Model Training and LifeCycle FAQs
When should I use 'Jobs' for model training?
While dealing with large datasets or complex models, we suggest using Jobs for training models. Notebooks are typically limited by single-machine constraints, manual execution, and potential inconsistencies in environment configurations.
- Can be easily scaled to use more computational resources (CPU, GPU, memory) as needed
- Ensures consistent execution environments and dependencies, making it easier to reproduce results
- Can be scheduled to run automatically, facilitating continuous integration and deployment (CI/CD) practices
- Can be configured with robust fault tolerance and monitoring, automatically retrying failed tasks and providing detailed logs and metrics
How do I handle a failed/interrupted job?
To handle a failed or interrupted job, you can specify the retries parameter to define the maximum number of times the job will be retried before it is marked as failed. The default retry count is 1. You can configure retries through the User Interface (UI) or using the Python SDK.
If a job terminates early, you need to give explicit instructions on where to resume from. You connect a volume and save checkpoints there and can easily instruct the let's say the HF Trainer to resume from the latest checkpoint with a single line of code.
My job is in 'suspended' state after deploying it successfully. How do I proceed?
After successfully deploying a job, it remains in a 'suspended' state, you have to trigger/ run the job. Deployment only involves preparing and making the job available for execution within a larger computing environment, which includes packaging the application and defining its execution environment, such as resources and data access. Post deployment, you need to trigger a run with your required parameters. Once triggered, your job will transition from 'suspended' to 'Running'. The platform will initiate the necessary actions to create and launch pods that execute the job's tasks.
Upon completion of the job, it will move to the 'Finished' status. The platform automatically releases the pods used for execution, along with the resources they utilized. You can trigger the job either through the user interface (UI) or programmatically to initiate its execution.
Once I have the training job setup and running, how do I add the trained models to the model registry?
You can automatically save and version model files/folder using the log_model method.When you log a model, it creates a fully qualified name (FQN) that uniquely identifies it, such as model:truefoundry/my-classification-project/my-sklearn-model:1. Subsequent calls to log_model with the same name will create new versions of the model (v2, v3, etc.).
After logging, you can find the logged models in the dashboard under the Models tab within your ML repo.
Is there a way to log and view certain metrics directly on the platform (e.g. train/val losses)?
You can easily log hyperparameters and metrics for each run using methods like log_params for capturing hyperparameters and log_metrics for capturing metrics. In the user interface, you can access hyperparameters and metrics by clicking on 'run details' within the specific job details page. For programmatic access, you can utilize get_params to retrieve parameters and get_metrics to fetch metrics directly in your code.
Additionally, in the ML repository, under the 'Runs' tab, you can compare multiple runs and apply filters based on criteria such as evaluation metrics or loss values greater than a specified threshold.
What all backends are available for artifact logging is it just S3 or can use other solutions like ebs volumes, efs etc ?
For saving Artifacts, we allow S3, GS, and Azure Blob. You can, however, create a Volume on a workspace backed by EFS/EBS (as you are on AWS) directly from the dashboard. The said Volume can be mounted to any workload pod in the workspace.
I am usingTrueFoundry SDK to schedule and deploy new jobs, where each job may have different environment variables.How to ensure that every time a scheduled job runs, it pulls the latest code available in the repository?
By default, when a containerized job is scheduled to run in Kubernetes, it may not always pull the latest image (which contains your code). Instead, it might use a cached version of the image that was previously pulled.
To ensure that your job always pulls the latest image (i.e., the latest code), you need to configure the job’s imagePullPolicy to Always. This ensures that Kubernetes always pulls the latest version of the container image whenever the job runs.
To achieve this, you can apply a Kustomize patch. Kustomize is a tool used in Kubernetes to customize configurations by overlaying patches on the original configurations.
Click on show advanced field in the Job deployment form and add the Kustomize patch.
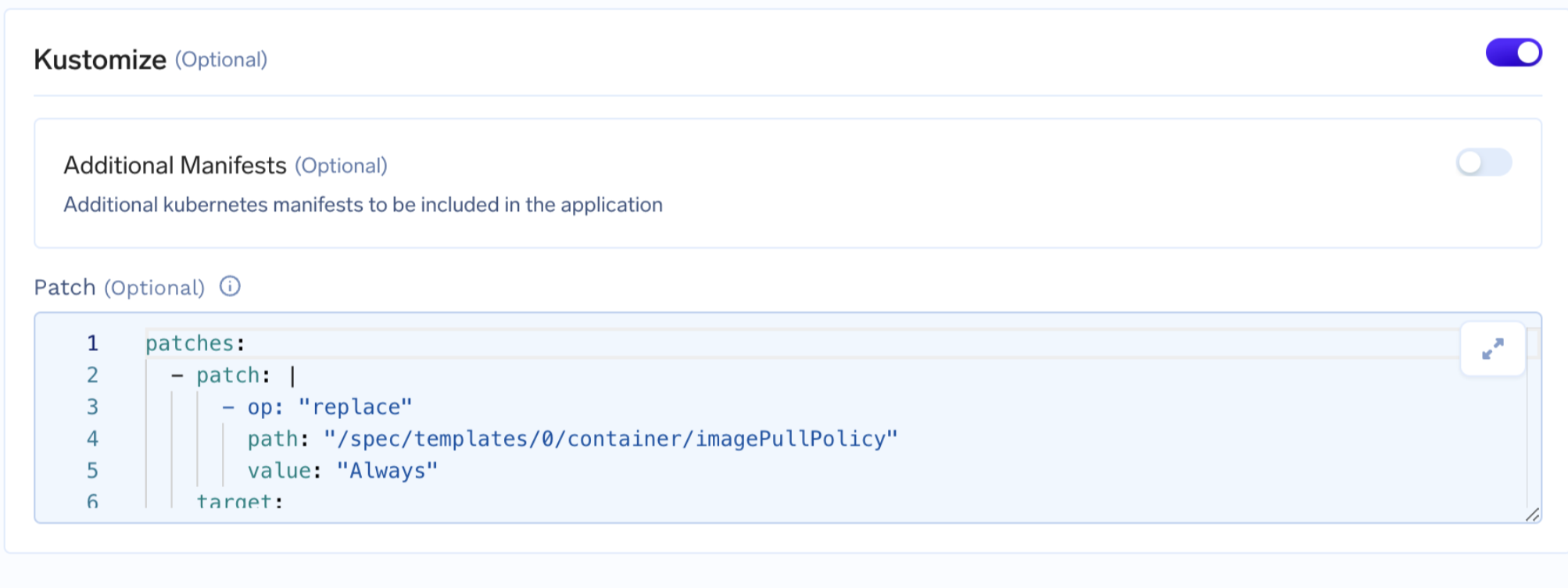
Sample code snippet below. You can replace the job name below with your job.
patches:
- patch: |
- op: "replace"
path: "/spec/templates/0/container/imagePullPolicy"
value: "Always"
target:
kind: WorkflowTemplate
name: <job_name>
group: argoproj.io
version: v1alpha1
Use the 'Python Spec' button after editing the form to get the final python spec if required.
Updated about 1 month ago