Tracing
This is applicable only for OTEL trace and will only export OTEL traces and not OTEL metrics

AI Gateway - OpenTelemetry Tracing Flow
Export Traces to OTEL Compatible Observability Platforms
To export spans to your existing OTEL Platform: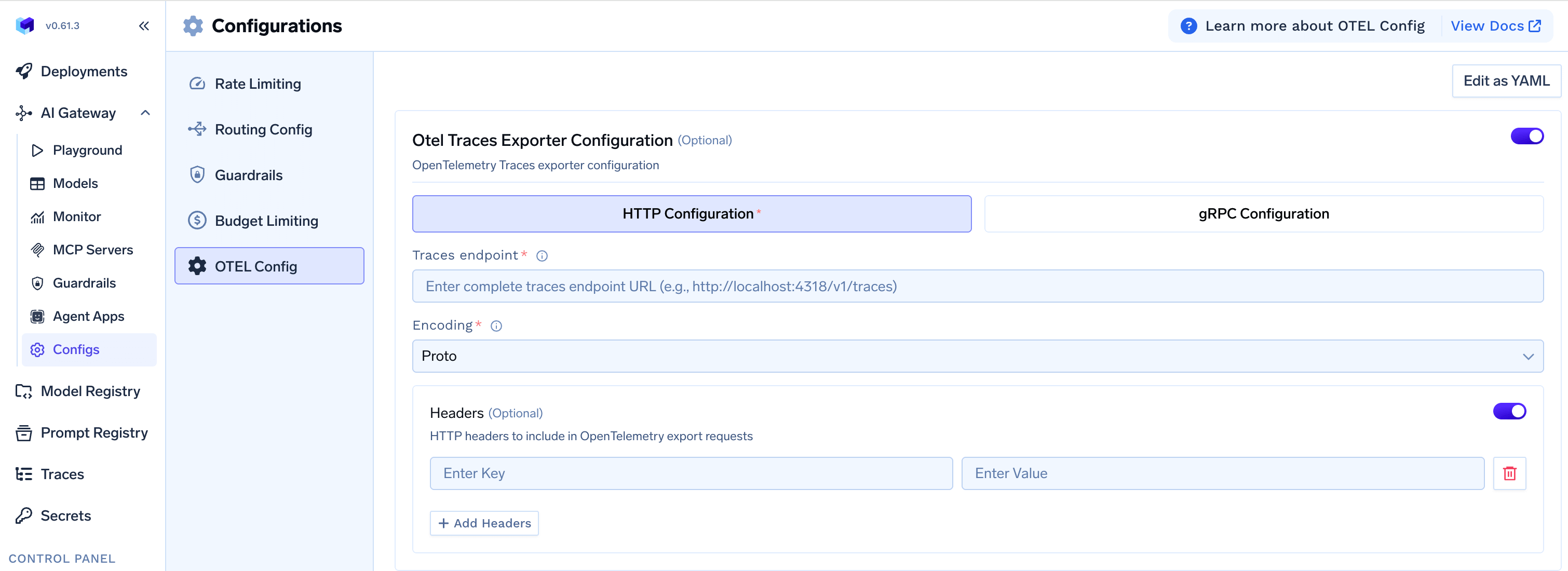
AI Gateway - OpenTelemetry Tracing Export Config Form
- Go to the Configs tab in the AI Gateway section
- Click on OTEL Config
- Toggle on OTEL Traces Exporter Configuration
- Select either HTTP Configuration or gRPC Configuration based on your OTEL platform’s endpoint
- Enter the complete traces endpoint for eg., the traces endpoint for Grafana Cloud is
https://otlp-gateway-prod-ap-south-1.grafana.net/otlp/v1/traces - Select the encoding (only for HTTP Configuration) as either
protoorjson - Optionally, enter the headers required to export spans to the OTEL provider for eg., authorization, region, etc..