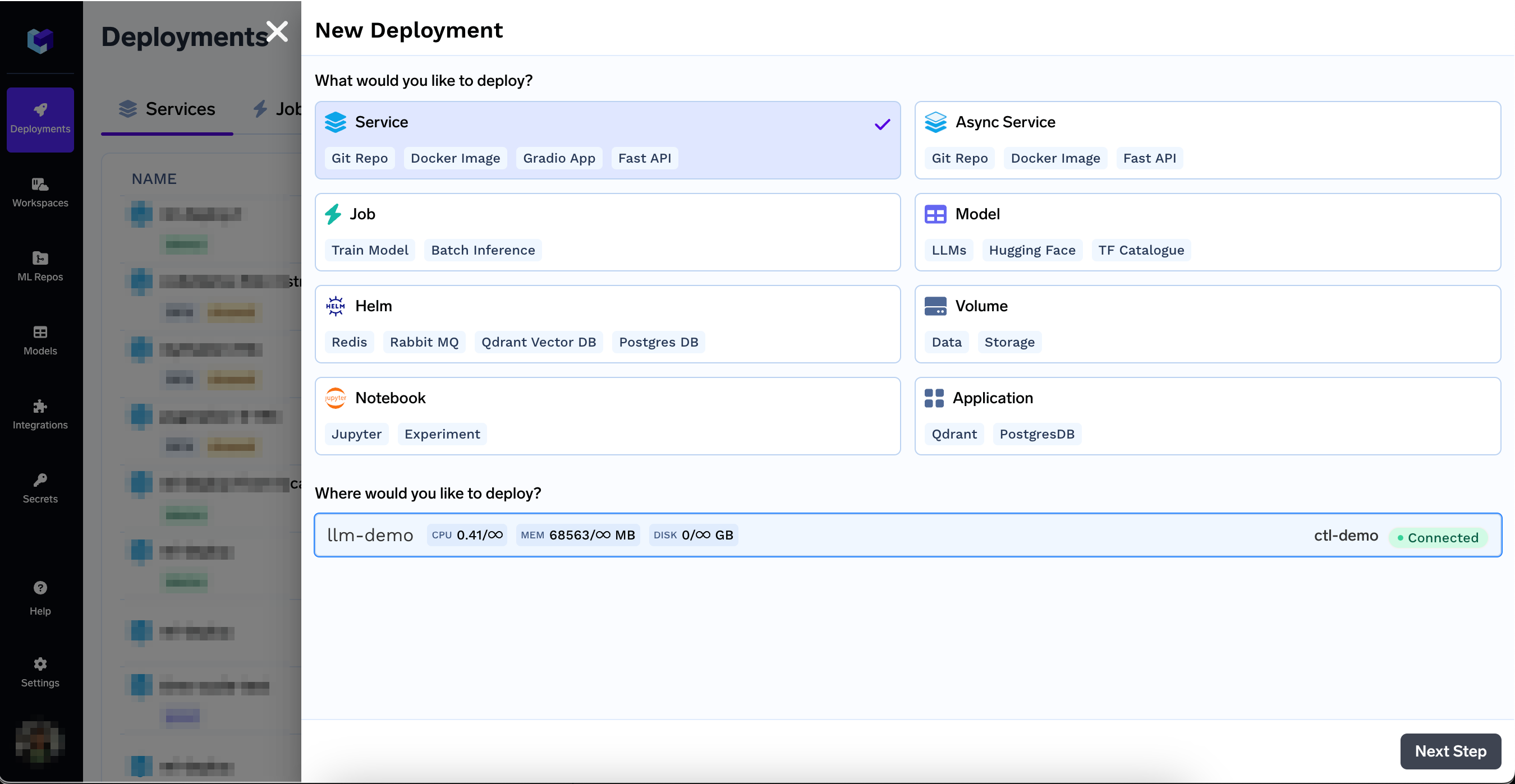
Configure Name, Build Config and Port
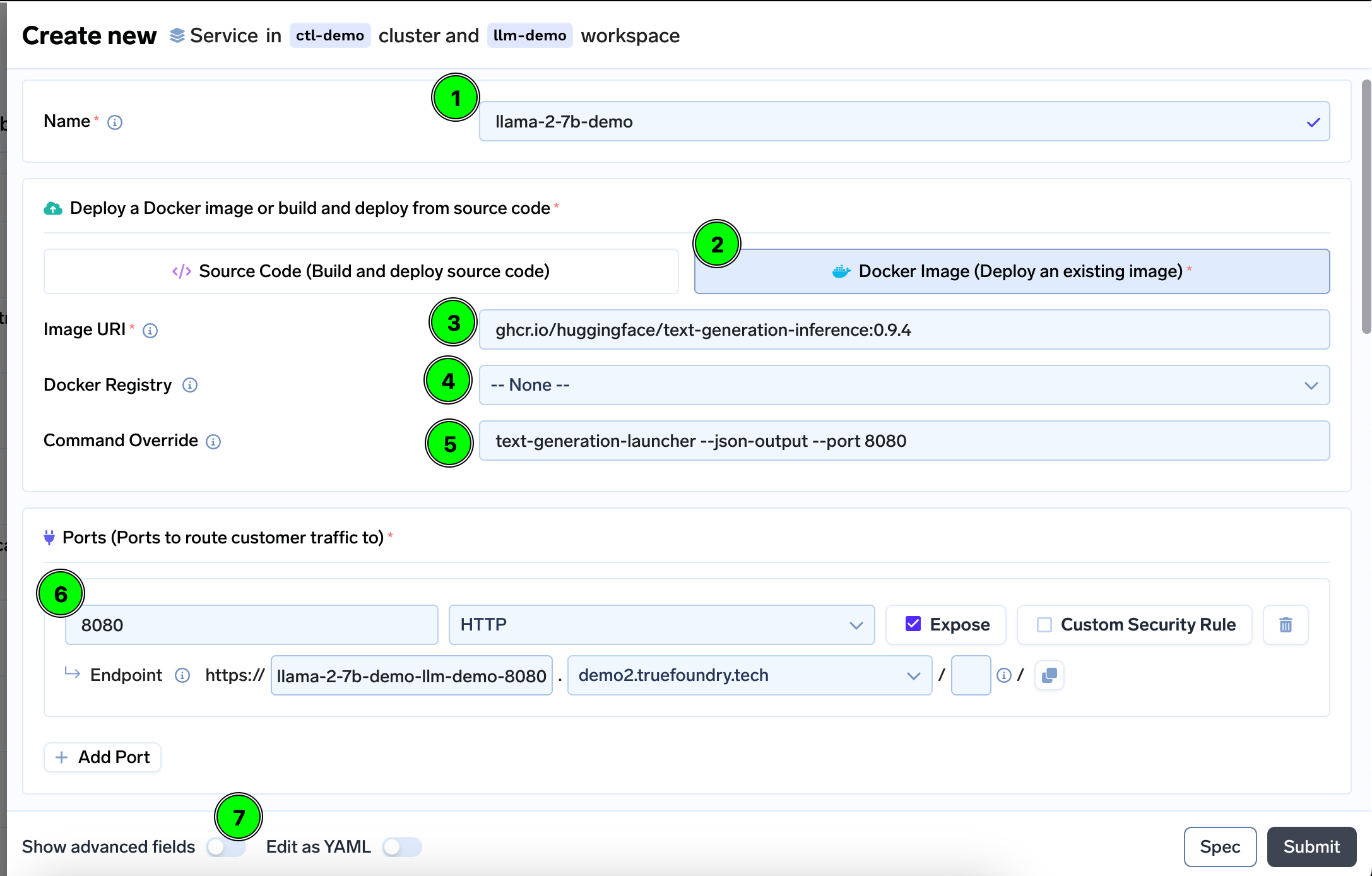
- Add a Name
- Select Docker Image
- Enter Image URI as
ghcr.io/huggingface/text-generation-inference:0.9.4. As mentioned earlier, you might want to try out a newer version (e.g.ghcr.io/huggingface/text-generation-inference:latest) if your model needs bleeding edge features. - Make sure the Docker Registry is
--None-- - Enter Command as
text-generation-launcher --json-output --port 8080 - Enter Port as
8080 - Before moving forward enable the
Show advanced fields
Decide which GPU to Use
Before we configure other options, it is essential to decide which GPU and how many GPU cards you want to use. The choice depends on the number of parameters in your model, precision (16-bit, 8-bit, 4-bit) and how large of a batch you want to run. In addition to this, each token to be processed/generated needs GPU memory to hold attention KV Cache. This means to fit more tokens across multiple requests more GPU memory is needed.
In this example for Llama 2 7B, we are going to run at 16-bit precision. This means that just to load the model we need 14 GB (7 x 1e9 x 2 bytes) GPU memory. While it can fit within 1 x T4 GPU (16 GB), for higher throughput it would be advisable to choose one of 1 x A10 GPU (24 GB) / 1 x L4 GPU (24 GB) / 1 x A100 (40 GB) / 1 x A100 GPU (80 GB).
Similarly for Llama 2 13B ... 👇
It would be advisable to choose one of 2 x A10 GPU (24 GB) / 2 x L4 GPU (24 GB) / 1 x A100 (40 GB) / 1 x A100 GPU (80 GB).
See Adding GPUs to Applications page for a list of gpus and their details. Also see Appendix
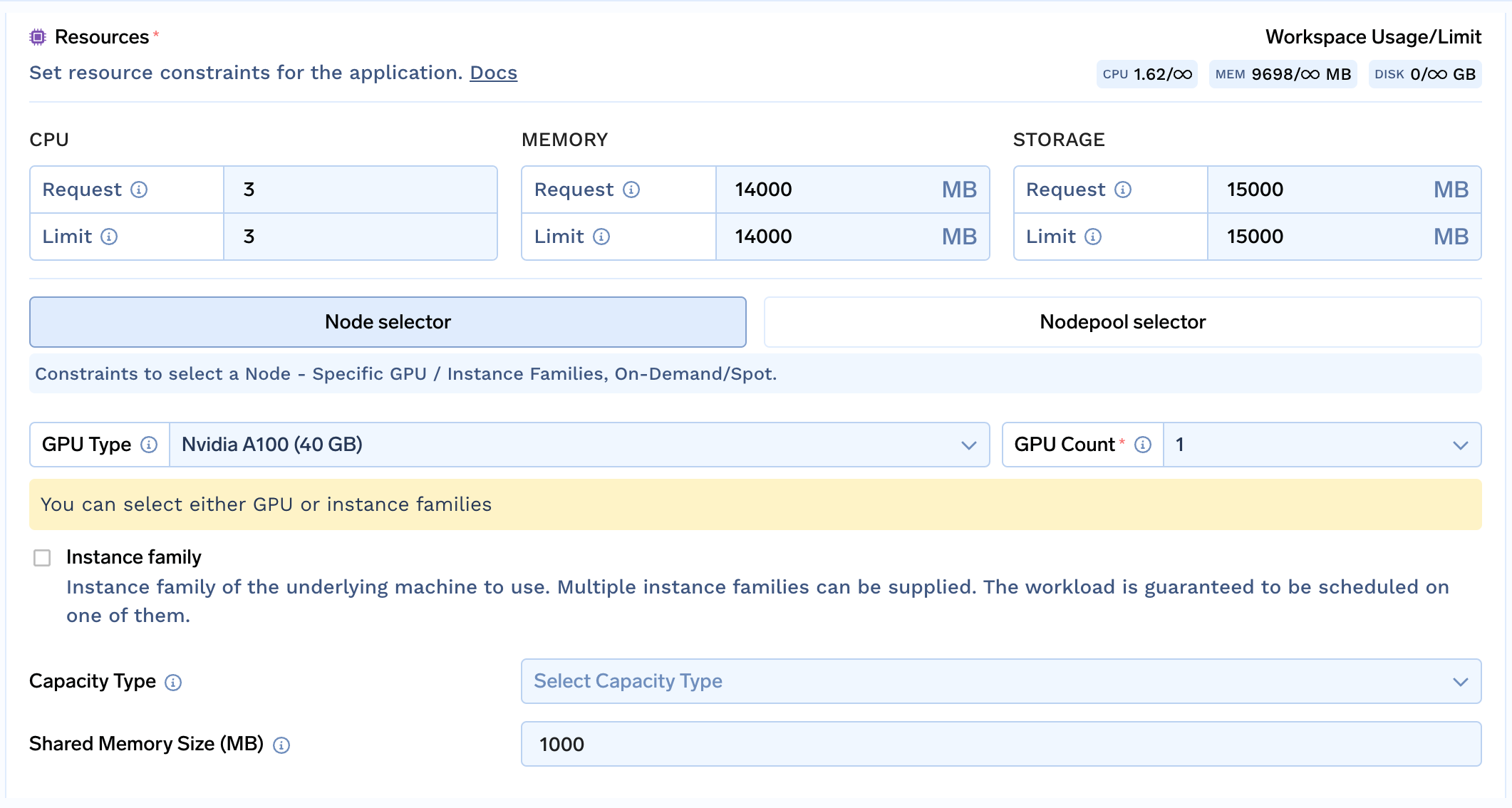
Scroll Down to the Resources section and select a GPU and GPU Count. In this case, we select A100_40GB with count 1.
For Azure cluster, you would have to create a nodepool and select it via Nodepool selector
Multiple GPUs and TGI Tensor Parallelism Limitation
When sharding a model accross multiple GPUs, some architecture required the layer dimensions be divisible by the number of GPUs - generally this turns out to be 2, 4, or 8.
For other resources:
- CPU - Generally this can be kept around
3or higher. - Memory - Generally this needs to be slightly more than the largest weight shard file. But in some cases safetensors weights are not available and conversion from
.binto.safetensorsmight require a lot of memory. In this case, we can choose14000MB - Storage - Generally this needs to be slightly more than the sum of all weight files (
.safetensors) in the model repo. But in some cases safetensors weights are not available and conversion from.binto.safetensorsmight be required, hence doubling the requirement. A rule of thumb is to keep this(2 x 1000 x Number of Parameters in Billions)when safetensors files are available and(4 x 1000 x Number of Parameters in Billions)when not. Following this, for Llama 2 7B this is14000MB. - Shared Memory - This should be kept
1000MB or higher
Fill in the environment variables
Next, we need to configure all model-specific fields in the Environment Variables section
Please see this link for more detailed description of these variables
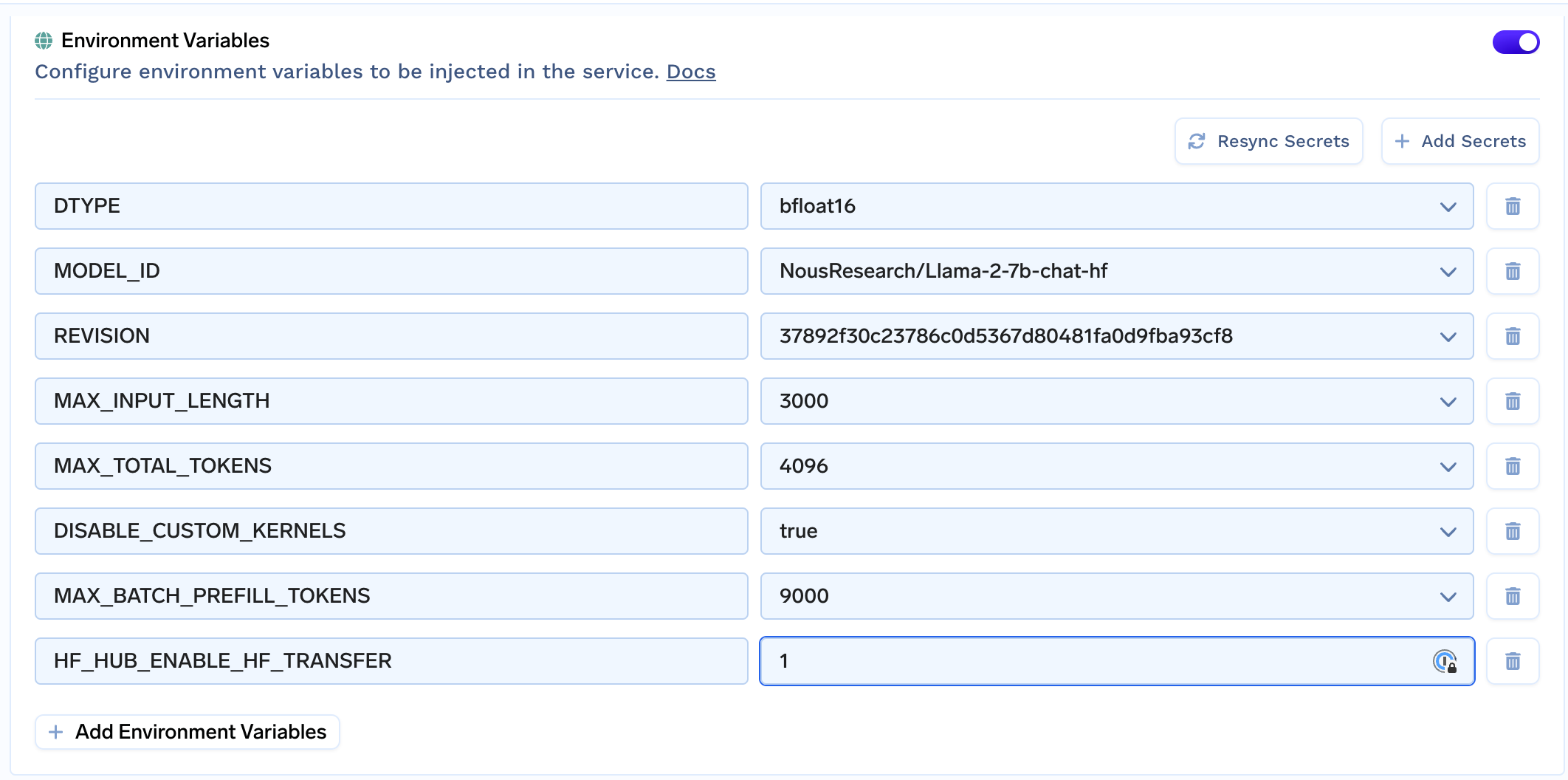
Here is a brief explanation
| Key | Description | Example Value |
|---|---|---|
MODEL_ID | Name of the model on Huggingface Hub | NousResearch/Llama-2-7b-chat-hf |
REVISION | Optional, Revision of the model. | 37892f30c23786c0d5367d80481fa0d9fba93cf8 |
DTYPE | Optional, precision of the model, by default float16 | bfloat16 |
MAX_INPUT_LENGTH | Max number of tokens allowed in a single request | 3600 |
MAX_TOTAL_TOKENS | Max number of total tokens (input + output) for a single sequence | 4096 |
MAX_BATCH_PREFILL_TOKENS | Max number of tokens to batch together in a prefill stage | 9000 |
MAX_BATCH_TOTAL_TOKENS | Max number of total tokens (input + output) in a batch while generating | 10000 |
HF_HUB_ENABLE_HF_TRANSFER | Optional, enables fast download | 1 |
DISABLE_CUSTOM_KERNELS | Optional, default false, some models might not work with custom kernels. | true |
MAX_INPUT_LENGTH- Per query, what is the maximum number of tokens a user can send in the prompt - This depends on your use case.MAX_TOTAL_TOKENS- This should ideally be set to the model's max context length (e.g. 4096 for llama 2), but in case you know ahead of time that you only need to generate max N tokens, then you can set it tomin(MAX_INPUT_LENGTH + N, model's max context length). Setting it higher than the model's max context length can lead to garbage outputsMAX_BATCH_PREFILL_TOKENS- The maximum number of tokens that can be fit in a batch during the pre-fill stage (prompt processing). This affects how much concurrency you can get out of a replica.MAX_BATCH_TOTAL_TOKENS- The maximum number of tokens that can be fit in a batch including input and output tokens. This can be automatically inferred for some models by the server based on free GPU memory after accounting for model size and max prefill tokens.
There are also some optional ones you might want to set, depending on your model and GPU selection
Key | Description | Example Value |
|---|---|---|
| Optional, Number of GPUs to shard the model across |
|
| Optional, Which quantization algorithm to use.
,
(8 bit),
,
|
|
| Optional, required for gated/private models. |
|
| Optional, default
, some models might not work with custom kernels. |
|
| Optional, default
, Some models might download custom code |
|
| Optional, Rope Scaling factor. Only available since v1.0.1 |
|
| Optional, Rope Scaling type. Only available since v1.0.1 |
|
Miscellaneous
Optionally, in the advanced options, you might want to
-
Create a Volume and Attach Volume to
/datato cache weights
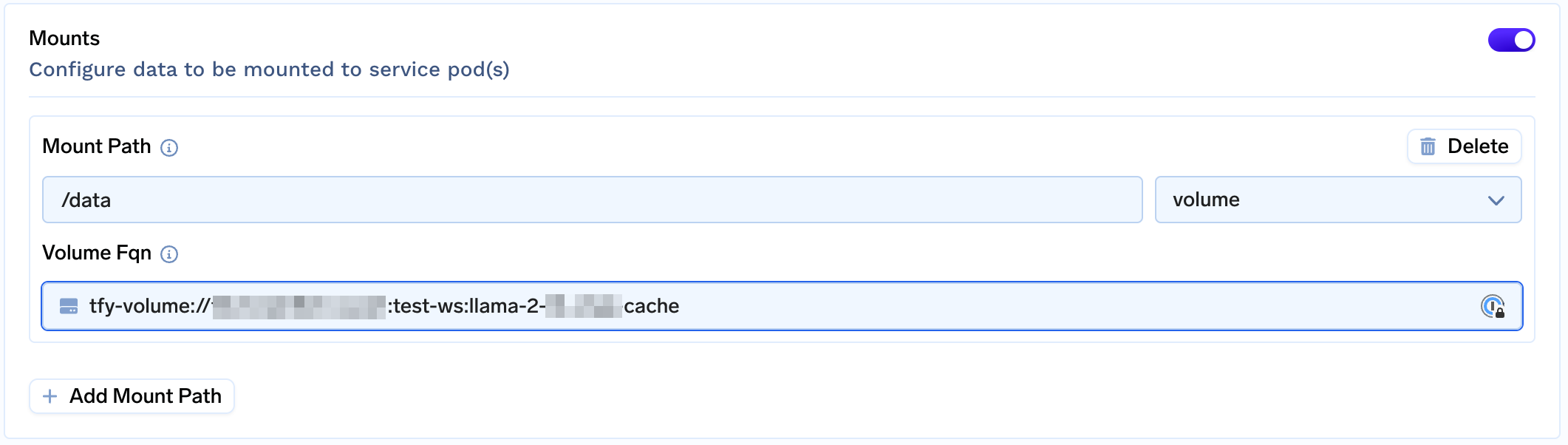
-
Configure AutoScaling and Rollout Strategy
Submit and Done!
Appendix
A frequently asked question is "Are more GPUs always better? Are large memory GPUs better?"
The answer to this depends on a variety of factors - most importantly how clever/optimised is the software running the inference and the use case. In modern NVIDIA GPUs compute units are much much faster than the memory bandwidth available to move the data from HBM to SRAM. Using multiple GPUs is not completely free either - most models require some reduce/gather/scatter operations which means the GPUs have communicate their individual results with one another adding overhead.
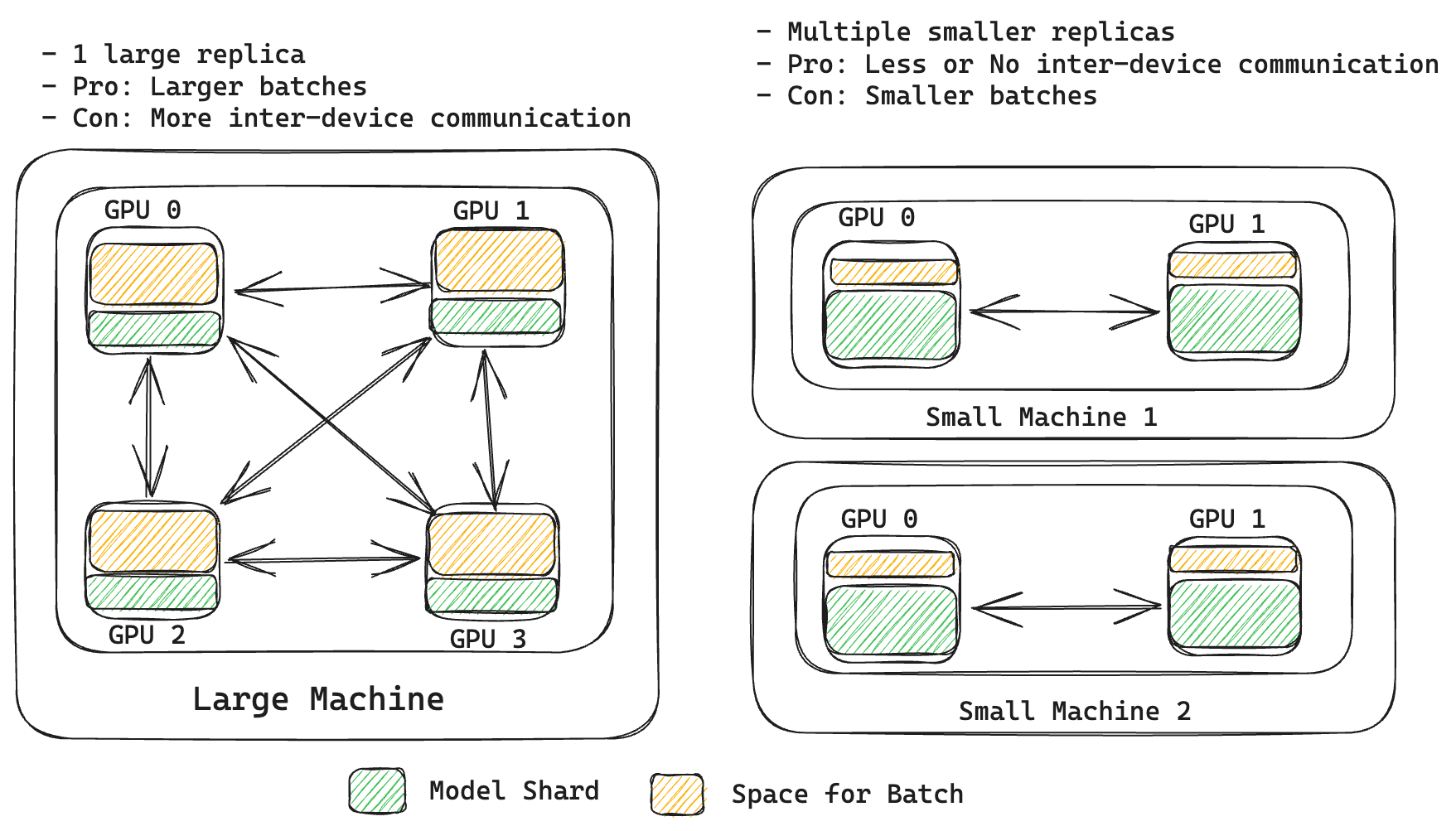
Specificially, for LLMs, there are two different stages - prefill (prompt processing) and decode (new tokens generation). Prefill is compute bound and while decode is memory bound. In prefill stage all tokens can be processed in parallel - which means prompt processing is quite fast and throwing more compute can improve the processing time. On the other hand, decoding is done one token at a time, so throwing more compute at it does not help because most of the time is spent in moving model weights and KV Caches around than computing.
Most high performance inference solutions (FlashAttention, PagedAttention, Continuous Batching) are designed to make the most out of hardware despite these constraints.
This means if your use case involves processing large prompts but generating few tokens (like Retrieval Augmented Generation or Classification) then using a large memory card (more space for larger batches) or more cards (more compute but also more space for batches) can be beneficial in reducing latency.
On the other hand if your use case in generation heavy (essay writing, summarization), using larger memory card might help generate more tokens simulatenously (at the cost of higher latency). Increasing the number of cards can result in even worse latency because of inter GPU communication overhead.
Relevant articles
Updated 2 months ago