A lot of services and models that are deployed are not used all the time. A very common pattern is dev services not being used during the weekends or off-office hours. While Truefoundry provides a pause/resume service feature, it relies on developers to manually pause the service. This can lead to human errors and cost leakage.
Another option to automatically shut down a service if there are no requests for a period and then automatically start it when a request is received is to use the scale to 0 feature. You can configure that the service will shut down once there are no requests for let’s say 10 minutes. After 10 mins of no requests, the service will be scaled to 0. Then if we make a request to the service, the service will automatically be scaled up.
The start of the service will have a delay (cold start time) since it might first need to download the image and then start the service. This feature is most commonly used and best suited for dev environments.
Configuring Scale to 0
In the Service deployment form, enable the Advanced Fields toggle and then you will see the Auto Shutdown section as shown below.
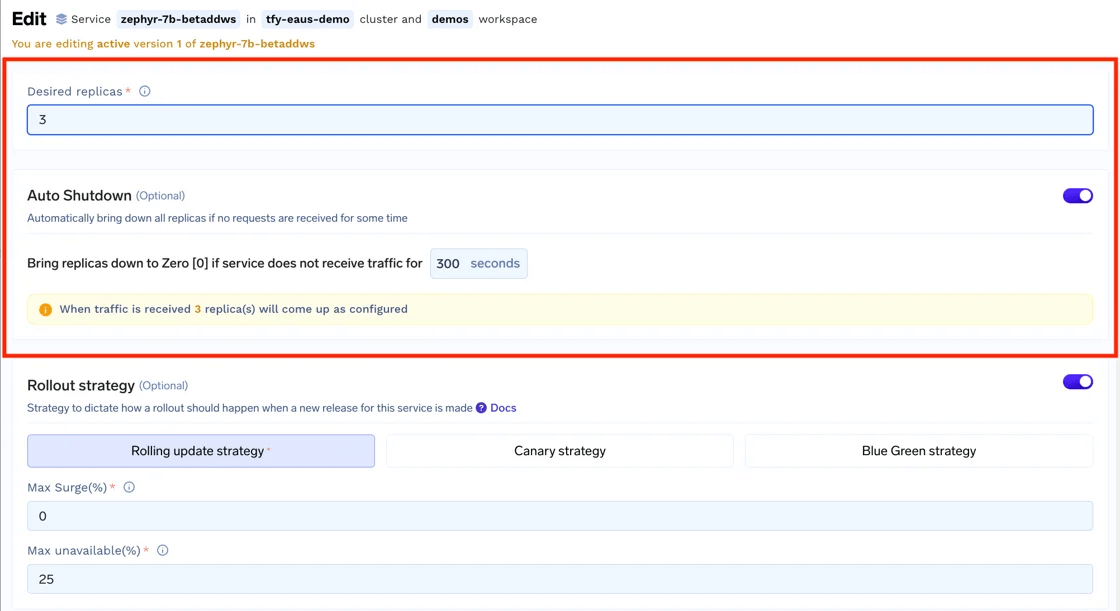 You will need to configure the idle timeout parameter. This is the number of minutes after which the service will be scaled to 0 if there are no requests.
You will need to configure the idle timeout parameter. This is the number of minutes after which the service will be scaled to 0 if there are no requests.
How does Scale to 0 work?
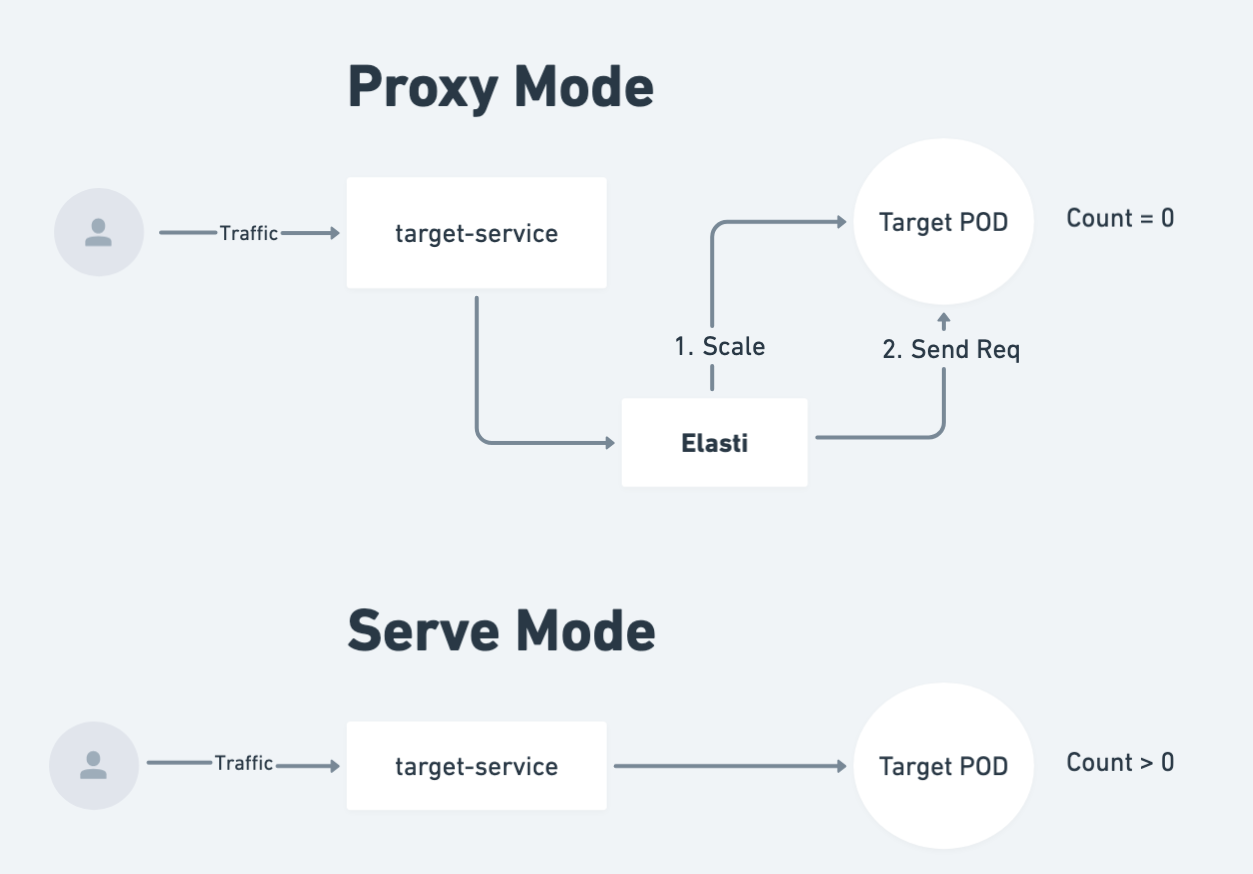
Scale to 0 is powered by the Elasti. Its an open-source Kubernetes-native solution built by Truefoundry that offers scale-to-zero functionality on Kubernetes when there is no traffic and automatic scale up to 0 when traffic arrives. A brief summary about Elasti is:
Most Kubernetes autoscaling solutions like HPA or Keda can scale from 1 to n replicas based on cpu utilization or memory usage. However, these solutions do not offer a way to scale to 0 when there is no traffic. Elasti solves this problem by dynamically managing service replicas based on real-time traffic conditions. It only handles scaling the application down to 0 replicas and scaling it back up to 1 replica when traffic is detected again. The scaling after 1 replica is handled by the autoscaler like HPA or Keda.
Elasti uses a proxy mechanism that queues and holds requests for scaled-down services, bringing them up only when needed. The proxy is used only when the service is scaled down to 0. When the service is scaled up to 1, the proxy is disabled and the requests are processed directly by the pods of the service.