Upload Model From UI
You can either upload a model file from disk or import a model saved in your S3 bucket.Log Model In Code
Install the truefoundry library following the instructions here
- Custom Framework
- SkLearn
- Transformers
- Pytorch
- TensorFlow
truefoundry.ml
FastAIFramework, GluonFramework, H2OFramework, KerasFramework, LightGBMFramework, ONNXFramework, PaddleFramework, SklearnFramework, SpaCyFramework, StatsModelsFramework, TransformersFramework, XGBoostFramework
Any subsequent calls to
log_model with the same name would create a new version of this model - v2, v3 and so on.View and manage versions
The logged model can be found in the Models tab. It can also be accessed from inside the MLRepo.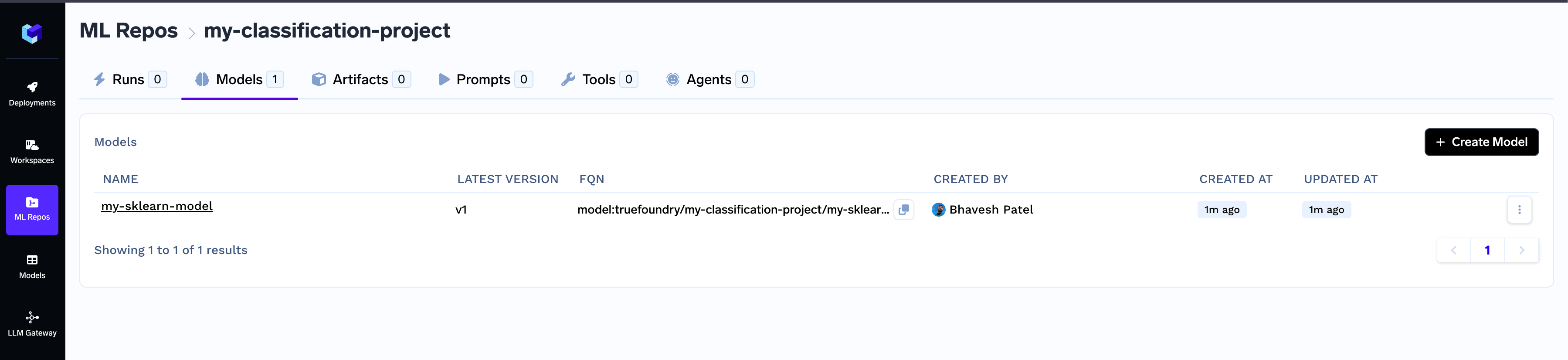
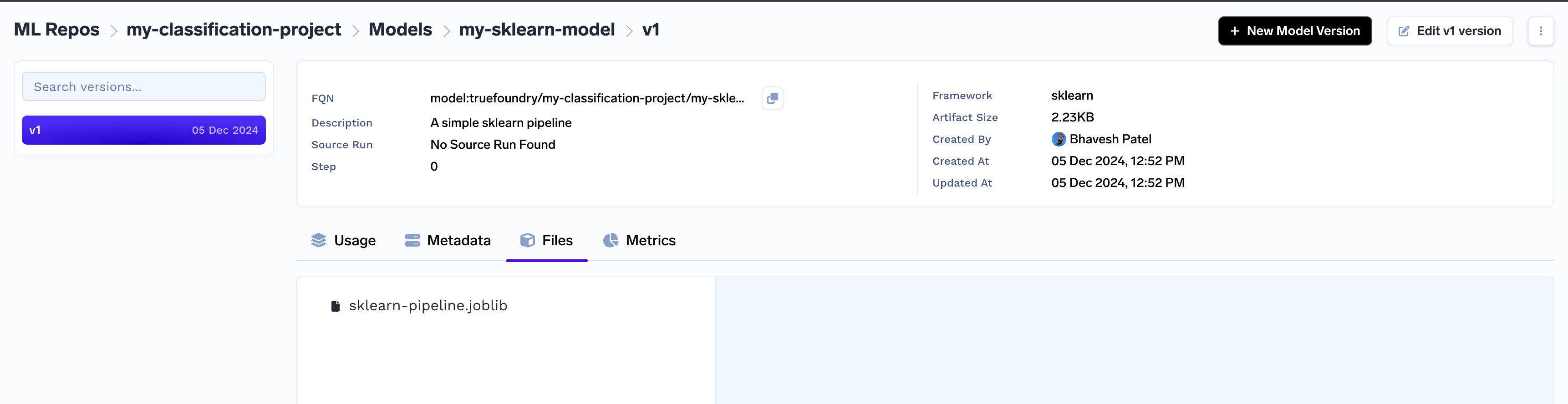
Once a model version is created, the model version files are immutable. Only fields like description, framework, metadata can be updated using CLI or UI.
Using the Model in your code
For every model version, you can find the code to download it in your inference service.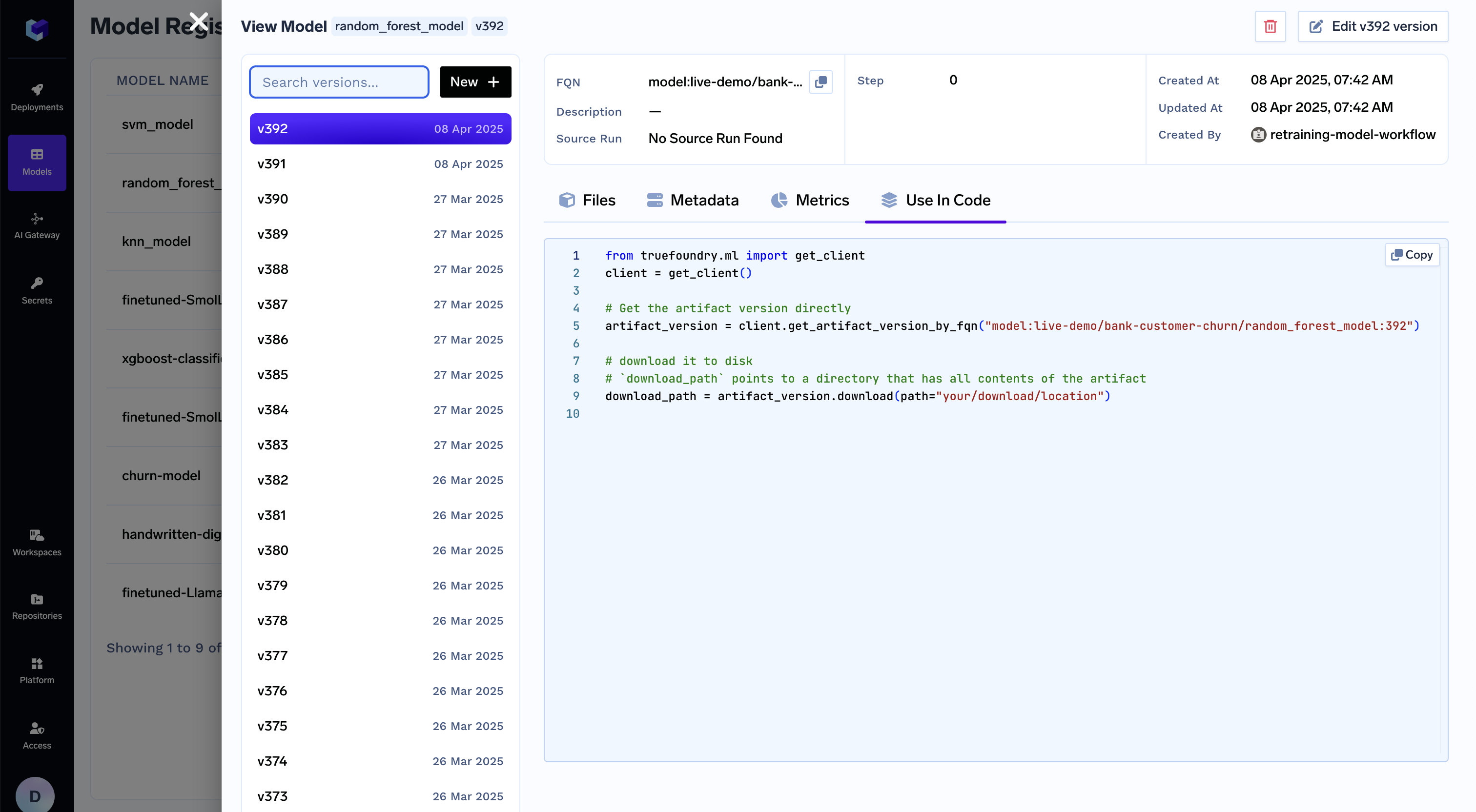
Code Snippet to download model