What is LangChain?
LangChain is a framework for developing applications powered by large language models (LLMs). It provides a comprehensive suite of tools and integrations that streamline the entire lifecycle of LLM applications, from development to deployment and monitoring.Key Features of LangChain
- Modular Components: Offers a range of building blocks including chains, agents, prompt templates, and memory modules that can be composed together to create complex LLM applications
- Extensive Integrations: Supports integrations with various LLM providers, embedding models, vector stores, and external tools, facilitating seamless connectivity within the AI ecosystem
- Production-Ready Tools: Includes LangGraph for building stateful agents and LangSmith for monitoring and evaluating applications, ensuring robust deployment and maintenance of LLM-powered solutions
Quickstart Guide
TrueFoundry is compatible with the OpenAI signature, so you can connect to TrueFoundry’s unified LLM gateway through theChatOpenAI interface.
Installation & Setup
- Sign up for a TrueFoundry account
- Follow the steps here in Quick start and generate a Personal Access Token (PAT)
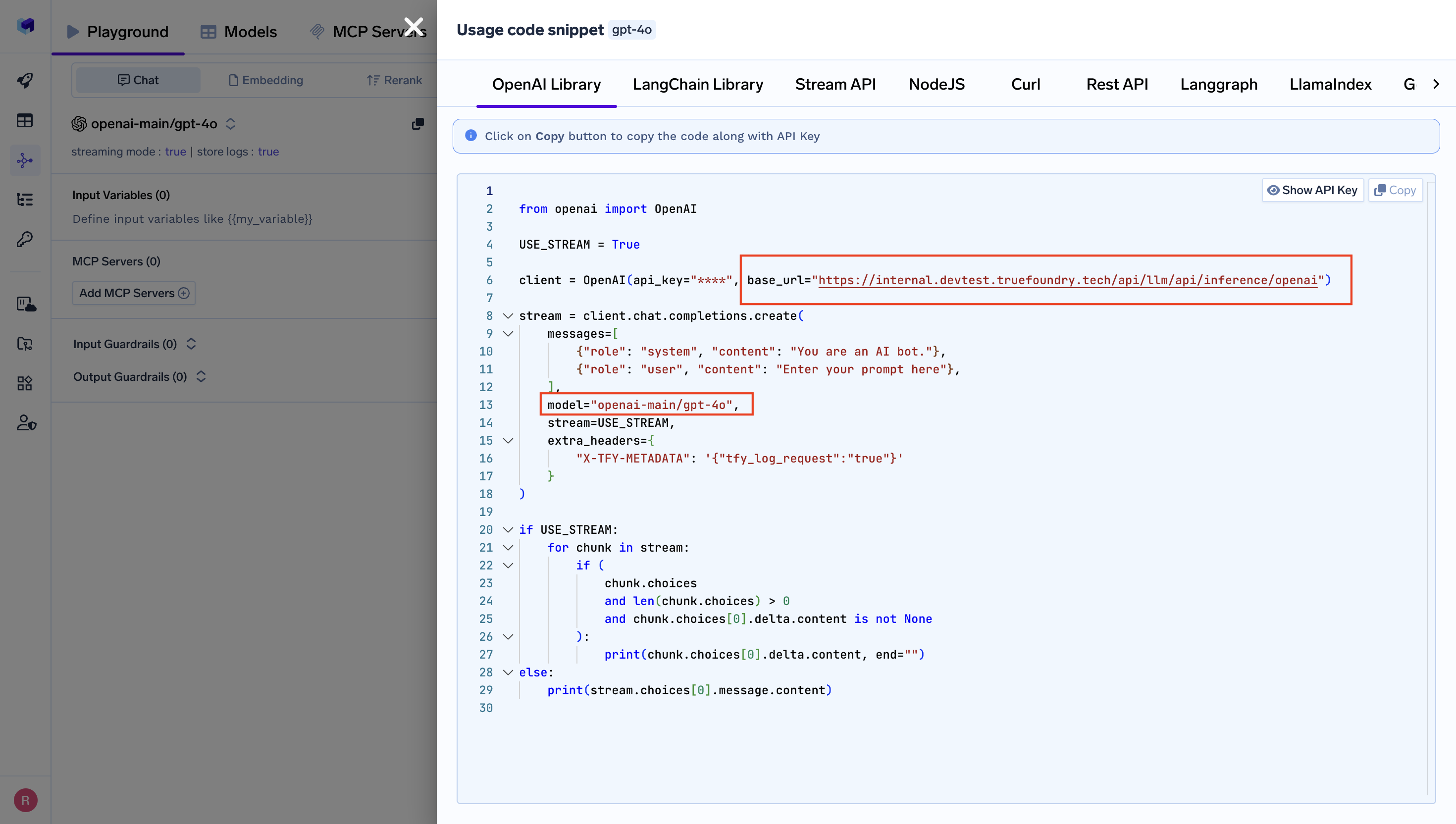
Get Base URL and Model Name from Unified Code Snippet
- Set the
base_urlto your TrueFoundry endpoint - Set the
api_keyto your TRUEFOUNDRY_PAT - Use TrueFoundry model names in the format
provider-main/model-name
Installation
Basic Setup
Connect to TrueFoundry by updating theChatOpenAI model in LangChain:
Advanced Example with LangGraph
Observability and Governance
Monitor your LangChain applications through TrueFoundry’s metrics tab: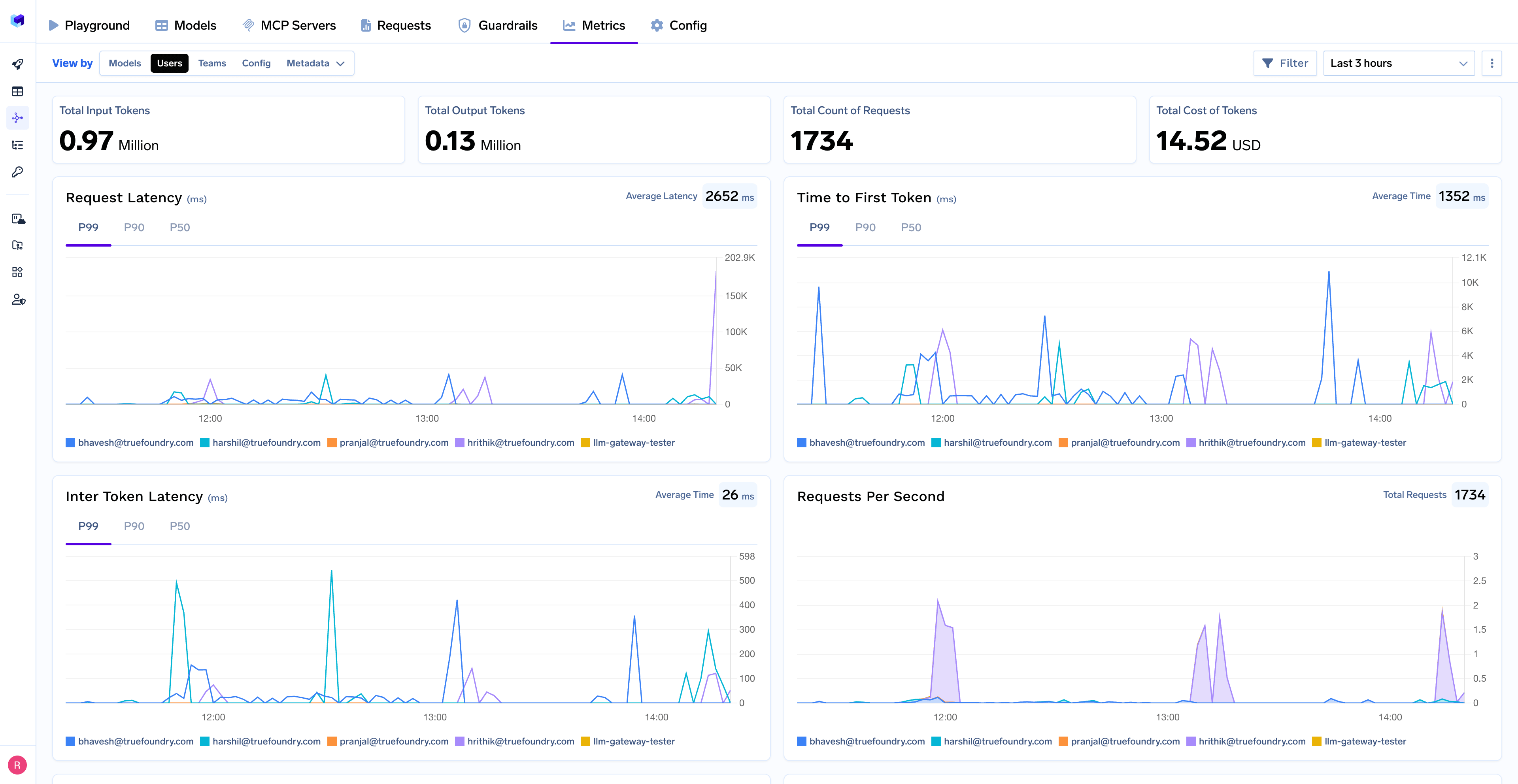
- Performance Metrics: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
- Cost and Token Usage: Gain visibility into your application’s costs with detailed breakdowns of input/output tokens and the associated expenses for each model
- Usage Patterns: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
- Rate limit and Load balancing: You can set up rate limiting, load balancing and fallback for your models