GPT-5-Codex is now available! You can access GPT-5-Codex through TrueFoundry AI Gateway. Follow the setup steps below to get started.
What is Codex?
Codex is the official command-line interface (CLI) tool for OpenAI, providing a streamlined way to interact with OpenAI’s language models directly from your terminal. With Truefoundry LLM Gateway integration, you can route your Codex requests via Gateway.Key Features of OpenAI Codex CLI
- Terminal-Native AI Interactions: Chat with AI models directly from your terminal without switching contexts
- Intelligent Code Generation: Generate code snippets, functions, and programs across multiple programming languages using natural language prompts
- Streaming and Interactive Sessions: Real-time streaming responses enable dynamic, conversation-like interactions for code development
Prerequisites
Before integrating Codex with TrueFoundry, ensure you have:- TrueFoundry Account: Create a Truefoundry account with at least one model provider and generate a Personal Access Token by following the instructions in Generating Tokens. For a quick setup guide, see our Gateway Quick Start
- Codex Installation: Install the Codex CLI on your system
- Routing Configuration: Setup routing configuration for your desired models (see Setup Process section below)
Why Routing Configuration is Necessary
Codex has internal logic that sendsthinking tokens to certain models during processing. This works well with standard OpenAI model names (like gpt-5), but causes compatibility issues with Truefoundry’s fully qualified model names (like openai-main/gpt-5 or azure-openai/gpt-5).
When Codex encounters fully qualified model names directly, it incorrectly sends thinking tokens, which can cause unexpected behavior.
The Solution: Routing configuration allows you to:
- Use standard model names in your Codex commands (e.g.,
gpt-5) - Have Truefoundry Gateway automatically route requests to the fully qualified target model (e.g.,
openai-main/gpt-5)
Setup Process
1. Configure Environment Variables
To connect Codex with Truefoundry LLM Gateway, set these environment variables:TFY_API_KEY with your actual Truefoundry API key and {controlPlaneUrl} with your Truefoundry control plane URL.
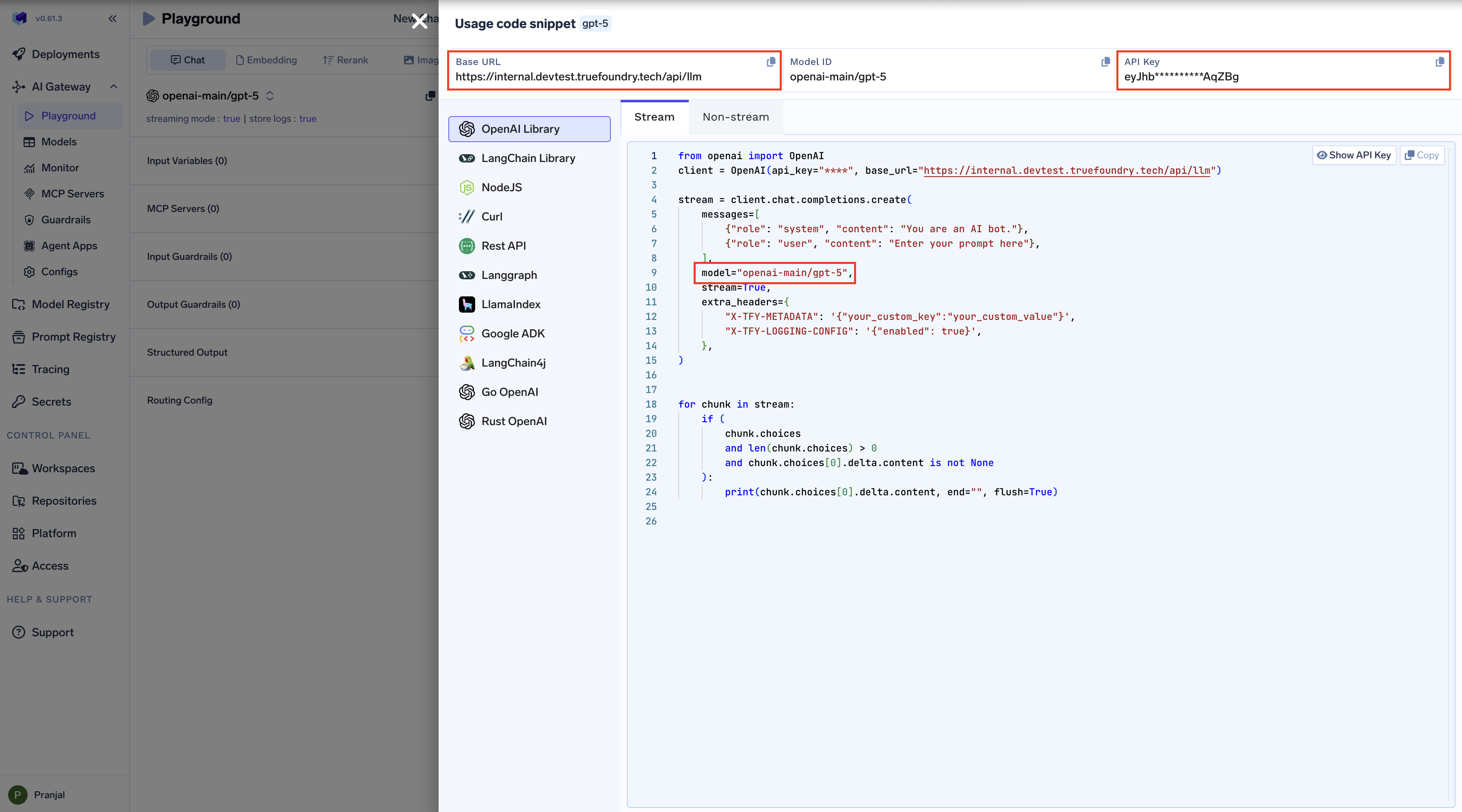
Get Base URL and Model Name from Unified Code Snippet
Tip: Add these lines to your shell profile (
.bashrc, .zshrc, etc.) to make the configuration persistent across terminal sessions.2. Setup Routing Configuration
Create a routing configuration to route your requests to specific model providers: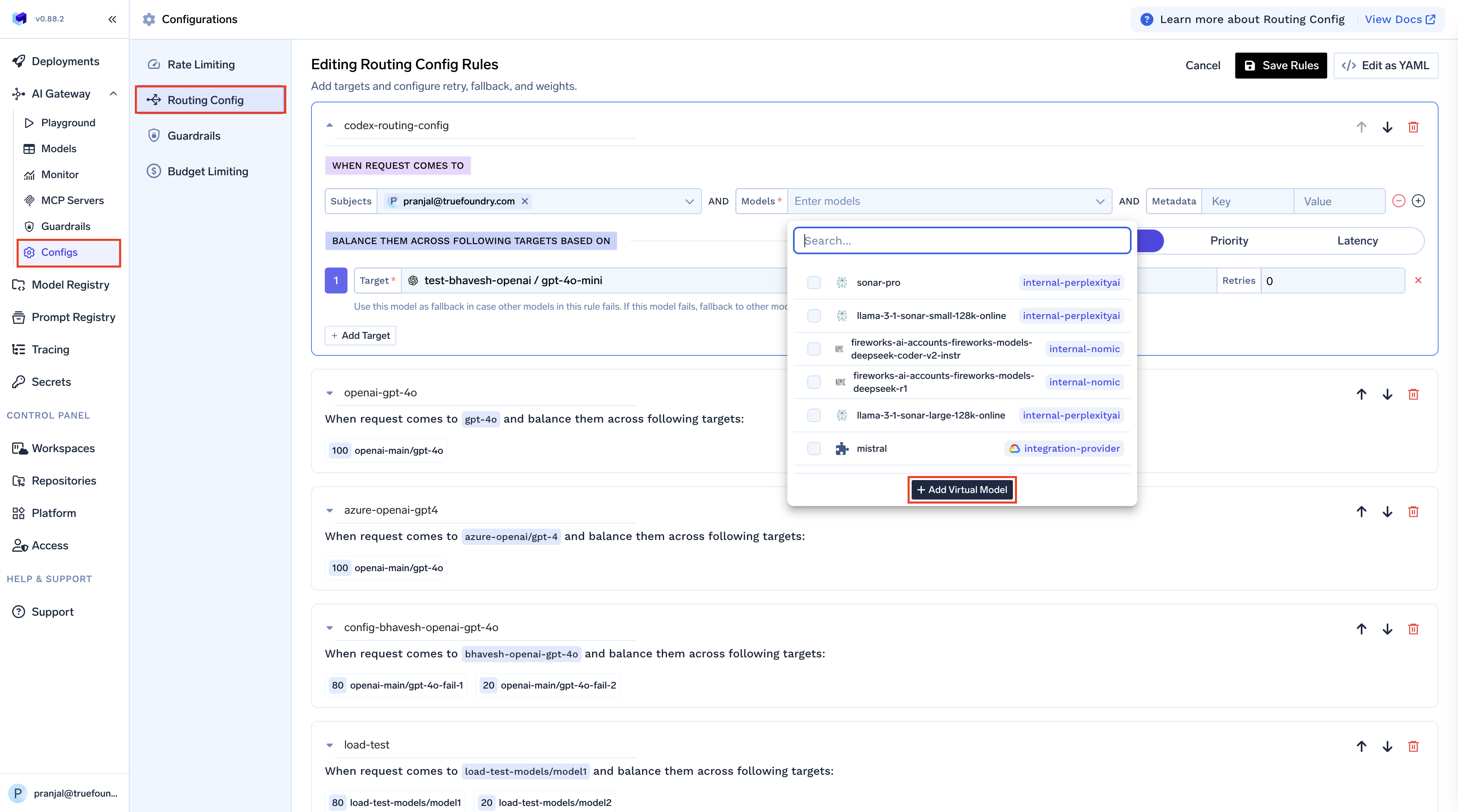
gpt-5 through Codex, your request will be routed to the openai-main/gpt-5 model with 100% of the traffic weight.
Add your desired model name (e.g.,
gpt-5) as the virtual model, and set the target to the fully qualified model name you want to use (e.g., openai-main/gpt-5).Usage Examples
Basic Usage with Load Balanced Models
Always specify the model defined in your routing configuration to ensure your requests go through the Truefoundry Gateway:Advanced Options with Gateway Routing
Understanding Load Balancing
When you use Codex with--model gpt-5, your request is automatically routed according to your routing configuration. In the example above, all requests to gpt-5 are sent to openai-main/gpt-5 with 100% of the traffic.
You can also create more sophisticated routing rules with multiple targets and different weights: