| Resource | Unit | Description |
|---|---|---|
| CPU | CPU cores | This defines the processing power required by the application in terms of CPU cores. 1 CPU unit is equivalent to 1 virtual core. It’s possible to ask for fractional CPU resources like 0.1 or even 0.01 (minimum is 0.01). While defining CPU, you will need to specify requests and limits. The number you define in the CPU request will always be reserved for the application. Your application can occasionaly take more CPU than what is requestes till the CPU limit, but not beyond that. Any value above the request is opportunistic and not guaranteed to be available. For e.g, if CPU request is 0.5 and limit is 1, it means that the application has 0.5 CPU reserved for itself. CPU usage can go upto 1 if there is spare CPU available on the machine - else it will be throttled. |
| Memory | Megabytes (MB) | Defined as an integer and the unit is Megabytes. So a value of 1 means 1 MB of memory and 1000 means 1GB of memory. You need to specify memory requests and limits. The number you define in the memory request will always be reserved for the application. Your application can occasionaly take more memory than what is requested till the memory limit. Any value above the request is opportunistic and not guaranteed to be available. If the application takes up more memory than the limit, then the application will be killed and restarted. For e.g, if memory request is 500 MB and limit is 1000 MB, it means that you application will always have 500MB of RAM. You can have spikes of memory usage till 1 GB, beyond which the application will be killed and restarted. |
| Ephemeral Storage | Megabytes (MB) | Temporary disk space to keep code, artifacts, etc which is lost when the pod is terminated. Defined as an integer and the unit is Megabytes. A value of 1 means 1 MB of disk space and 1000 means 1GB of disk space. You need to specify ephemeral Storage requests and limits. If you specify 1 GB as request and 5 GB as limit, you will have guaranteed access to 1GB of disk space. You can go upto 5GB in case there is disk left on the machine, but we shouldn’t rely on this. If the application tries to take up more than 5GB, the application will be killed. |
| GPU | GPU-Type and Count | This allows you to specify which GPU you want to provision for your application (GPUs can be of the following types: K80, P4, P100, V100, T4, A10G, A100_40GB, A100_80GB, etc.). Secondly, you need to specify the GPU-Count. Please note that if you ask for GPU count as 2 and type as A100, you will get a machine with atleast 2 A100 GPU cards. Its possible in some cloud providers that one machine has 4 A100 GPU cards. In this case, your application will use 2 of the 4 GPU cards and another application can use the rest 2 cards. |
| Shared Memory | Megabytes (MB) | Shared memory size is needed for data sharing between processes. This is useful in certain scenarios, for example, Torch Dataloaders rely on shared memory to efficiently share data between multiple workers during training. Defined as an integer and the unit is Megabytes. A value of 1 means 1 MB of shared memory and 1000 means 1GB of shared memory. In case your use-case requires Shared memory, and the usage exceeds the Shared memory size, your applications’ replica will get killed. |
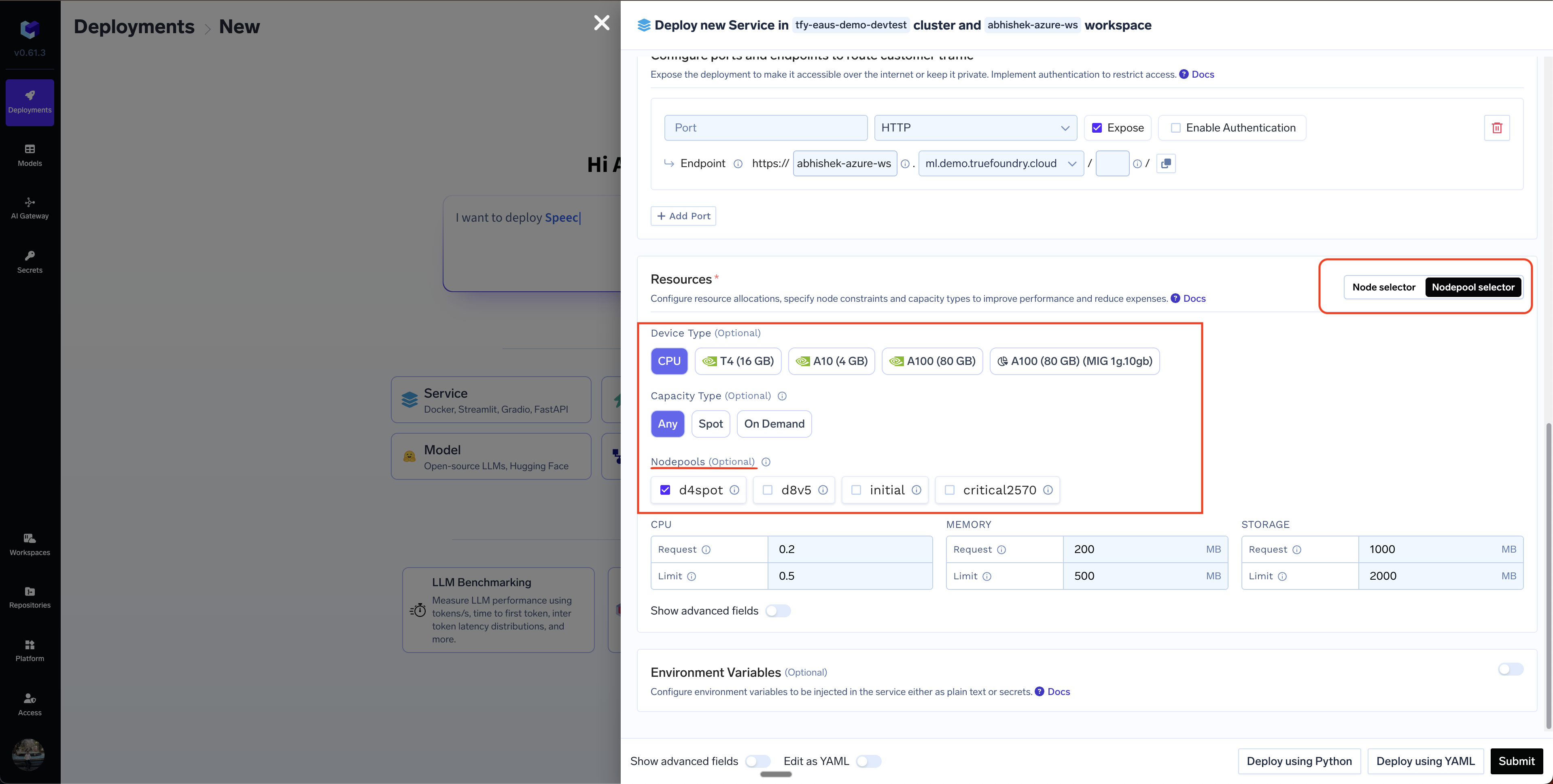
Setting Resources for your application
You can select the resources from theResources section in the deployment form.
- Choose CPU or GPU along with its type.
- Fill up the CPU, Memory and Ephemeral Storage request and limit fields.
- Select the capacity type - we have the following options here:
On-demand- This will deploy the application on on-demand instances.Spot- This will deploy the application on spot instances.Prefer Spot (with fallback on On-demand)- This will try to deploy the application on spot instances. If the spot instances are not available, it will bring up the application on on-demand instances. If a spot instance is preempted, we will try to replace it with another spot instance, failing which, it will be shifted to an on-demand instance.
What are On-demand and Spot Instances?
What are On-demand and Spot Instances?
Spot and on-demand instances are two types of instances offered by cloud providers like AWS, GCP, and Azure.On-demand instances are the standard, pay-as-you-go compute resources offered by cloud providers. You pay for the compute time you use, with no long-term commitments.Spot instances are spare compute capacity offered by cloud providers at a significantly discounted price (often up to 90% off the on-demand price). However, the catch is that the cloud provider can reclaim these instances with minimal notice (typically a 2-minute warning) if demand for that instance type increases. The spot prices also fluctuate based on demand and supply.Here’s an example of a snapshot of the spot vs on-demand prices of a few instance types in AWS, GCP and Azure:
- AWS
- GCP
- Azure
| Instance Type | On-Demand Price (approx.) | Spot Price (approx.) | Discount (%) |
|---|---|---|---|
| t3.medium | $0.0416/hr | ~0.02/hr | ~50-75% off |
| m6i.large | $0.077/hr | ~0.03/hr | ~60-75% off |
| c6i.large | $0.085/hr | ~0.03/hr | ~65-75% off |
| r6i.large | $0.113/hr | ~0.04/hr | ~65-70% off |
| i4.large | $0.15/hr | ~0.05/hr | ~65-70% off |
Which capacity type option should I choose?
Which capacity type option should I choose?
Spot instances are a good option for nodes when:
- You are running multiple replicas of a service - hence the chances of all the spot machines going down at the same time is extremely low.
- You are running a long running training job and saving checkpoints which allows you to resume the training from the last checkpoint in case the machine is taken away.
- Your service can handle going down and restarting on a different node.
How does TrueFoundry handle spot interruptions?
How does TrueFoundry handle spot interruptions?
Truefoundry’s handling of the spot instances depends on the cloud provider. Here’s what happens in each of the cloud providers:
- AWS
- GCP
- Azure
Truefoundry uses Karpenter to orchestrate spot and on-demand instance provisioning. Karpenter automatically monitors the availability of spot instances and can bring up another instance in case a spot instance is taken away. We configure Karpenter to prefer a balance between cost and availability - so that we don’t just prioritize the cheapest option always which might have a high rate of preemption. AWS also sends a signal 2 minutes before a spot instance is taken away. Truefoundry configures Karpenter to start bringing up a new instance the moment AWS sends this signal to reduce the node provisioning time to a few seconds.Because of this, the downtime of a pod to switch to another node is actually just a few seconds (depending on docker image download time) and hence spot instance based scheduling works quite well in AWS. We have also seen a average uptime of around 12 hours for spot instances - although this varies based on the region and the instance type.
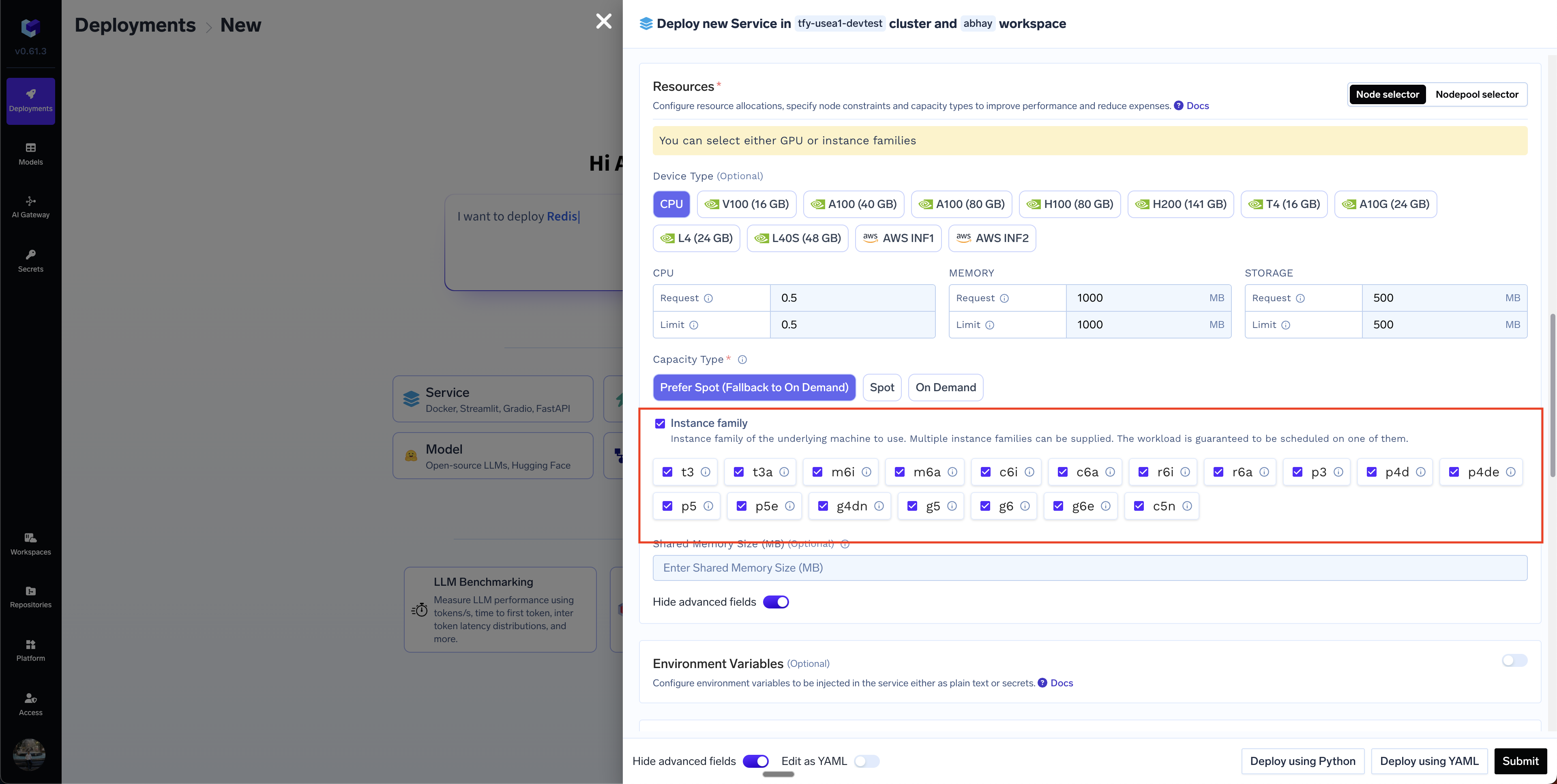
Advanced Options
Selecting a specific instance type
You can select an instance type by clicking on theAdvanced Options button in Resources section and then selecting Instance Family option.
Selecting a Kubernetes nodepool
If you are using the nodepools in Kubernetes and want to specifically select a certain nodepool to deploy your application, you can do so by clicking on theNodepool Selector option and then selecting the nodepool. We automatically parse the possible options from the available nodepools to show you the filtered set of nodepools - for e.g. if you select Spot, it will filter the set of nodepools that have spot instances.