What is Phidata?
Phidata is a framework for building AI applications with memory, knowledge, and tools. It provides a comprehensive platform for creating intelligent agents that can maintain context across conversations, access external knowledge bases, and use various tools to accomplish complex tasks.Key Features of Phidata
- Memory & Context: Built-in memory capabilities that allow agents to remember previous conversations and maintain context across interactions
- Knowledge Integration: Seamless integration with vector databases and knowledge bases for RAG (Retrieval-Augmented Generation) applications
- Tool Integration: Extensive library of tools for web search, file operations, data analysis, and custom function calling
- Agent Orchestration: Framework for building and orchestrating multiple specialized agents that can work together on complex tasks
Prerequisites
Before integrating Phidata with TrueFoundry, ensure you have:- TrueFoundry Account: Create a Truefoundry account and follow our Gateway Quick Start
- Phidata Installation: Install Phidata using pip:
pip install -U phidata
Setup Process
1. Configure Phidata with TrueFoundry
You will get your ‘truefoundry-api-key’, ‘truefoundry-gateway-url’ and model name directly from the unified code snippet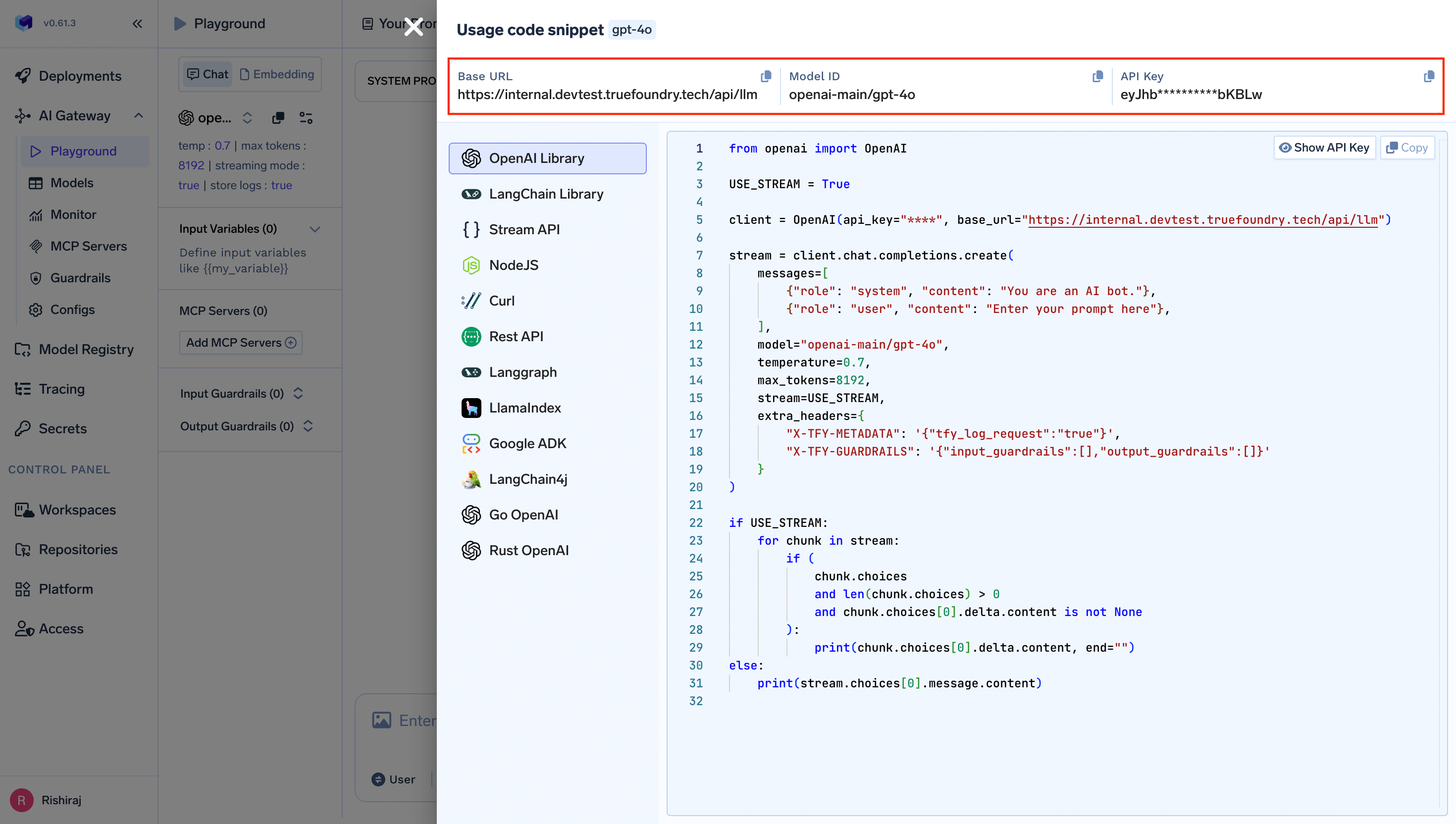
2. Basic Setup with Phidata
Connect to TrueFoundry by configuring the OpenAI LLM in Phidata with your TrueFoundry gateway:your-truefoundry-api-keywith your actual TrueFoundry API keyyour-truefoundry-base-urlwith your TrueFoundry Gateway URL- Use your desired model in the format
provider-main/model-name
3. Environment Variables Configuration
For persistent configuration across your Phidata applications, set these environment variables:Usage Examples
Basic Agent Example
When you run the agent example above, you’ll get a response like this: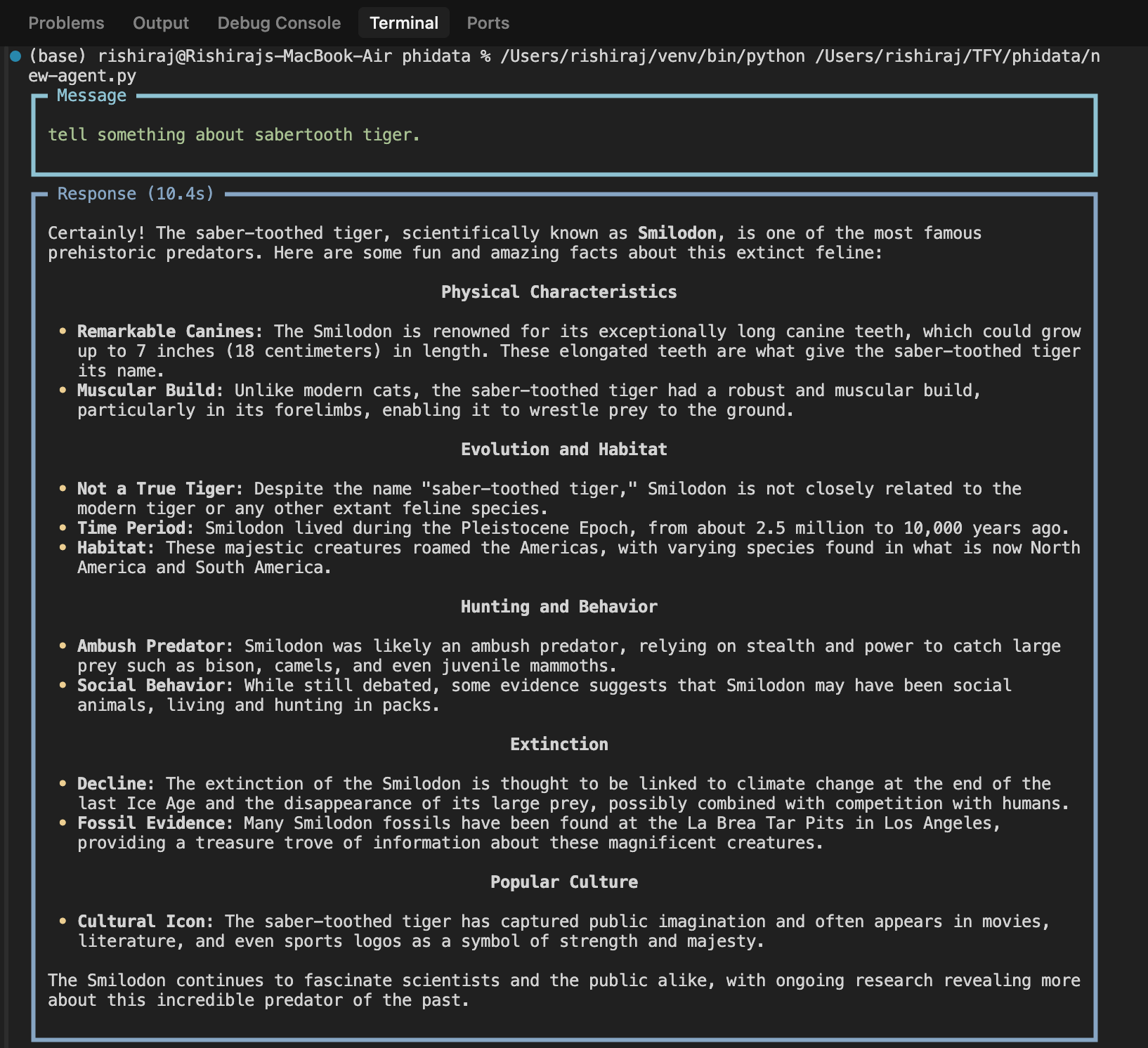
Response Image
Observability and Governance
Monitor your Phidata applications through TrueFoundry’s metrics tab: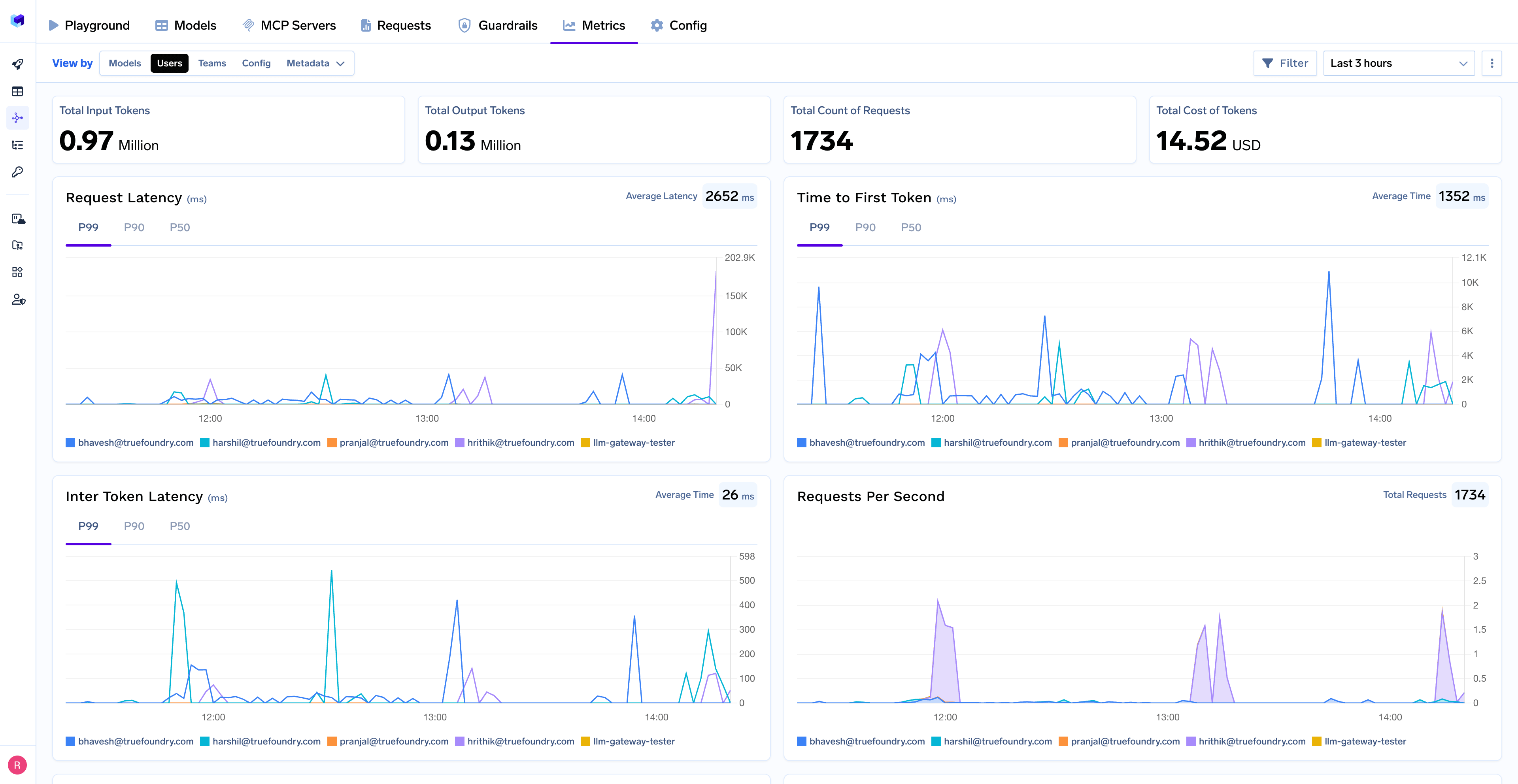
- Performance Metrics: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
- Cost and Token Usage: Gain visibility into your application’s costs with detailed breakdowns of input/output tokens and the associated expenses for each model
- Usage Patterns: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
- Agent Performance: Monitor individual agent performance and tool usage patterns
- Rate limit and Load balancing: Set up rate limiting, load balancing and fallback for your models