Create Service for a live endpoint
What you'll learn
- Creating a Gradio application to serve your model deployment endpoint
- Deploying our service via
servicefoundry
This is a guide to deploy a Service deployed via Model Deployment via Gradio using servicefoundry
After you complete the guide, you will have a successfully deployed Gradio Service. Your deployed Gradio Service will look like this:
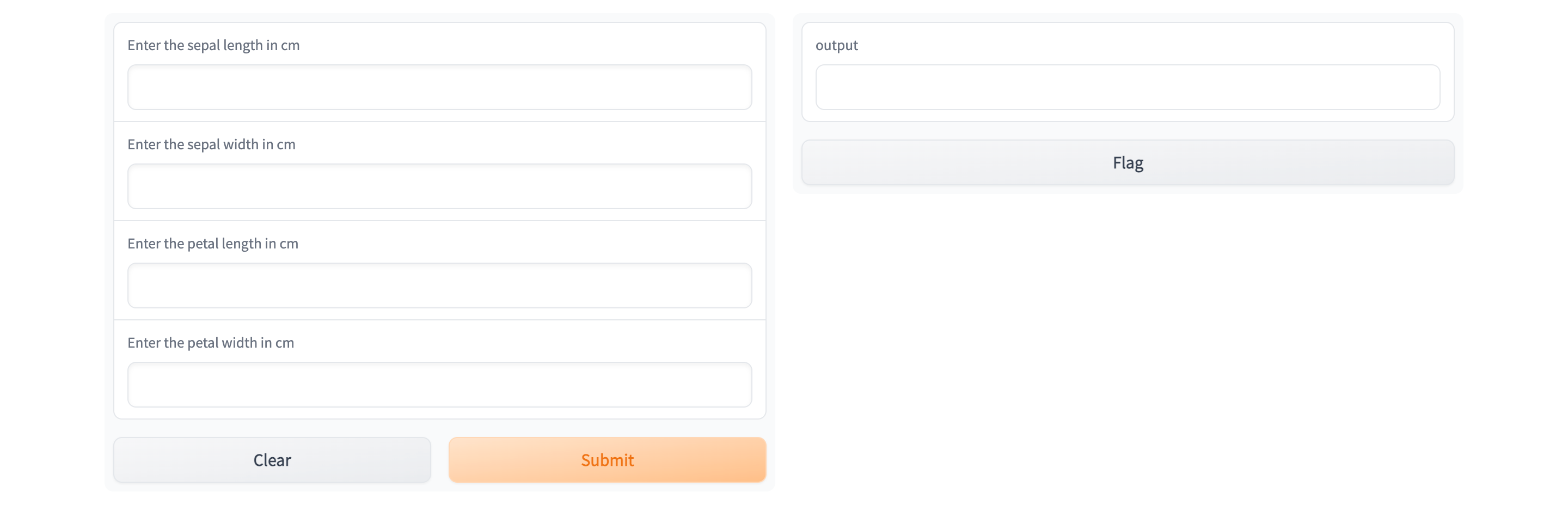
This guide assumes you have already deployed a model via Model Deployment. If you haven't you can follow this guide Guide
Project structure
To complete this guide, you are going to create the following files:
app.py: contains our inference and Gradio codedeploy.py: contains our deployment coderequirements.txt: contains our dependencies.
Your final file structure is going to look like this:
.
├── app.py
├── deploy.py
└── requirements.txt
As you can see, all the following files are created in the same folder/directory.
Step 1: Copy the Model Deployment Endpoint
Firstly you need the Model Deployment endpoint, as we will calling inference requests to this endpoint.
For that you can go to click on the Services tab, and click on the Service name, and then copy the service endpoint

Step 2: Implement the inference service code.
The first step is to create a web Interface and deploy the model.
For this, we are going to use Gradio for this. Gradio is a python library using which we can quickly create a web interface on top of our model inference functions.
Create the app.py and requirements.txt files in the same directory where the model is stored.
.
├── app.py
└── requirements.txt
app.py
app.pyIn the code below ensure to replace "" with the model-fqn you copied above
import gradio as gr
import datetime
import os
import requests
from urllib.parse import urljoin
# get the model deployment url from the environment variables
MODEL_DEPLOYED_URL = os.environ['MODEL_DEPLOYED_URL']
# specifying the desired input components
inputs = [
gr.Number(label = "Enter the sepal length in cm"),
gr.Number(label = "Enter the sepal width in cm")
gr.Number(label = "Enter the petal length in cm")
gr.Number(label = "Enter the petal width in cm")
]
# prediction function
def predict(*val):
# request body in dictionary format
json_body = {"parameters": {
"content_type": "pd"
}, "inputs": []}
# add the values into inputs list of json_body
for v, inp in zip(val, inputs):
json_body["inputs"].append(
{
"name": inp.label,
"datatype": "FP32",
"data": [v],
"shape": [1]
}
)
# use the requests library, post the request and get the response
resp = requests.post(
url=urljoin(MODEL_DEPLOYED_URL, "v2/models/churn-model/infer"),
json=json_body
)
# convert the response into dictionary
r = resp.json()
# return the output and model_version
return [ r["outputs"][0]["data"][0], r["model_version"]]
# create description for the gradio application
desc = f"""## Demo Deployed at {datetime.datetime.now().strftime("%d/%m/%Y %H:%M:%S")}"""
# setup Gradio Interface
app = gr.Interface(
fn=predict,
inputs=inputs,
outputs=[gr.Textbox(label="Flower Type"), gr.Textbox(label="Model Version")],
description=desc,
title="Iris Flower Classifier",
)
# launch the gradio interface
app.launch(server_name="0.0.0.0", server_port=8080)
requirements.txt
requirements.txtpandas
gradio
scikit-learn
joblib
altair
Step 3: Deploying the inference API
You can deploy services on TrueFoundry programmatically using our Python SDK
Via python SDK
File Structure
.
├── app.py
├── deploy.py
└── requirements.txt
deploy.py
deploy.pyimport argparse
import logging
from servicefoundry import Build, PythonBuild, Service, Resources, Port
logging.basicConfig(level=logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument("--workspace_fqn", required=True, type=str)
args = parser.parse_args()
service = Service(
name="gradio",
image=Build(
build_spec=PythonBuild(
command="python app.py",
requirements_path="requirements.txt",
)
),
ports=[
Port(
port=8080,
host="<Provide a host value based on your configured domain>"
)
],
resources=Resources(memory_limit=1500, memory_request=1000),
)
service.deploy(workspace_fqn=args.workspace_fqn)
To deploy using Python API use:
python deploy.py --workspace_fqn <YOUR WORKSPACE FQN HERE>
Run the above command from the same directory containing the
app.pyandrequirements.txtfiles.
Via YAML file
File Structure
.
├── iris_classifier.joblib
├── app.py
├── deploy.yaml
└── requirements.txt
deploy.yaml
deploy.yamlname: gradio
type: service
image:
type: build
build_source:
type: local
build_spec:
type: tfy-python-buildpack
command: python app.py
ports:
- port: 8080
host: <Provide a host value based on your configured domain>
resources:
memory_limit: 1500
memory_request: 1000
Follow the recipe below to understand the deploy.yaml code:
With YAML you can deploy the inference API service using the command below:
servicefoundry deploy --workspace-fqn YOUR_WORKSPACE_FQN --file deploy.yaml
Run the above command from the same directory containing the
app.pyandrequirements.txtfiles.
Interact with the service
After you run the command given above, you will get a link at the end of the output. The link will take you to your application's dashboard.
Once the build is complete you should get the endpoint for your service :-
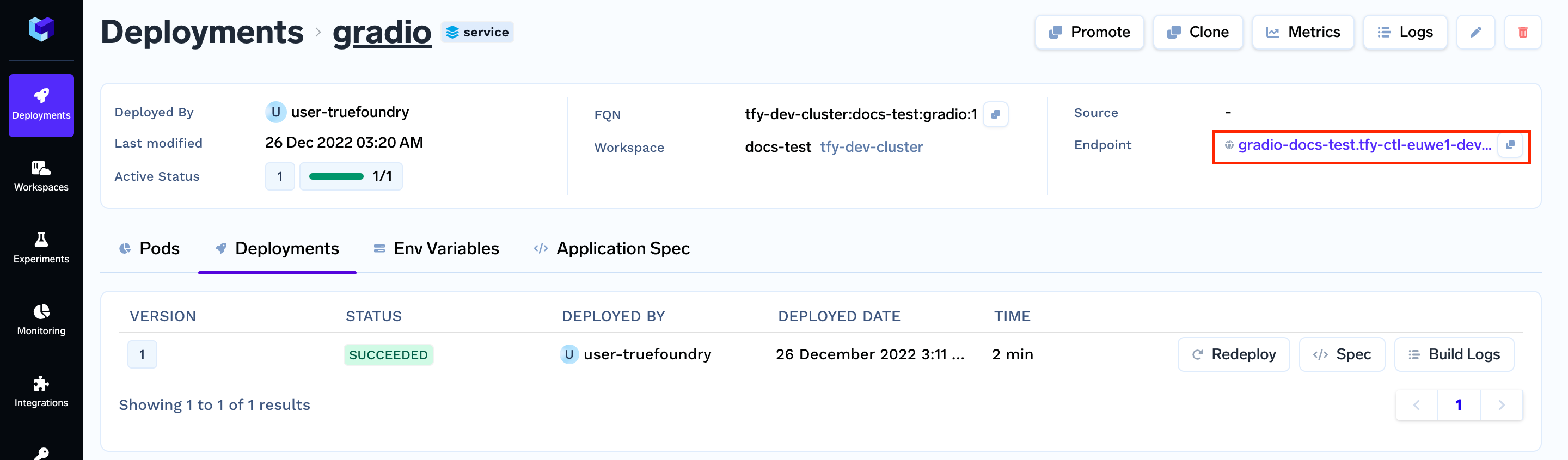
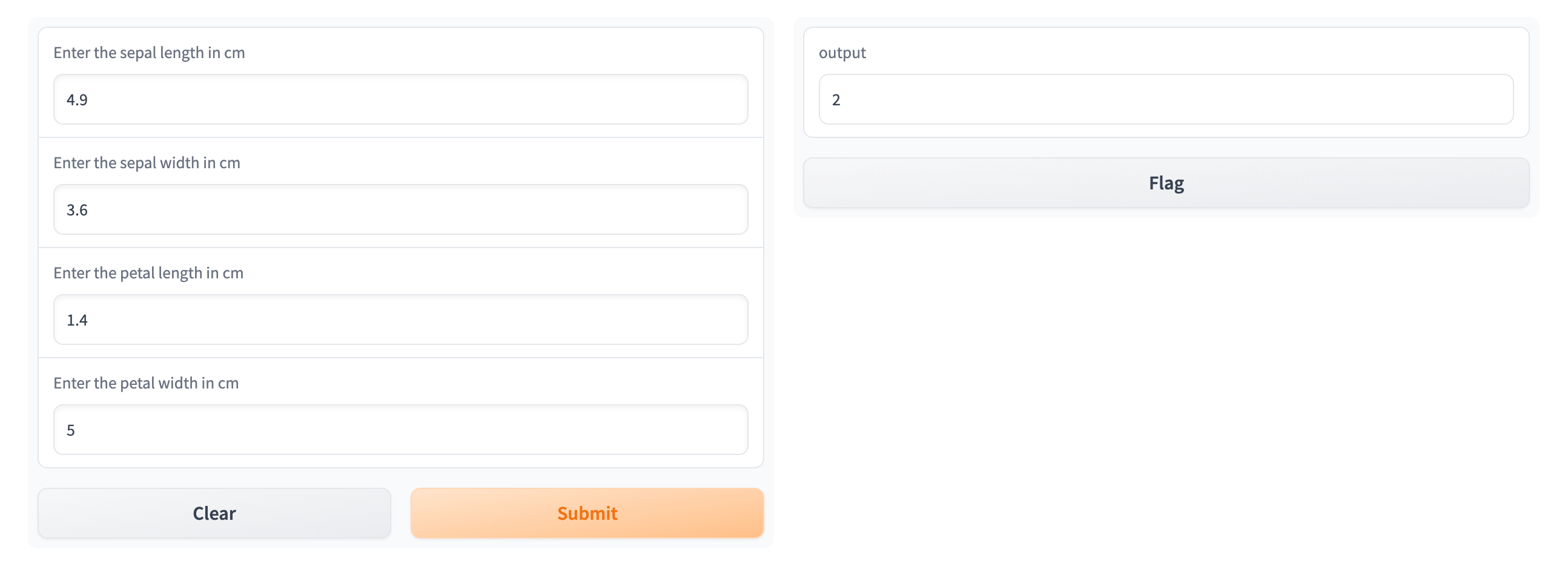
Click on the endpoint, and it will open you deployed Gradio service.
Now you can enter your data and get the output.
Next Steps
Updated 8 months ago