- Prompt Run API - Server-side rendering where the Gateway handles prompt rendering
- SDK - Client-side rendering where you fetch and render the prompt locally
How to get the Prompt Version FQN
How to get the Prompt Version FQN
You can get the FQN of the prompt version from the Prompt Registry as shown in the image below.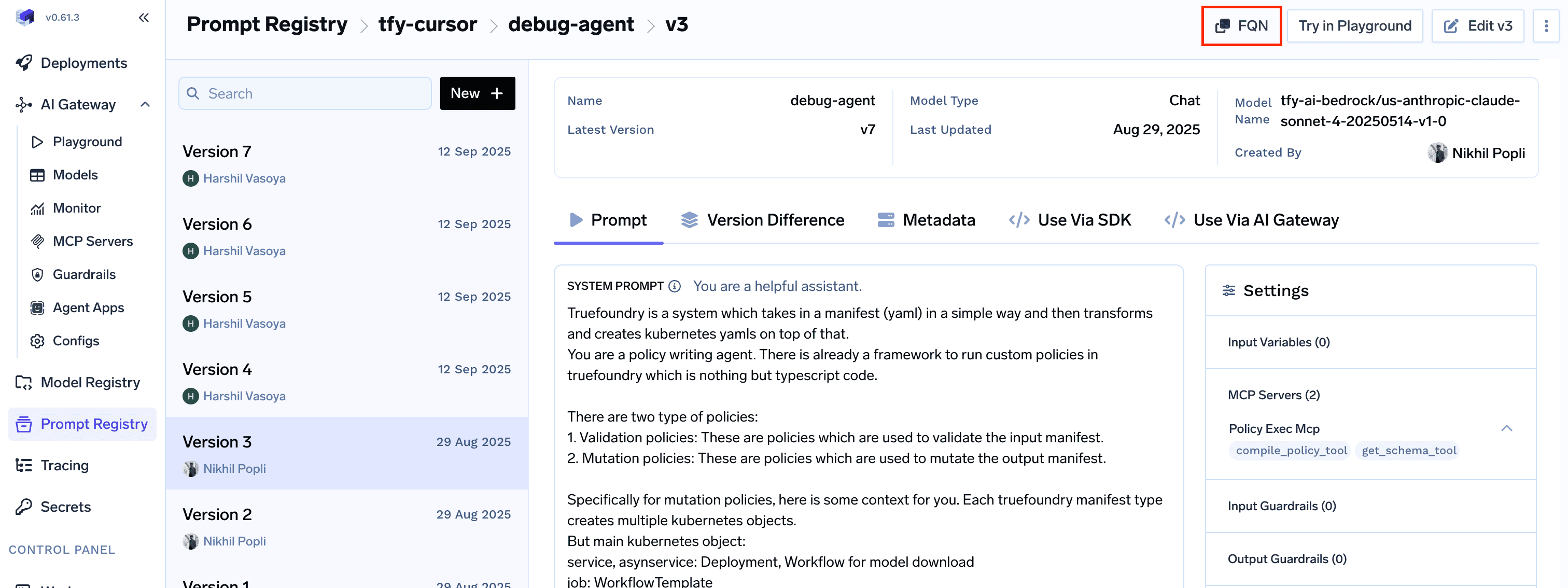
Prompt Run API (server-side rendering)
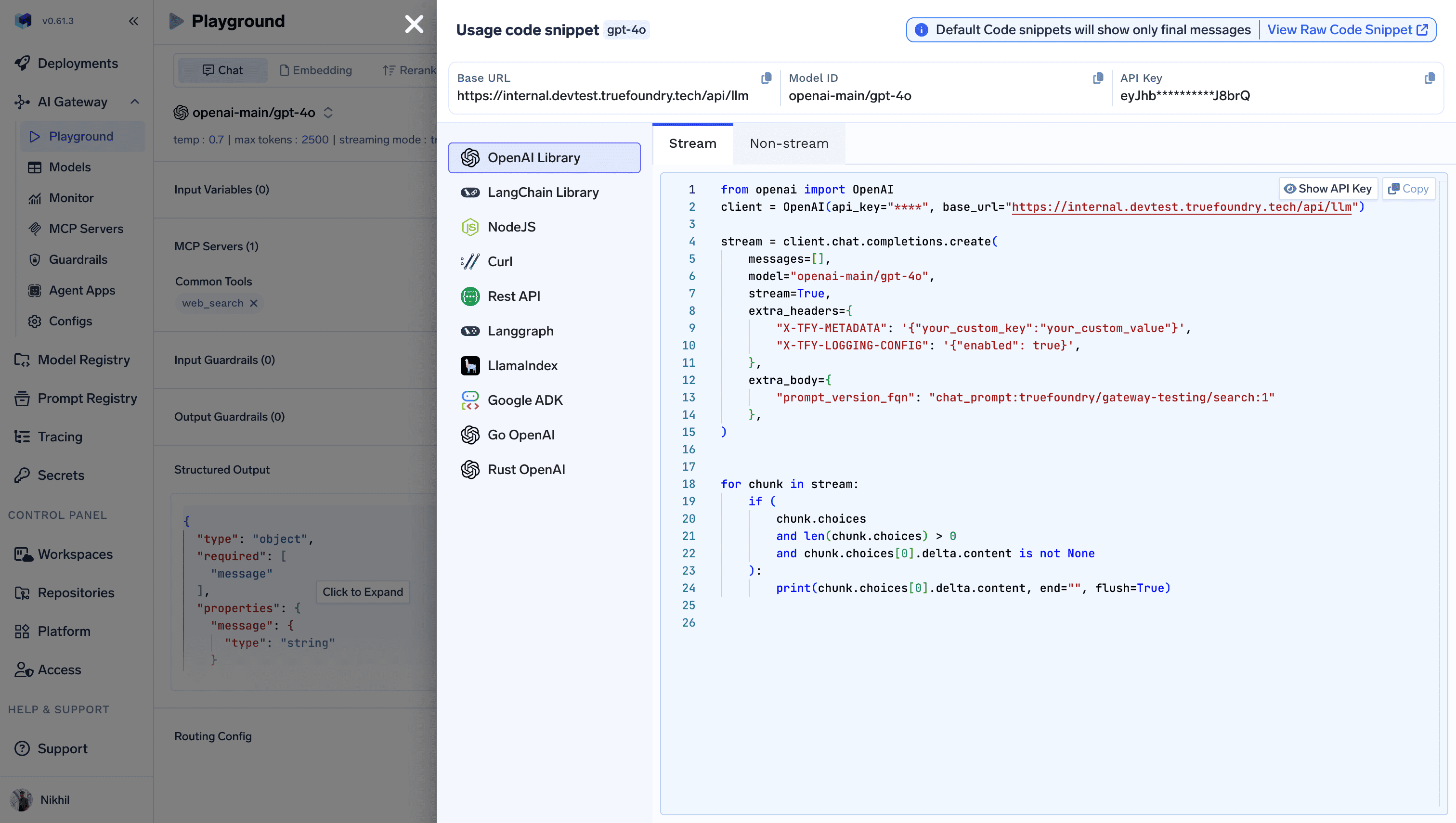
Use the AI Gateway by passing the prompt version FQN in the request body. The Gateway will internally render the prompt and execute it. Parameters:prompt_version_fqn- The fully qualified name of your prompt versionprompt_variables[Optional] - Variables to substitute in your prompt template
Important considerations:
- If the prompt version doesn’t have a model configured, pass the model in the request body using the
modelparameter - If you specify a model in the request body and your prompt version already has a model configured, the request body model takes precedence
- Any messages passed in the request body will be appended to the messages defined in the prompt version
How to get code snippets for prompts
How to get code snippets for prompts
From Playground
- Navigate to the Playground in your TrueFoundry dashboard
- Select and load the prompt as described in the document here Playground
- Click on the “Code Snippet” button to generate the exact code you need
- Copy the generated code snippet for your application
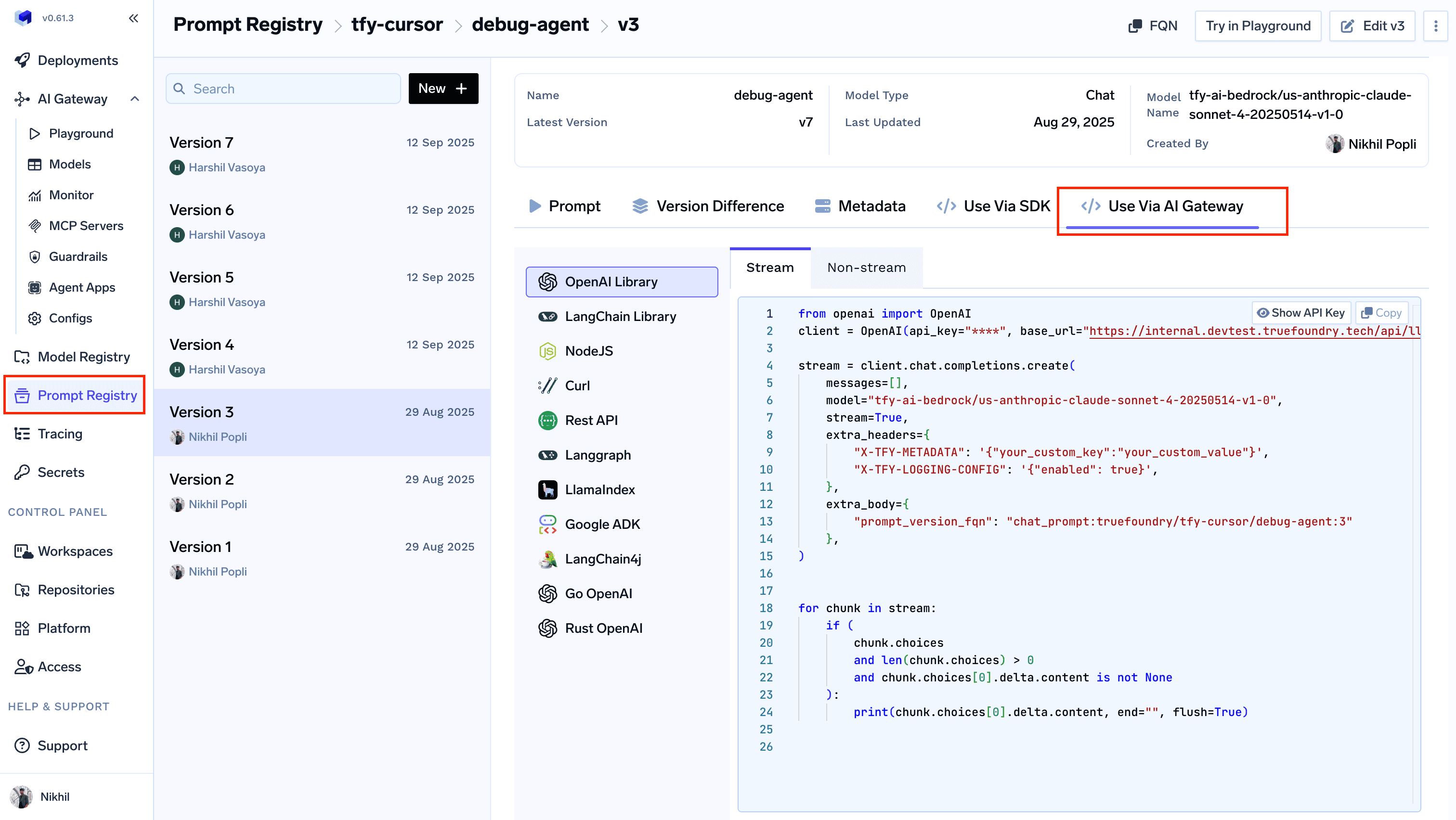
From Prompt Registry
- Go to the Prompt Registry in your TrueFoundry dashboard
- Find and select the prompt version you want to use
- Click on the “Code Snippet” button in the prompt details
- Copy the generated code snippet with the correct prompt version FQN
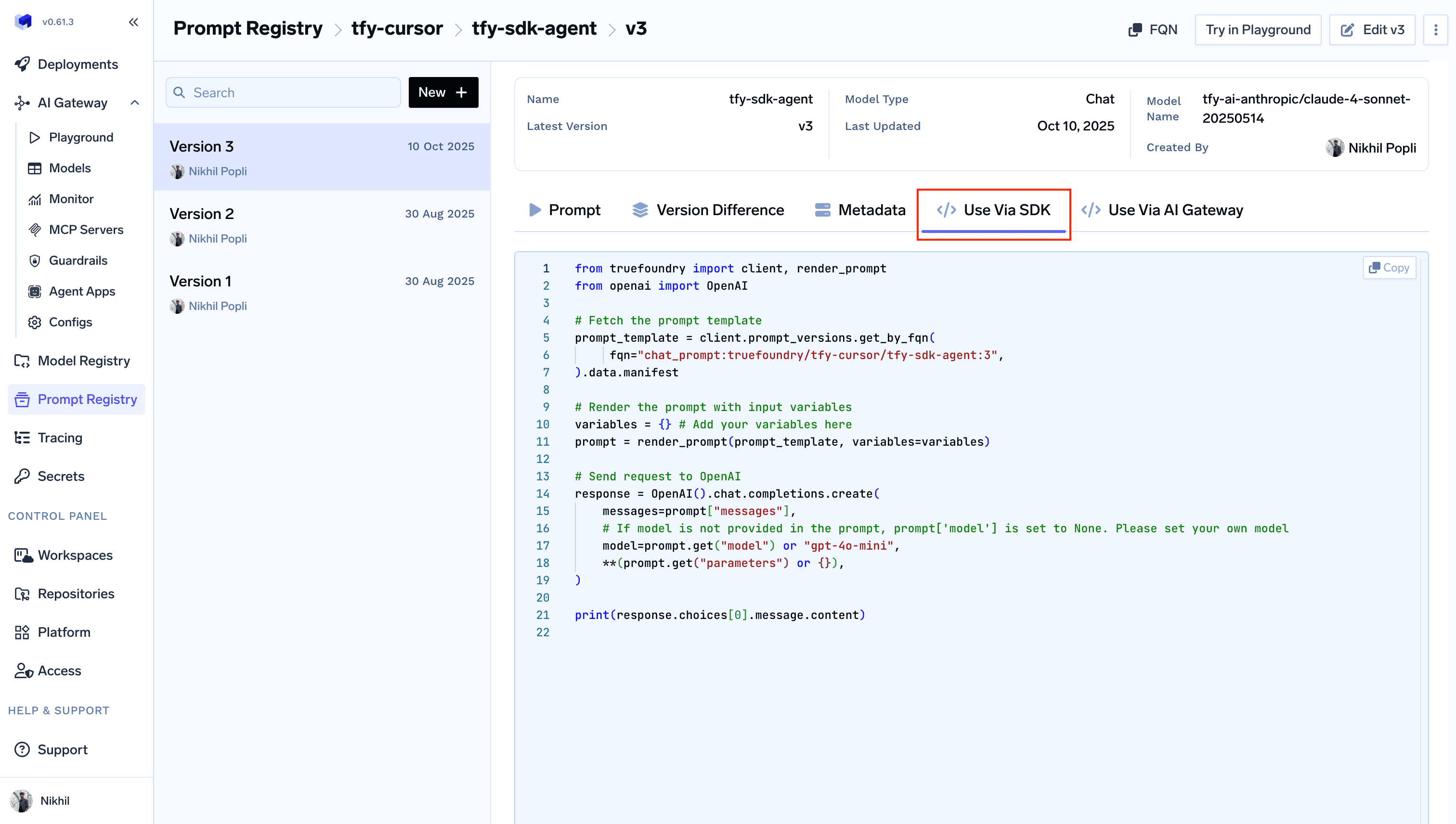
SDK (client-side rendering)
You can fetch the template and render it client-side and then make the request to the model with whatever OpenAI client you are using.How to get code snippets for prompts
How to get code snippets for prompts
- Go to the Prompt Registry in your TrueFoundry dashboard
- Find and select the prompt version you want to use
- Click on the “Use Via SDK” button to view the code snippet