The tfy-llm-gateway provides detailed, Prometheus-compatible metrics to monitor the health, performance, and cost of your LLM applications with Grafana.
You will be able to export metrics only if the gateway is hosted on your end.
Setup
The gateway exposes a /metrics endpoint that can be scraped by your Prometheus instance. This is the standard way to collect metrics.
Alternatively, if your setup uses an OpenTelemetry Collector, you can configure the gateway to push metrics directly. To do this, set the following environment variables for the tfy-llm-gateway service:
ENABLE_OTEL_METRICS: Set to "true".OTEL_EXPORTER_OTLP_METRICS_ENDPOINT: The endpoint of your OTEL metrics exporter.OTEL_EXPORTER_OTLP_METRICS_HEADERS: (Optional) Headers for authentication.
Example Push Configuration
ENABLE_OTEL_METRICS: 'true'
OTEL_EXPORTER_OTLP_METRICS_ENDPOINT: https://<prometheus-host>/api/v1/otlp/v1/metrics
OTEL_EXPORTER_OTLP_METRICS_HEADERS: 'Authorization=Bearer <your-token>'
LLM_GATEWAY_METADATA_LOGGING_KEYS: '["customer_id", "request_type"]'
Labels
Labels provide dimensions for filtering and aggregating metrics.
| Label | Description |
|---|
model_name | The name of the model used for the request (e.g., gpt-4o). |
tenant_name | The name of the tenant associated with the request. |
username | The user associated with the request. |
tool_name | The name of the tool called by an agent (only for agent metrics). |
llm_gateway_metadata_* | Custom labels generated from LLM_GATEWAY_METADATA_LOGGING_KEYS. For example, customer_id becomes llm_gateway_metadata_customer_id. |
Gateway Metrics
These metrics provide an overview of the gateway’s performance and usage.
Token Usage and Cost
| Metric Name | Type | Description | Labels |
|---|
llm_gateway_input_tokens | Counter | The number of input tokens processed. | model_name, tenant_name, username, llm_gateway_metadata_* |
llm_gateway_output_tokens | Counter | The number of output tokens generated. | model_name, tenant_name, username, llm_gateway_metadata_* |
llm_gateway_request_total_cost | Counter | The estimated cost of the tokens used. | model_name, tenant_name, username, llm_gateway_metadata_* |
Latency
| Metric Name | Type | Description | Labels |
|---|
llm_gateway_request_processing_ms | Histogram | The total time taken to process a request. | model_name, tenant_name, username, llm_gateway_metadata_* |
llm_gateway_first_token_latency_ms | Histogram | The time to receive the first token from the model. | model_name, tenant_name, username, llm_gateway_metadata_* |
llm_gateway_inter_token_latency_ms | Histogram | The average time between subsequent tokens in a stream. | model_name, tenant_name, username, llm_gateway_metadata_* |
Errors and Failures
| Metric Name | Type | Description | Labels |
|---|
llm_gateway_request_model_inference_failure | Counter | The number of failed model inference requests. | model_name, tenant_name, username, llm_gateway_metadata_* |
llm_gateway_config_parsing_failures | Counter | The number of configuration parsing errors. | model_name, tenant_name, username, llm_gateway_metadata_* |
Configuration Metrics
| Metric Name | Type | Description | Labels |
|---|
llm_gateway_rate_limit_requests_total | Counter | Total number of requests that hit rate limits. | model_name, tenant_name, username, ruleId, llm_gateway_metadata_* |
llm_gateway_load_balanced_requests_total | Counter | Total number of requests that were load balanced. | model_name, tenant_name, username, ruleId, llm_gateway_metadata_* |
llm_gateway_fallback_requests_total | Counter | Total number of requests that were served by fallback. | model_name, tenant_name, username, ruleId, llm_gateway_metadata_* |
llm_gateway_budget_requests_total | Counter | Total number of requests that hit budget limits. | model_name, tenant_name, username, ruleId, llm_gateway_metadata_* |
llm_gateway_guardrails_requests_total | Counter | Total number of requests that hit guardrails. | model_name, tenant_name, username, ruleId, llm_gateway_metadata_* |
Agent-Specific Metrics
These metrics are for monitoring agent-based interactions.
| Metric Name | Type | Description | Labels |
|---|
llm_gateway_agent_request_duration_ms | Histogram | The total duration of an agent request. | model_name, status, tenant_name, username |
llm_gateway_agent_request_tool_calls_total | Histogram | The number of tool calls in a single agent request. | model_name, tenant_name, username |
llm_gateway_agent_request_iteration_limit_reached_total | Counter | The number of requests hitting the iteration limit. | model_name, iteration_limit, tenant_name, username |
llm_gateway_agent_llm_latency_ms | Histogram | The latency of LLM calls within an agent. | model_name, iteration_number, status, tenant_name, username |
llm_gateway_agent_tool_calls_total | Counter | The total number of tool calls made by agents. | tool_name, integration_fqn, tenant_name, username |
llm_gateway_agent_tool_latency_ms | Histogram | The execution time of each tool call. | tool_name, integration_fqn, status, tenant_name, username |
llm_gateway_agent_mcp_connect_latency_ms | Histogram | The time taken to connect to an MCP server and fetch tools. | integration_fqn (or server_url), tenant_name, username |
Grafana Integration
Our pre-built Grafana dashboard helps you monitor the LLM Gateway. It is organized into several views so you can analyze gateway activity from different perspectives.
Note
You can find the Grafana Dashboard JSON at the following link:
https://github.com/truefoundry/infra-charts/blob/main/charts/tfy-grafana/dashboards/llm-gateway-metrics.json
Dashboard Views
Our pre-built Grafana dashboard is organized into several views to help you analyze gateway activity from different perspectives:
- Model View: Groups metrics by
model_name to compare model performance.
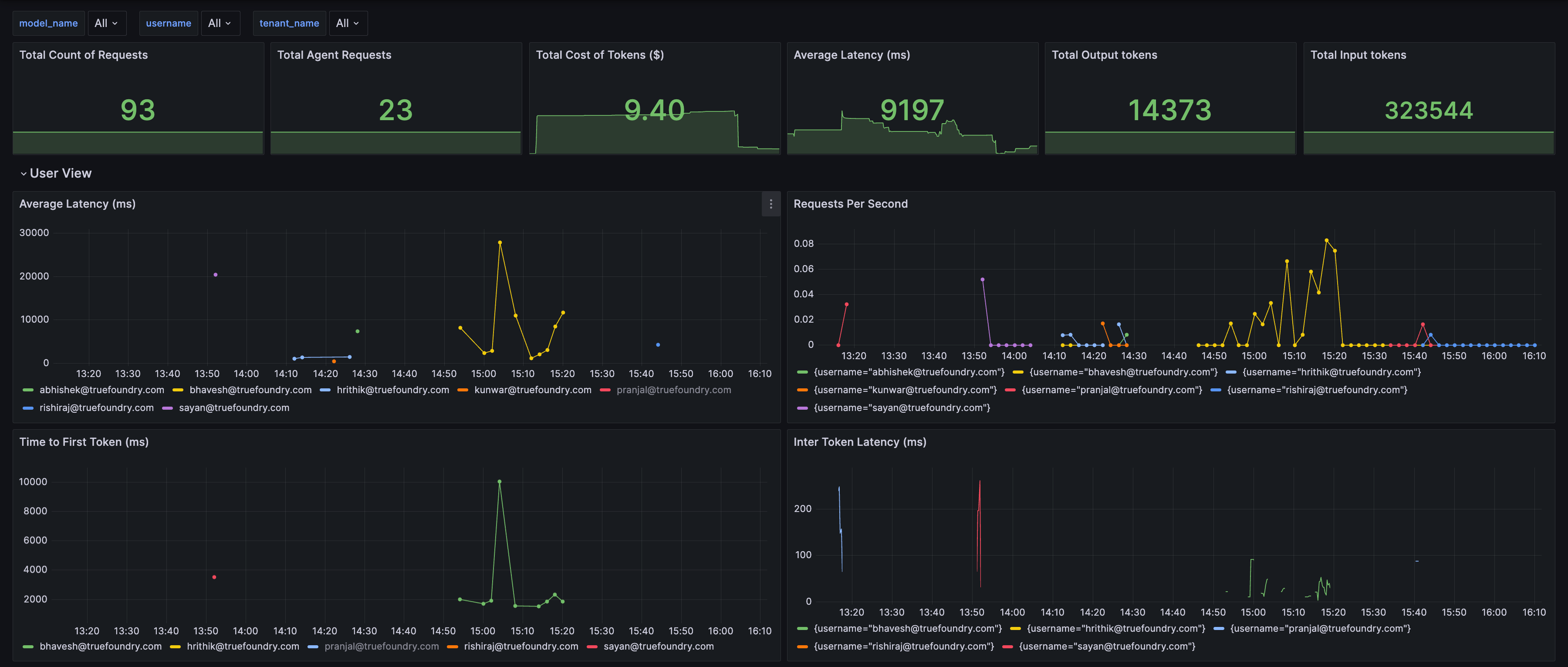
- User View: Groups metrics by
username to monitor usage patterns.
- Config View: Groups metrics by
ruleId to show the impact of gateway configurations.
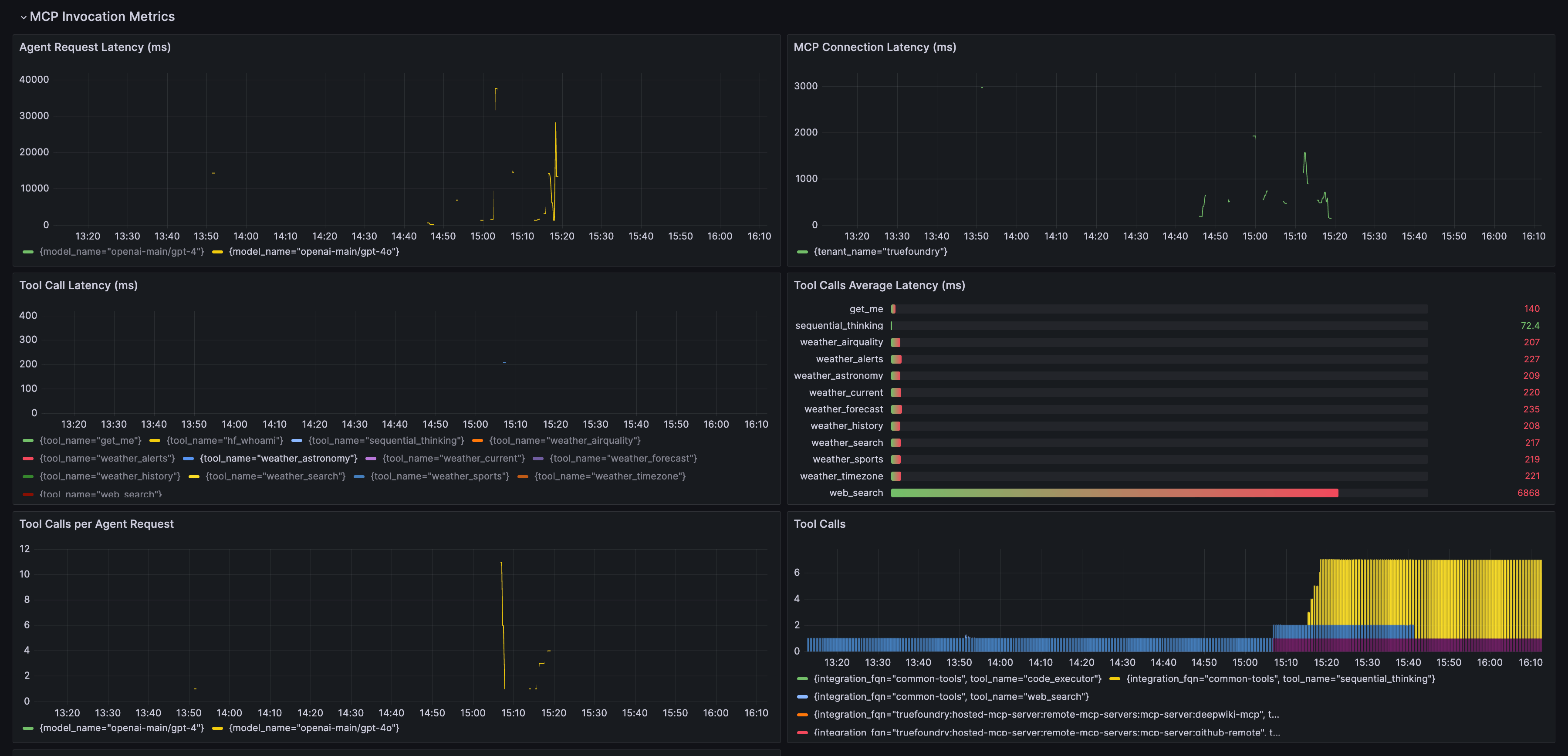
- MCP Invocation Metrics: Contains all agent-related metrics, including MCP server performance and tool call latency.
Importing the Dashboard
- Copy the JSON dashboard definition below.
- In your Grafana instance, navigate to Dashboards > Import.
- Paste the JSON into the Import via panel json text area.
- Click Load.
- On the next screen, select your Prometheus data source.
- Click Import.
Customizing the Dashboard
The pre-built dashboard includes filters for model_name, tenant_name, and username. If you use custom metadata labels (via LLM_GATEWAY_METADATA_LOGGING_KEYS), you can add them as filters to your dashboard for more granular analysis.
Add a Dashboard Variable
For example, to filter by a custom metadata key like customer_id, add a new variable to your dashboard settings:
- Go to Dashboard settings > Variables.
- Click New variable.
- Configure the variable as follows:
- Name:
customer_id
- Type:
Query
- Label:
Customer ID
- Data source: Your Prometheus source
- Query:
label_values(llm_gateway_input_tokens, llm_gateway_metadata_customer_id)
- Multi-value: Enabled
- Include All option: Enabled
Use the Variable in Queries
Update your panel queries to use the new variable. For example, to filter input tokens by customer_id:
sum(rate(llm_gateway_input_tokens{model_name=~"$model_name", tenant_name=~"$tenant_name", llm_gateway_metadata_customer_id=~"$customer_id"}[5m]))