Supported Model TypesCurrently we list NIM models of following types
- Large Language Models (LLMs)
- Vision Language Models (VLMs)
- Embedding Models
- Reranking Models
Adding nvcr.io Docker Registry
-
Generate an API Key from https://org.ngc.nvidia.com/setup/api-keys
Make sure to give it access to
NGC Catalog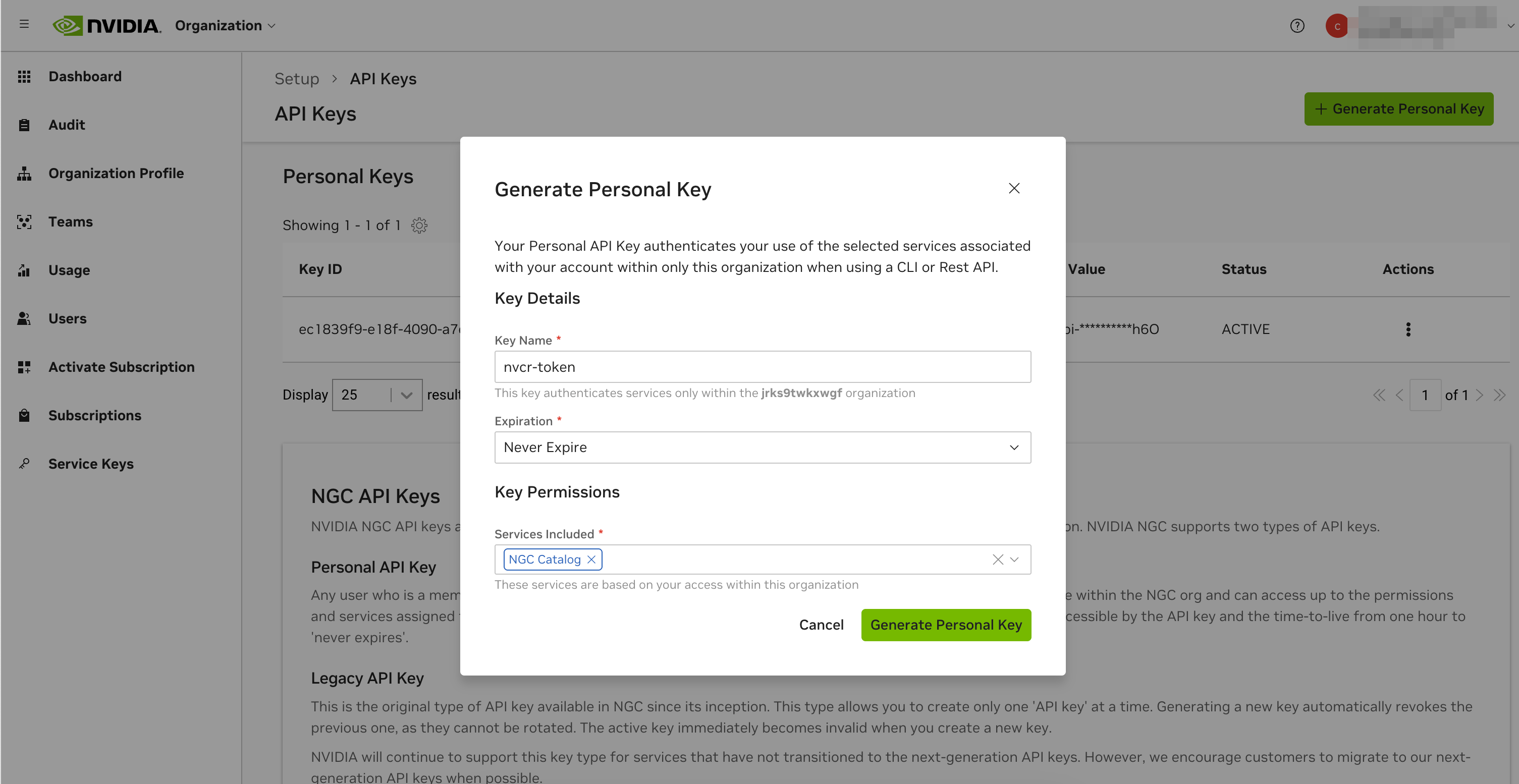
-
Add a Custom Docker Registry to the Platform
- Registry URL:
nvcr.io - Username:
$oauthtoken - Password: The API Key from the previous step
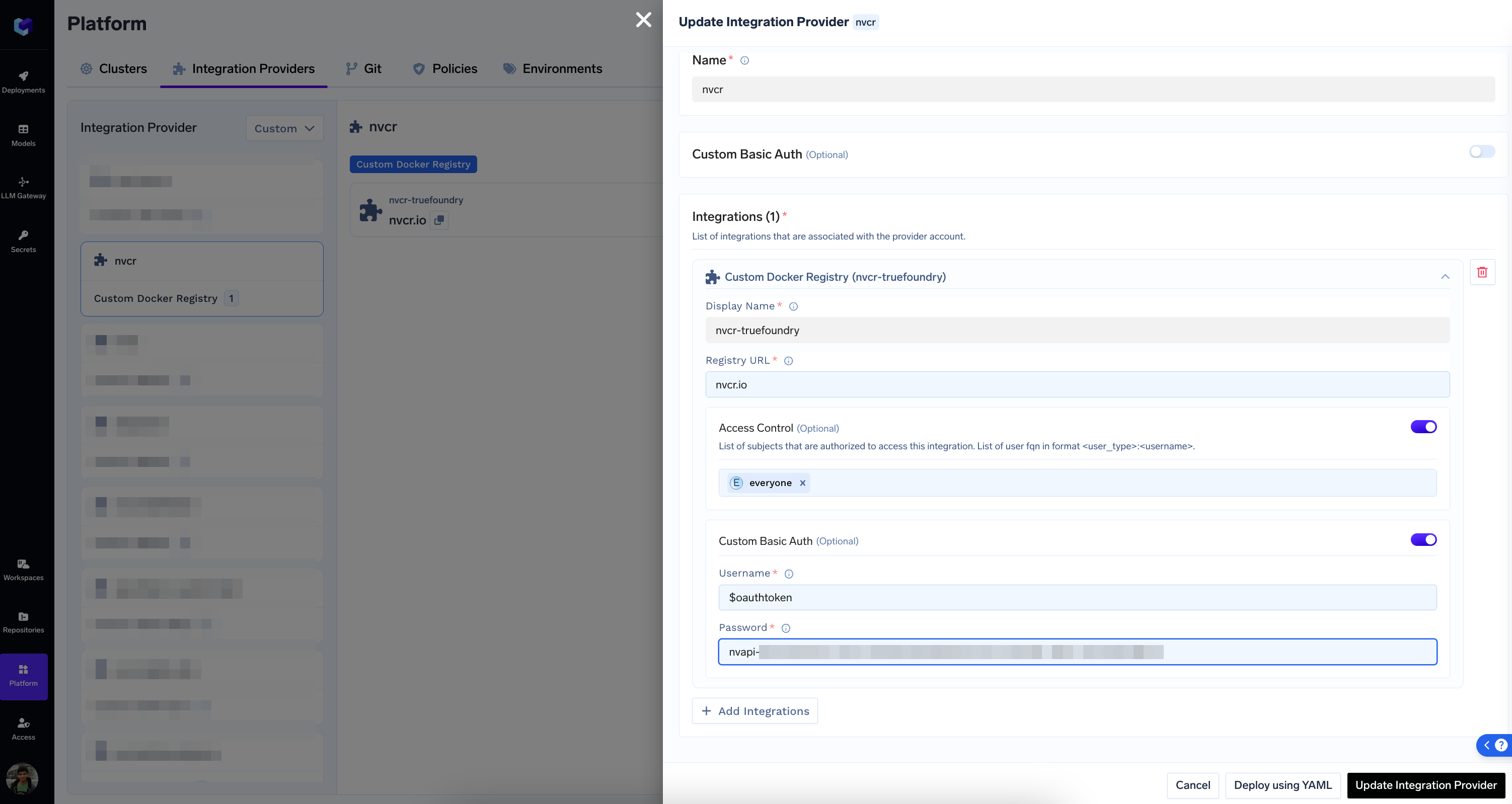
- Registry URL:
Adding NGC API Key to Secrets
-
Add the same API Key as a Secret on the Platform. We are calling the secret
NGC_API_KEY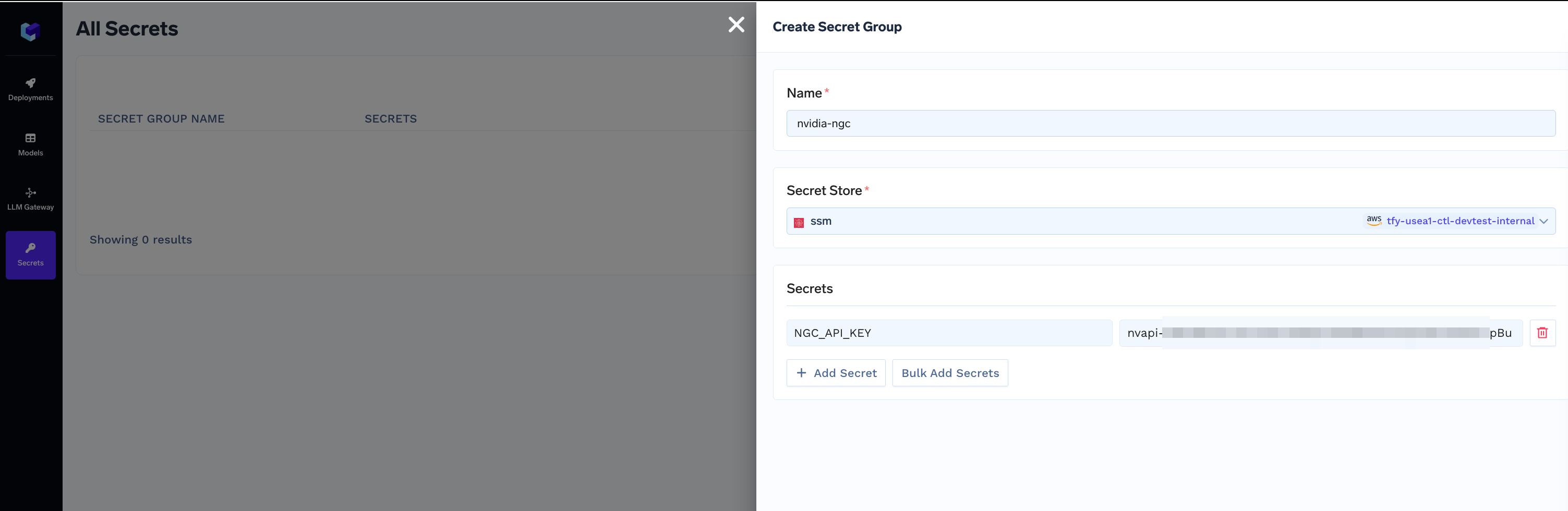
Deploying a NIM Model
-
From
New Deploymentpage, selectNVIDIA NIM.- Select the workspace you want to deploy to
- Select the NVCR Model Registry Integration we created in the previous step
- Select the NGC API Key Secret we created in the previous step
- Select the model you want to deploy
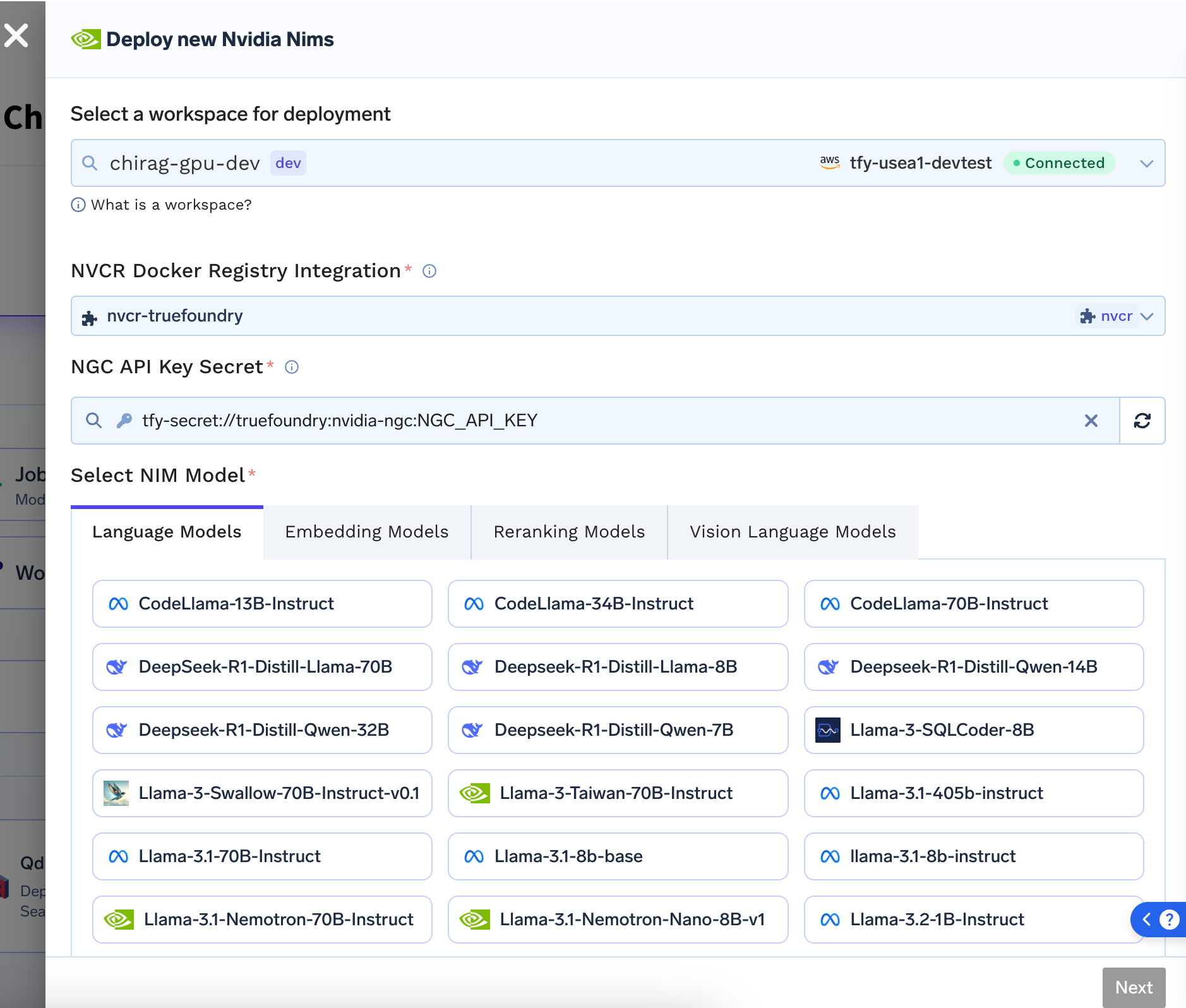
-
Click Next. You will be presented with optimized profiles (for
latencyorthroughput) for differerent precision and GPU options for which TRT-LLM engines are prebuilt and available. You can select any of the profile and Continue to Deployment.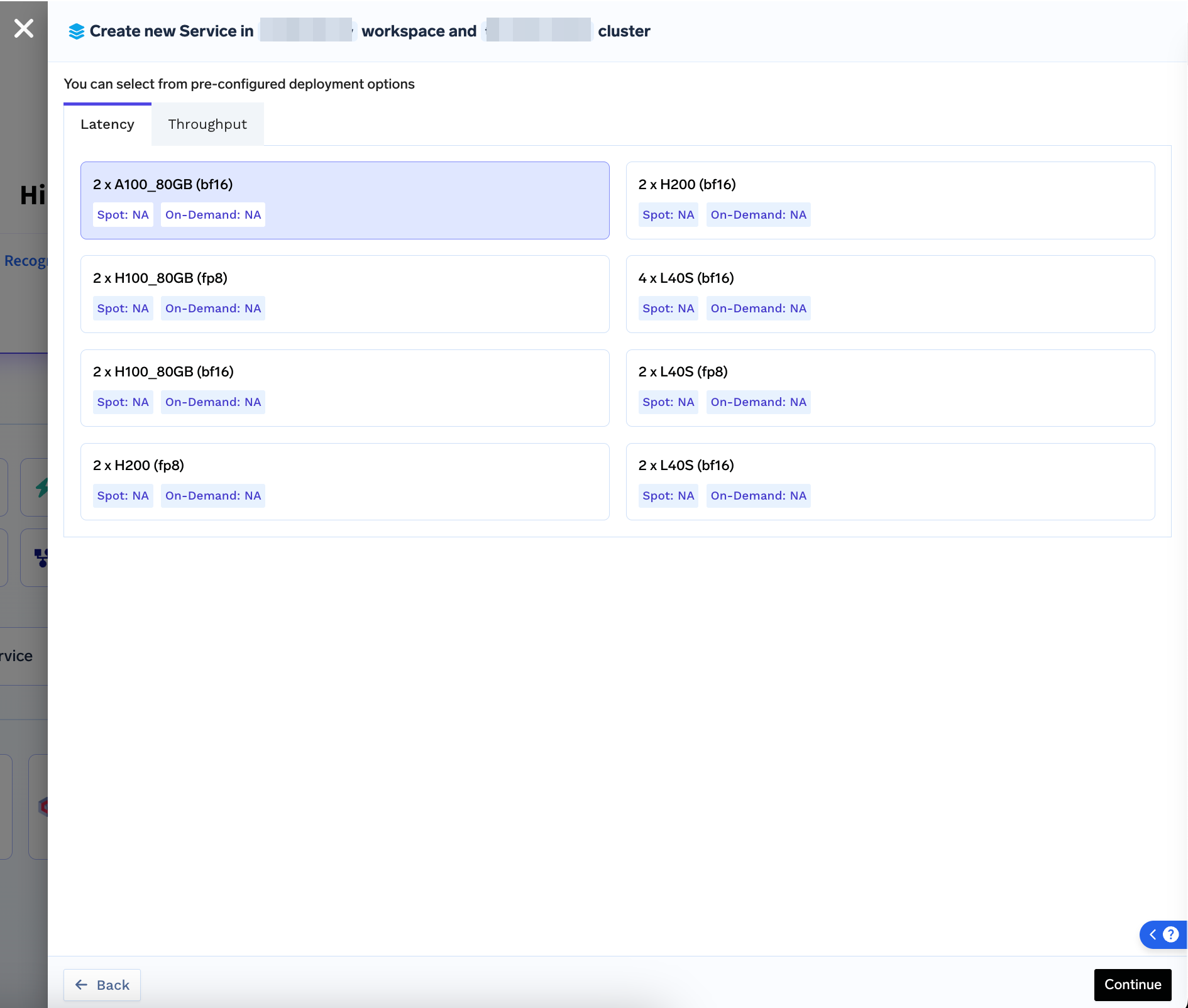
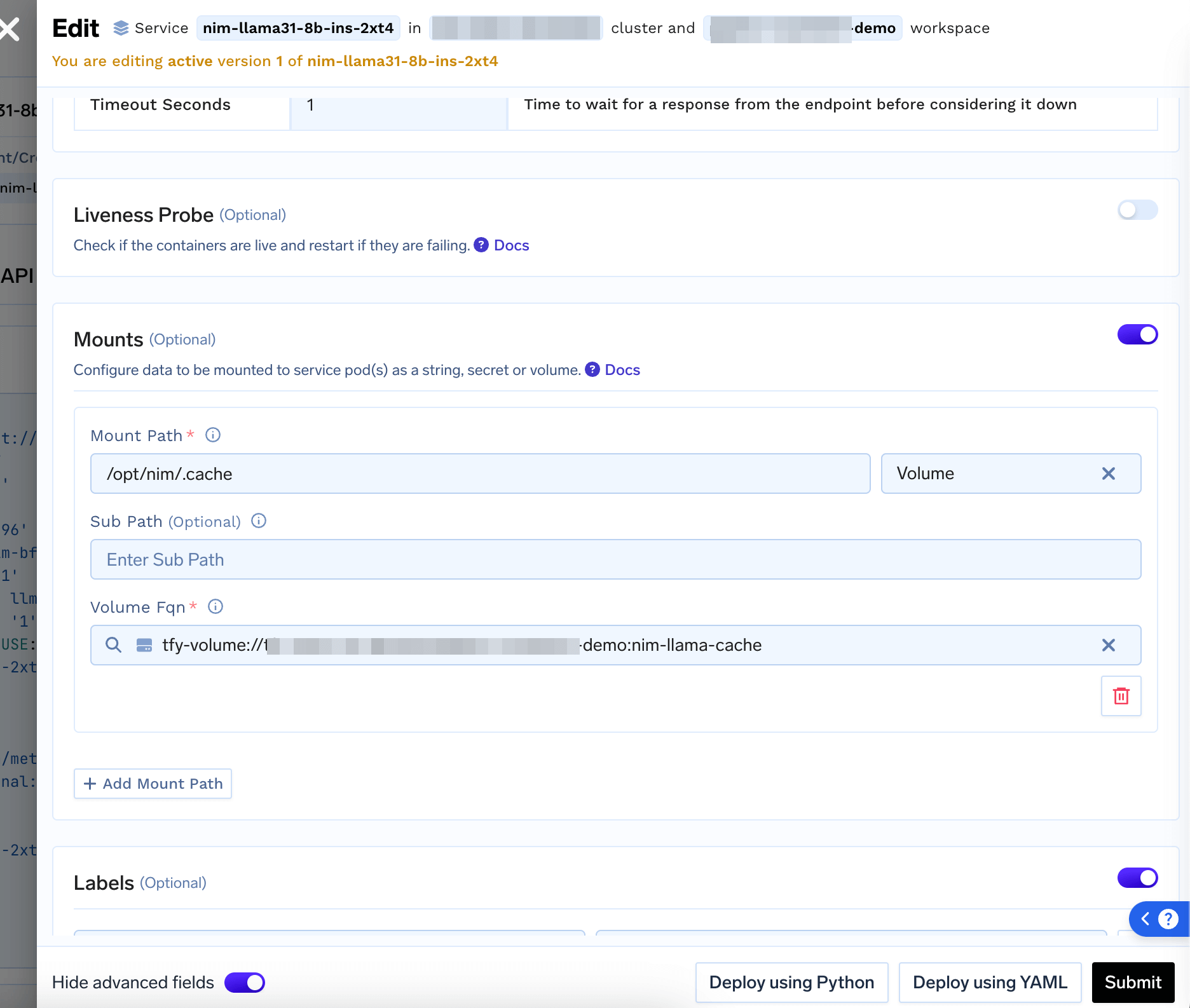
(Optional) Caching NIM Model to External Volume
To avoid re-downloading Model on every restart, you can Create a Volume and Mount the Volume at/opt/nim/.cache
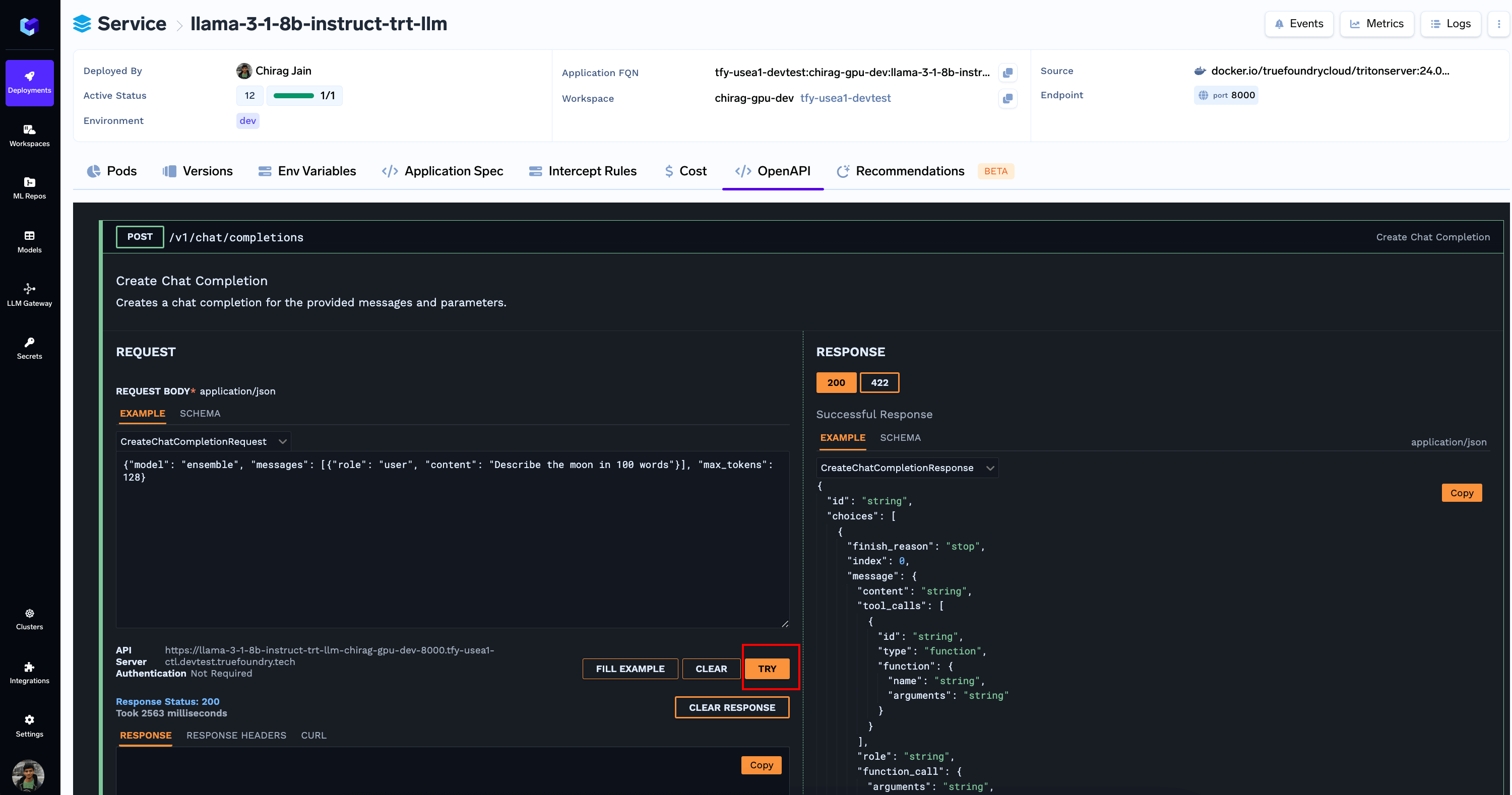
Running Inferences
You can now run inferences via the OpenAPI tab. You can also Add the Model to LLM Gateway using the button on the top