What is Langfuse?
Langfuse is an open source LLM engineering platform that helps teams trace LLM calls, monitor performance, and debug issues in their AI applications.Key Features of Langfuse
- Comprehensive LLM Tracing: Langfuse automatically captures detailed traces of all LLM interactions, including input prompts, outputs, token usage, latency, and costs. This provides complete visibility into your AI application’s behavior and helps identify performance bottlenecks and optimization opportunities.
- Real-time Analytics and Monitoring: Built-in analytics dashboard provides real-time insights into model performance, usage patterns, and costs across your entire LLM stack. Monitor metrics like response times, token consumption, error rates, and user satisfaction to make data-driven decisions.
- Debug and Evaluation Tools: Advanced debugging capabilities help identify and resolve issues in LLM applications through detailed trace inspection, prompt management, and automated evaluation workflows that ensure consistent model performance and output quality.
Prerequisites
Before integrating Langfuse with TrueFoundry, ensure you have:- TrueFoundry Account: Create a Truefoundry account with atleast one model provider and generate a Personal Access Token by following the instructions in Generating Tokens
- Langfuse Account: Sign up for a free Langfuse Cloud account or self-host Langfuse
Integration Guide
Step 1: Install Dependencies
Install the required packages for TrueFoundry and Langfuse integration:Step 2: Set Up Environment Variables
Configure your Langfuse API keys. Get these keys from your Langfuse project settings:Step 3: Configure Langfuse OpenAI Drop-in Replacement
First, get the base URL and model name from your TrueFoundry AI Gateway:- Navigate to AI Gateway Playground: Go to your TrueFoundry AI Gateway playground
- Access Unified Code Snippet: Use the unified code snippet
- Copy Base URL: You will get the base path from the unified code snippet
- Copy model name: You will get the model name from the same code snippet (ensure you use the same model name as written)
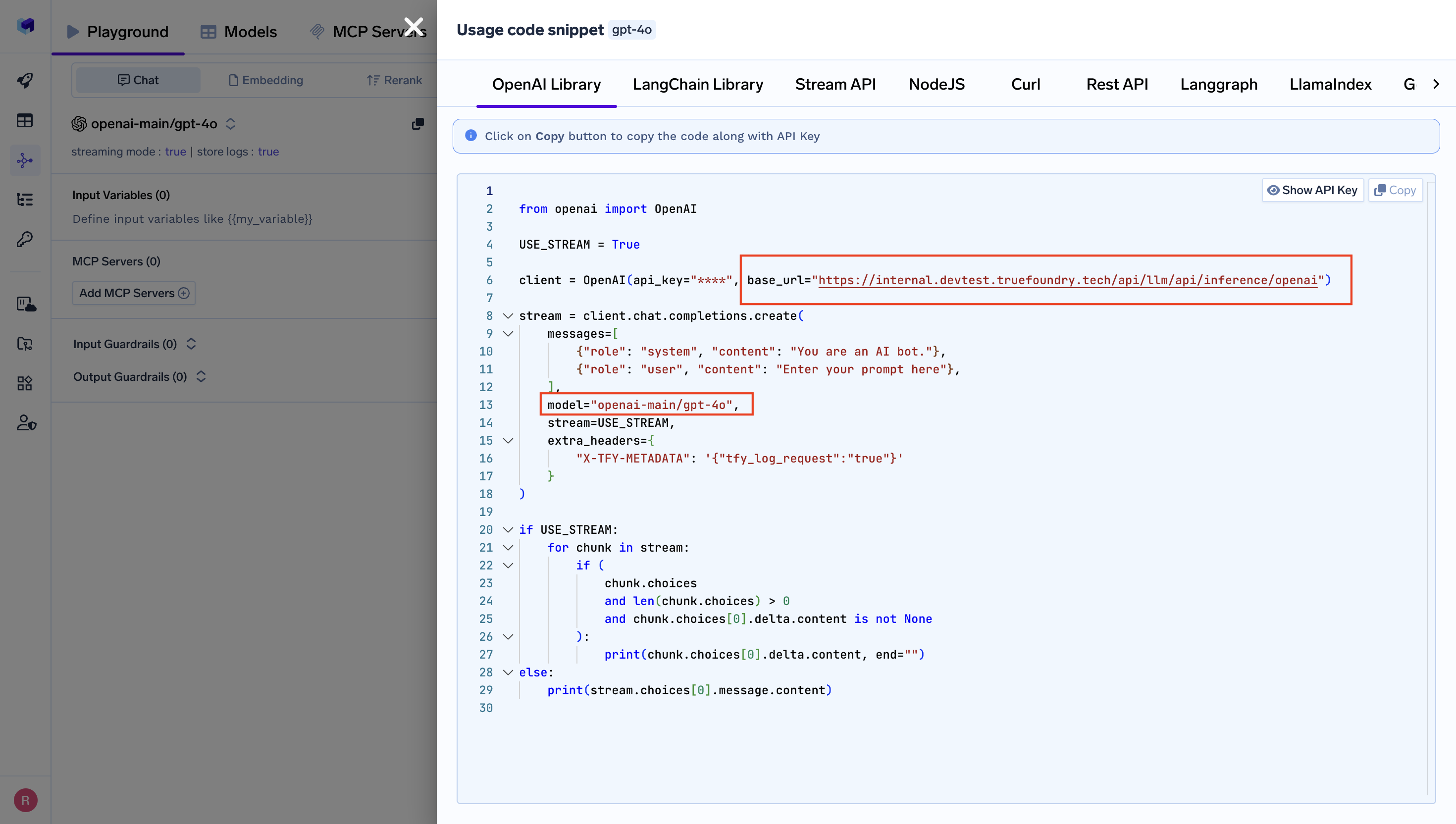
Get Base URL from Unified Code Snippet
Step 4: Run an Example
Execute a sample request to test the integration:Step 5: View Traces in Langfuse
After running your code, log in to your Langfuse dashboard to view detailed traces including:- Request Parameters: Model, temperature, max tokens, and other configuration
- Response Content: Full response text and metadata
- Performance Metrics: Token usage, latency, and cost information
- Gateway Information: TrueFoundry-specific routing and processing details
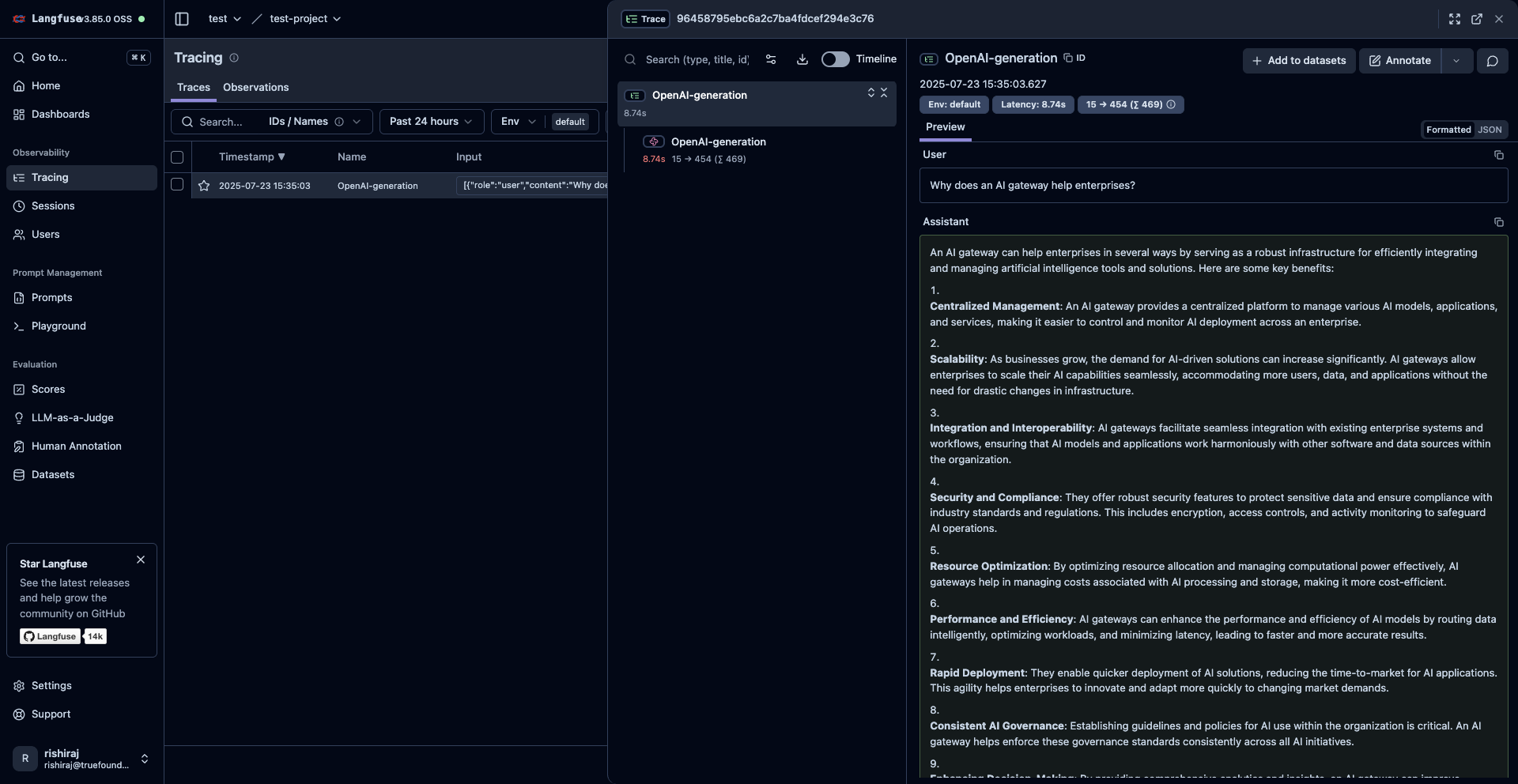
Langfuse Trace Dashboard
Advanced Integration with Langfuse Python SDK
Enhance your observability by combining the automatic tracing with additional Langfuse features.Using the @observe Decorator
The@observe() decorator automatically wraps your functions and adds custom attributes to traces:
Using Context Manager
For more granular control, use context managers to wrap specific code sections:Troubleshooting
Common Issues
- Authentication Errors: Verify your TrueFoundry API key and Langfuse credentials
- Missing Traces: Ensure
langfuse.flush()is called in short-lived applications - Model Not Found: Check that the model is available in your TrueFoundry Gateway
- Network Issues: Verify your TrueFoundry base URL is correctly formatted
Debug Mode
Enable debug logging for troubleshooting:Next Steps
With Langfuse integration enabled, explore these advanced features:- Prompt Management: Version control your prompts
- Evaluation Workflows: Set up automated quality checks
- Custom Dashboards: Create specialized monitoring views
- Data Exports: Export data for further analysis
- Playground Testing: Test prompts before deployment