Authentication
To authenticate with the AI Gateway, provide your TrueFoundry API key as a bearer token in theAuthorization header:
Request Headers
| Name | Description | Example |
|---|---|---|
Authorization | Your TrueFoundry API key as bearer token | Authorization: Bearer TFY_API_KEY |
x-tfy-metadata | Stringified JSON where both keys and values must be strings. Used for request routing and metrics filtering | x-tfy-metadata: {"custom_field":"value"} |
x-tfy-provider-name | Required for responses API, file upload API, and batch APIs to route requests to the correct provider account | x-tfy-provider-name: openai |
x-tfy-strict-openai | Boolean flag to enable strict OpenAI compatibility (set to false for Claude reasoning model responses with thinking tokens) | x-tfy-strict-openai: true |
x-tfy-retry-config | JSON object to configure retry behavior for failed requests | x-tfy-retry-config: {"attempts": 3, "onStatusCodes": [429, 500, 503]} |
x-tfy-request-timeout | Number in milliseconds specifying the maximum time to wait for a response from a single model. If fallbacks or retries are configured, the timeout is applied per model request (i.e., each attempt, including fallbacks, will have its own timeout). | x-tfy-request-timeout: 60000 |
x-tfy-logging-config | Configuration for request logging | x-tfy-logging-config: {"enabled": true} |
x-tfy-mcp-headers | Stringified JSON to pass custom headers to MCP servers. Format varies by API - see MCP Gateway and Agent API docs. Agent API only supports registered servers. | x-tfy-mcp-headers: {"truefoundry:mcp-server-group:remote-mcp-servers:mcp-server:server-name":{"Authorization":"Bearer TOKEN"}} |
Response Headers
| Name | Description |
|---|---|
x-tfy-resolved-model | The final TrueFoundry model ID used to process the request (may differ from requested model due to load balancing or fallbacks) |
x-tfy-applied-configurations | Dictionary of applied configurations including load balancing, fallback, model config, applied guardrails, and rate limiting |
server-timing | For non-streaming requests only. Contains timing information for different processing stages including middlewares, guardrails, and model calls |
Example of Server-Timing Header
When inspecting network requests in your browser’s developer tools, you’ll see theserver-timing header with timing information like this:
The example below shows a detailed breakdown of request processing:
| Processing Stage | Duration | Description |
|---|---|---|
| Authentication | 0.9 ms | Authenticating User |
| Input guardrails | 0.7 ms | Input validation and content filtering |
| Model call | 1350 ms | AI model response generation (bulk of the time) |
| Output guardrails | 722.3 ms | Output validation and filtering |
| Logging | 1.1 ms | Logging request |
| Total | 2080 ms | Complete request processing time (2.08 seconds) |
load balancing (0 ms), rate limiting (0 ms), and cost budget (0 ms) show zero duration because these configs weren’t triggered for this particular request.
This timing information helps identify bottlenecks in your request processing pipeline.
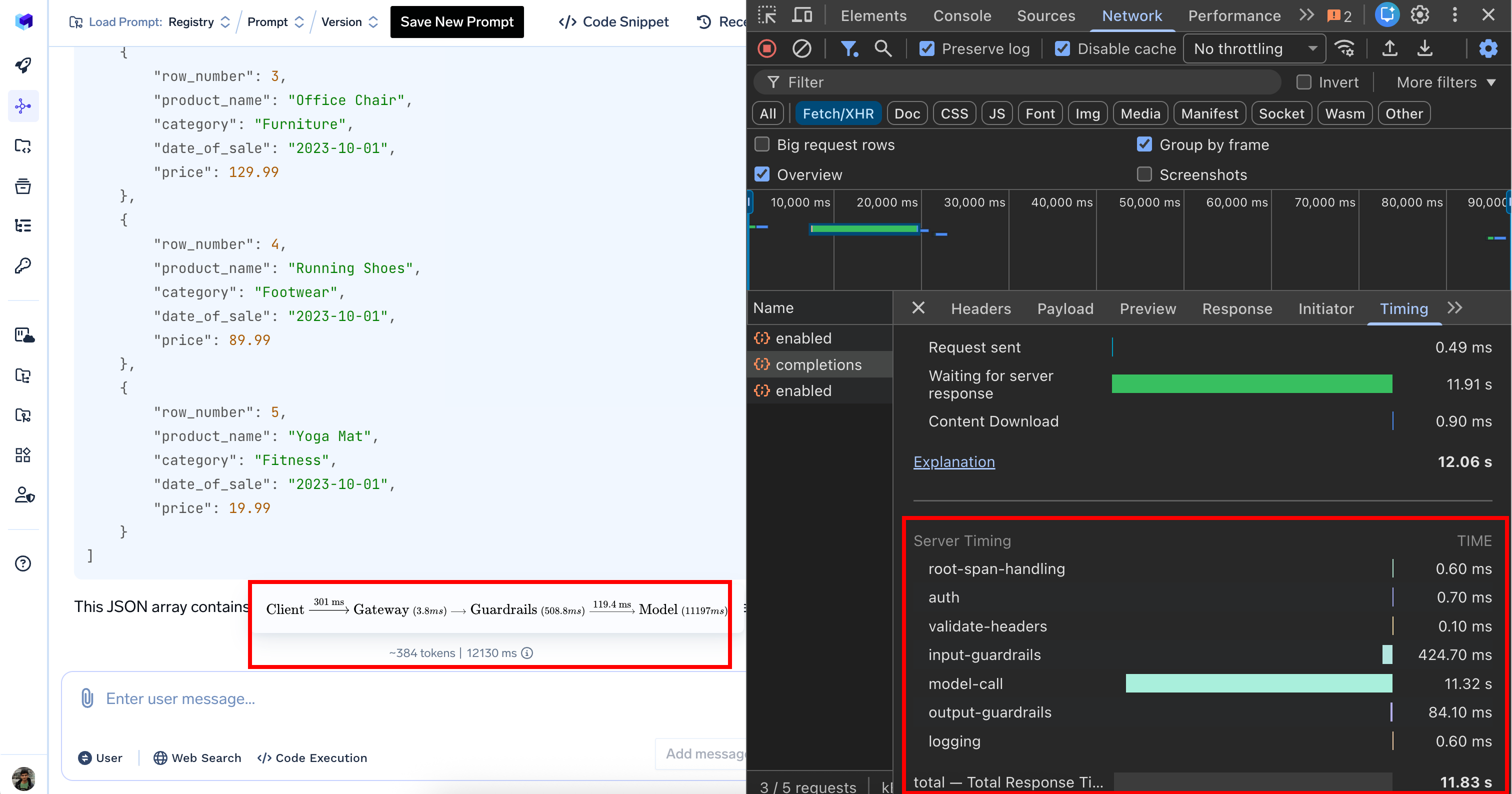
Server-timing header in browser developer tools