What is OpenAI Swarm?
OpenAI Swarm is an experimental framework for building, orchestrating, and deploying multi-agent systems. It provides a lightweight, scalable, and highly customizable approach to coordinating multiple AI agents that can work together to solve complex tasks through handoffs and collaboration.Key Features of OpenAI Swarm
- Multi-Agent Coordination: Build teams of specialized agents that can transfer tasks between each other and collaborate on complex workflows
- Lightweight Framework: Minimal overhead with a simple API that makes it easy to define agents, their capabilities, and coordination patterns
- Function Calling: Agents can be equipped with custom functions and tools to interact with external systems and APIs
- Contextual Handoffs: Seamless transfer of context and conversation state between agents based on user needs and agent capabilities
Prerequisites
Before integrating OpenAI Swarm with TrueFoundry, ensure you have:- TrueFoundry Account: Create a Truefoundry account and follow our Gateway Quick Start
- OpenAI Swarm Installation: Install OpenAI Swarm using pip:
pip install git+https://github.com/openai/swarm.git - Load Balance Configuration: Setup load balancing configuration for your desired models (see Setup Process section below)
Important: Model Routing Configuration
Setup Process
1. Basic Setup with OpenAI Swarm
You will get your ‘truefoundry-api-key’, ‘truefoundry-gateway-url’ and model name directly from the unified code snippet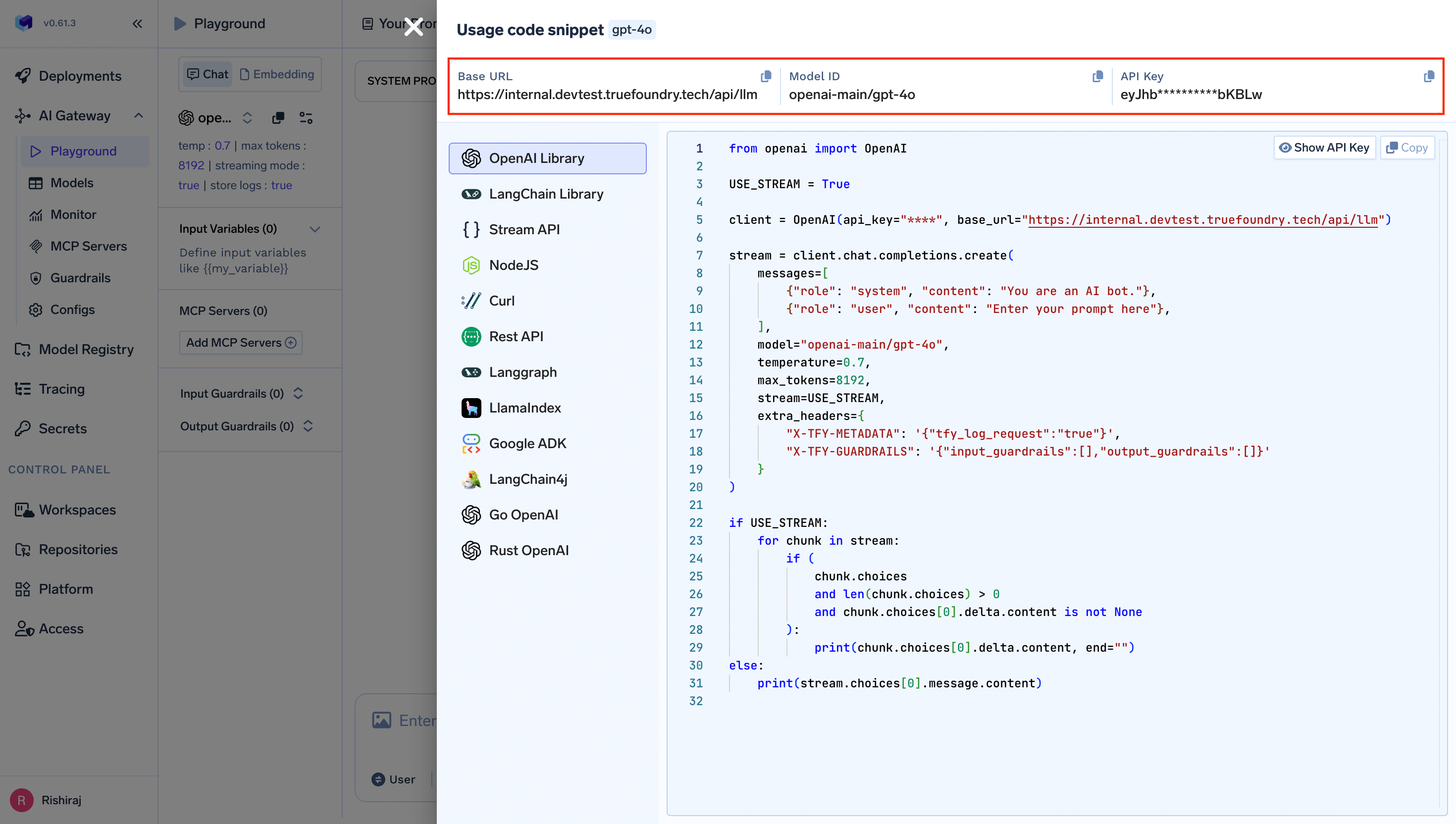
your-truefoundry-api-keywith your actual TrueFoundry API keyyour-truefoundry-base-urlwith your TrueFoundry Gateway URL
2. Configure Model Routing
Create a load balancing configuration to route standard OpenAI model names to your TrueFoundry providers:3. Environment Variables Configuration
For persistent configuration across your Swarm applications, set these environment variables:Observability and Governance
Monitor your OpenAI Swarm applications through TrueFoundry’s metrics tab: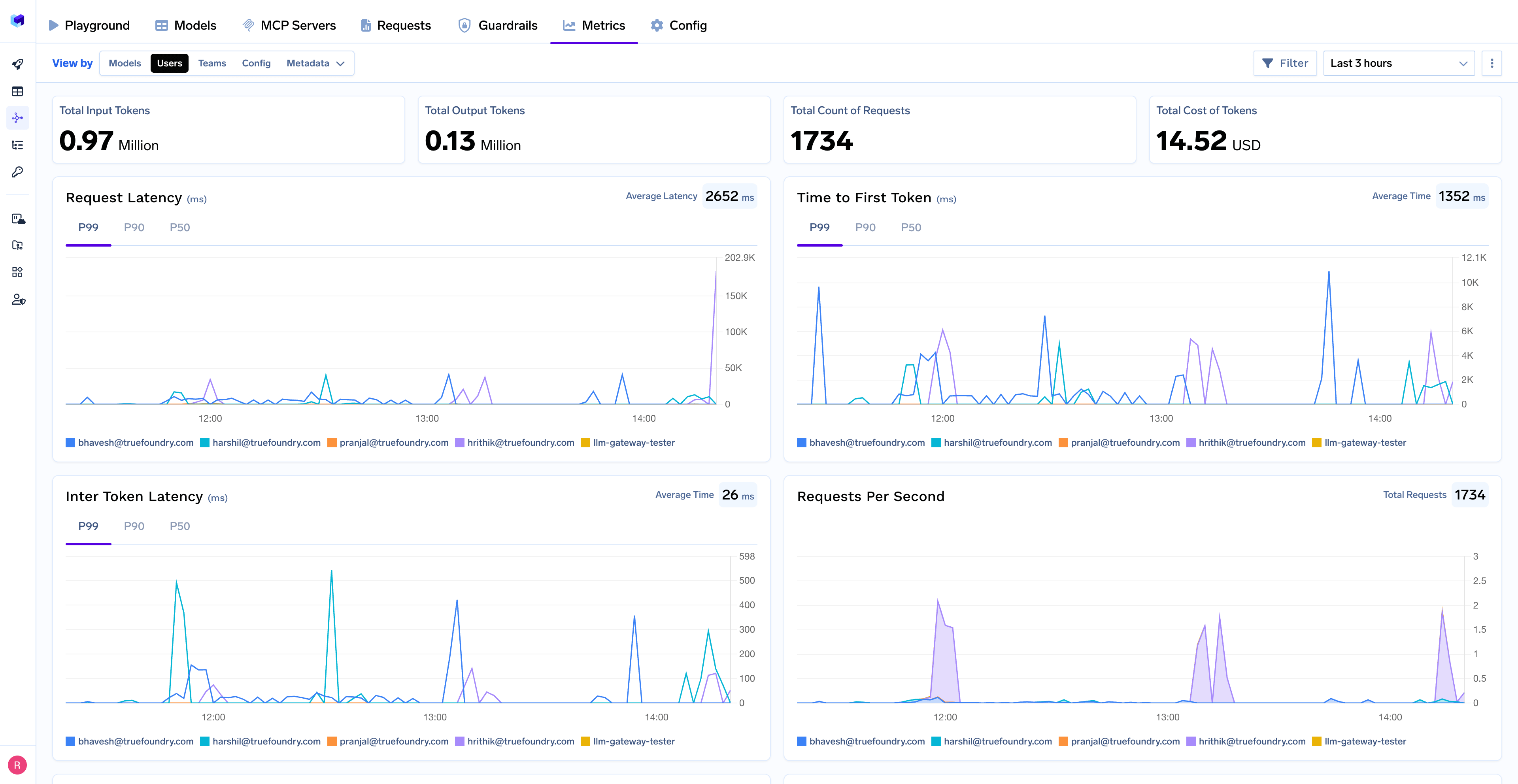
- Performance Metrics: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
- Cost and Token Usage: Gain visibility into your application’s costs with detailed breakdowns of input/output tokens and the associated expenses for each model
- Usage Patterns: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
- Agent Performance: Monitor individual agent performance and handoff patterns
- Rate limit and Load balancing: Set up rate limiting, load balancing and fallback for your models