Load Testing the Gateway
Highlights
- TrueFoundry LLM Gateway scales seamlessly to 350 RPS on a single replica of 1 unit CPU while using 270 MB of memory. We compared with another gateway product on a similar setup and it failed to scaled beyond 50 RPS
- TrueFoundry LLM Gateway only adds an extra latency of 3-5 ms, while the other gateway product adds between 15-30 ms per request.
Load Test Setup
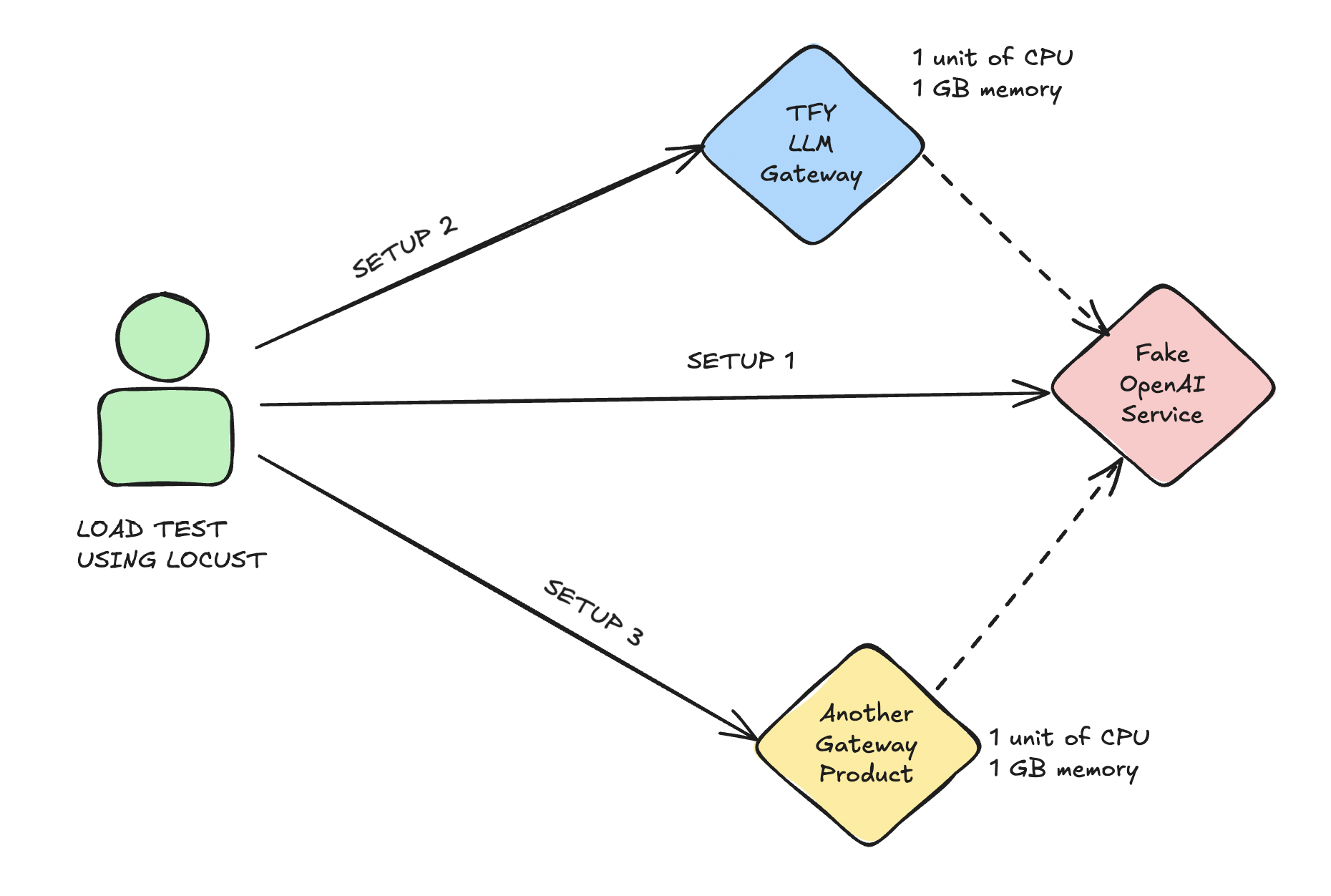
For our load testing experiment, we setup a deployed this fake OpenAI endpoint service using TrueFoundry. The service would simulate OpenAI request and response format without actually producing tokens.
We also deployed the TrueFoundry LLM Gateway and another gateway product both running of a single replica with 1 unit CPU and 1 GB memory.
We added our fake OpenAI provider into both TrueFoundry and the other gateway product. While load testing, we made requests to the fake OpenAI server in 3 different ways:
Setup 1: Directly without using any proxy or gateway
Setup 2: Through the TrueFoundry LLM Gateway deployed on 1 unit CPU and 1 GB memory
Setup 3: Through the other gateway product deployed on 1 unit CPU and 1 GB memory
Median Latency during Load Test
| Request Per Second (RPS) | OpenAI direct (Setup 1) | TrueFoundry LLM Gateway (Setup 2) | Another Gateway Product (Setup 3) |
|---|---|---|---|
| 10 RPS | 73 ms | 76 ms (+3 ms) | 88 ms (+15 ms) |
| 50 RPS | 73 ms | 76 ms (+3 ms) | 99 ms (+26 ms) |
| 200 RPS | 73 ms | 76 ms (+3 ms) | Could not scale |
| 300 RPS | 73 ms | 77 ms (+4 ms) | Could not scale |
Observations
- TrueFoundry Gateway: Adds only an extra 3 ms in latency up to 250 RPS and 4 ms at RPS > 300. TrueFoundry LLM Gateway was able to scale without any degradation in performance until about 350 RPS (1 vCPU, 1 GB machine) before the CPU utilization reached 100% and latencies started getting affected. With more CPU or more replicas, the LLM Gateway can scale to tens of thousands of requests per second.
More metrics
Setup 1: Direct OpenAI endpoint calling
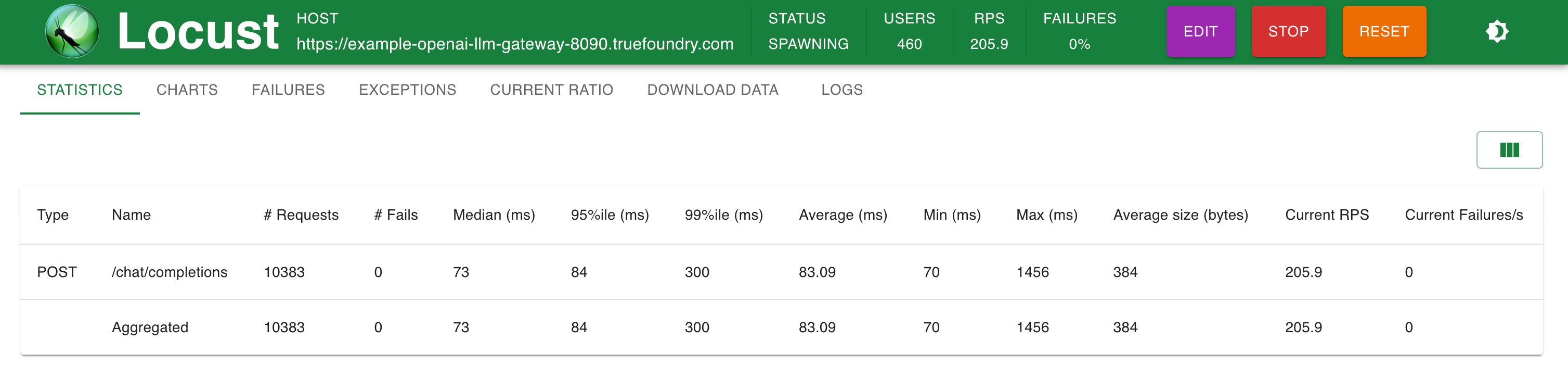
Stats @ 200 RPS
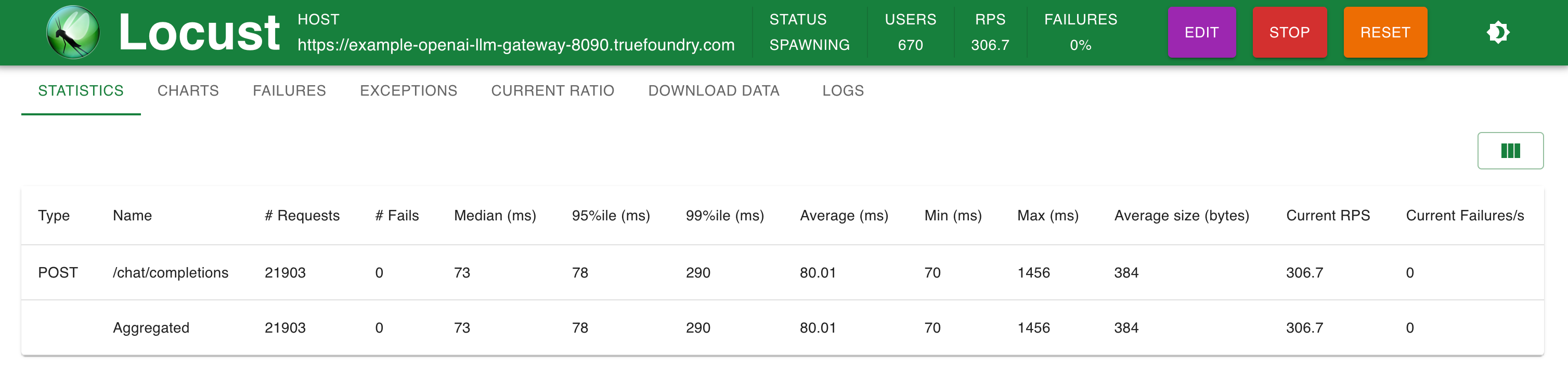
Stats @ 300 RPS
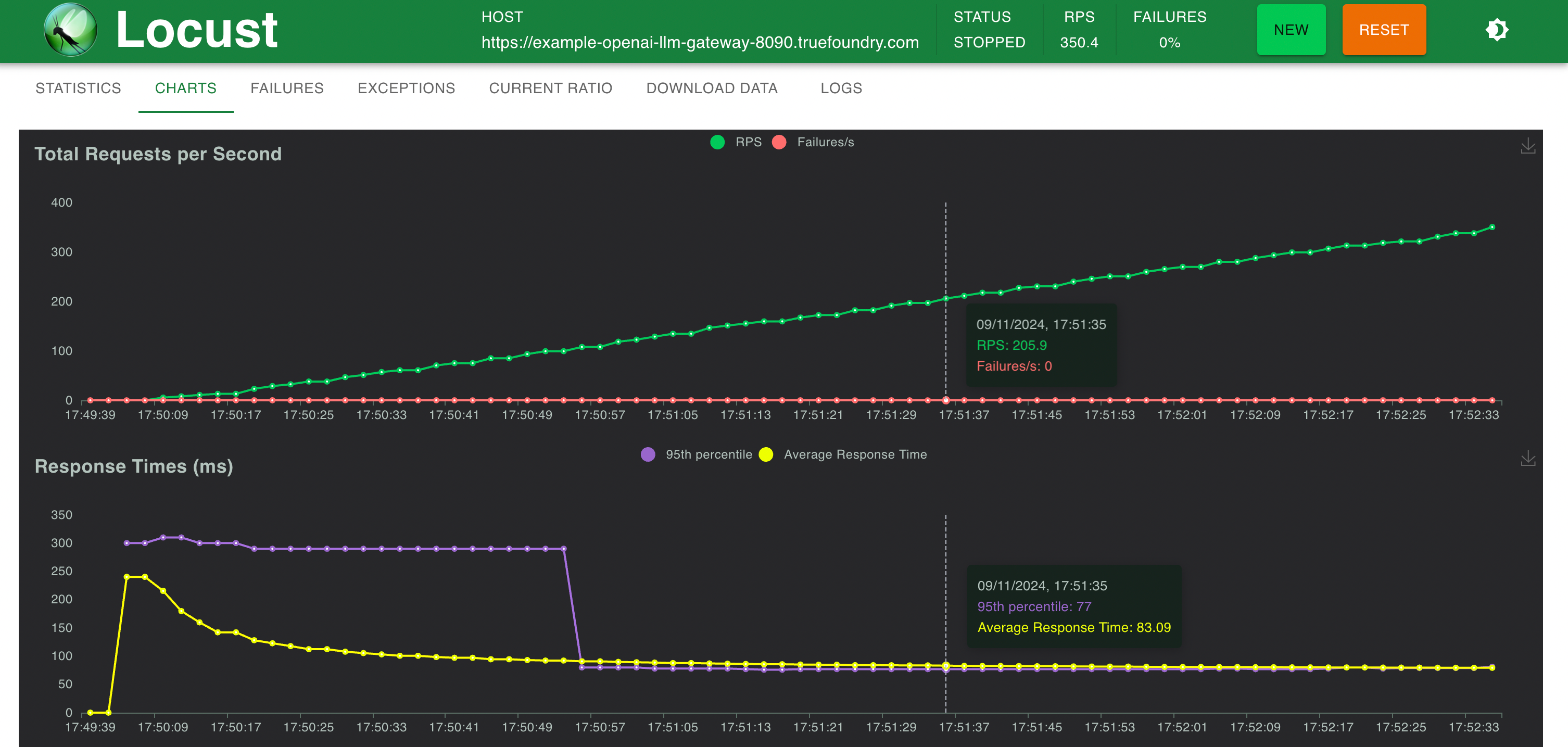
Response Times v/s RPS
Setup 2: TrueFoundry LLM Gateway
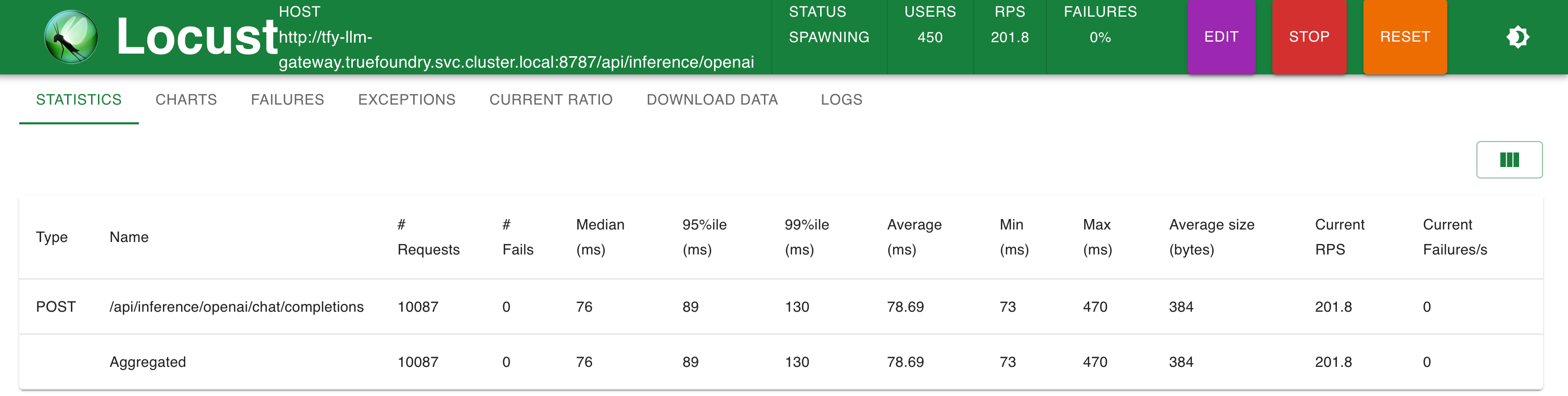
Stats @ 200 RPS
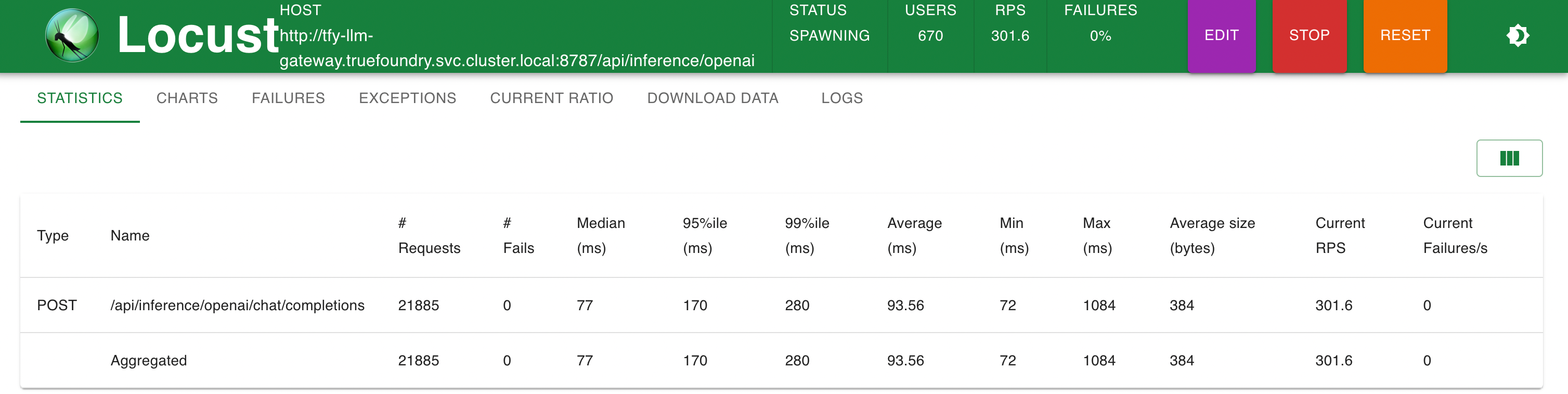
Stats @ 300 RPS
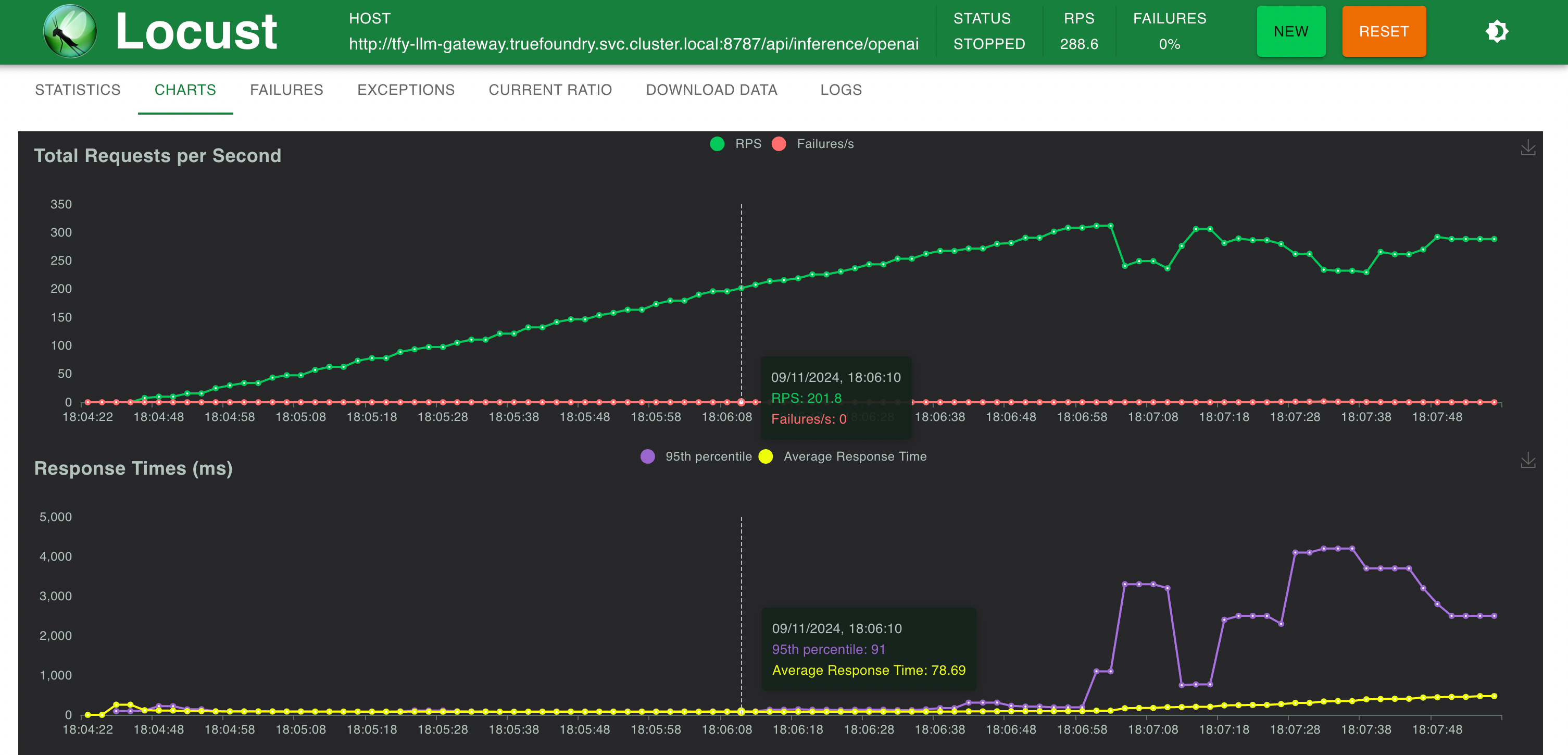
Response Times v/s RPS
Updated about 20 hours ago