What is CrewAI?
CrewAI is a framework for orchestrating role-playing, autonomous AI agents that collaborate to complete complex tasks. It enables you to create specialized agent crews where each agent has defined roles, responsibilities, and expertise areas, working together systematically to achieve shared objectives.Key Features of CrewAI
- Role-Playing Agents: Create specialized agents with distinct personas, skills, and responsibilities that can take on specific roles within your crew
- Collaborative Crews: Orchestrate teams of agents that work together, share context, and coordinate their efforts to tackle complex multi-step workflows
- Structured Tasks: Define clear, actionable tasks with specific objectives, expected outputs, and success criteria for systematic execution
- Tool Integration: Equip your agents with powerful tools and capabilities to interact with external systems, APIs, and data sources
How TrueFoundry Integrates with CrewAI
Installation & Setup
1
Install CrewAI
2
Get TrueFoundry Access Token
- Sign up for a TrueFoundry account
- Follow the steps here in Quick start
3
Configure CrewAI with TrueFoundry
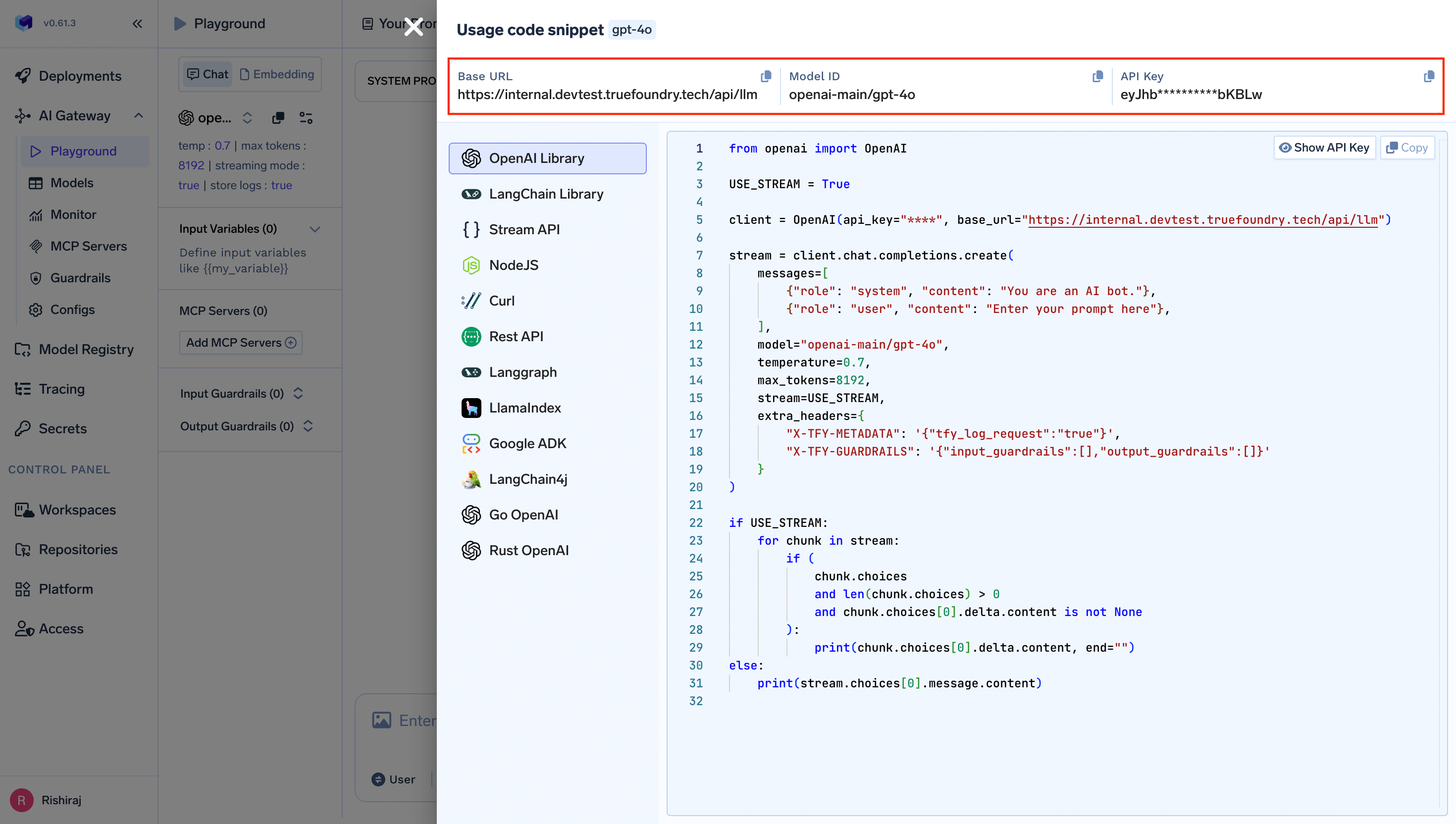
Complete CrewAI Example
Observability and Governance
Monitor your CrewAI agents through TrueFoundry’s metrics tab: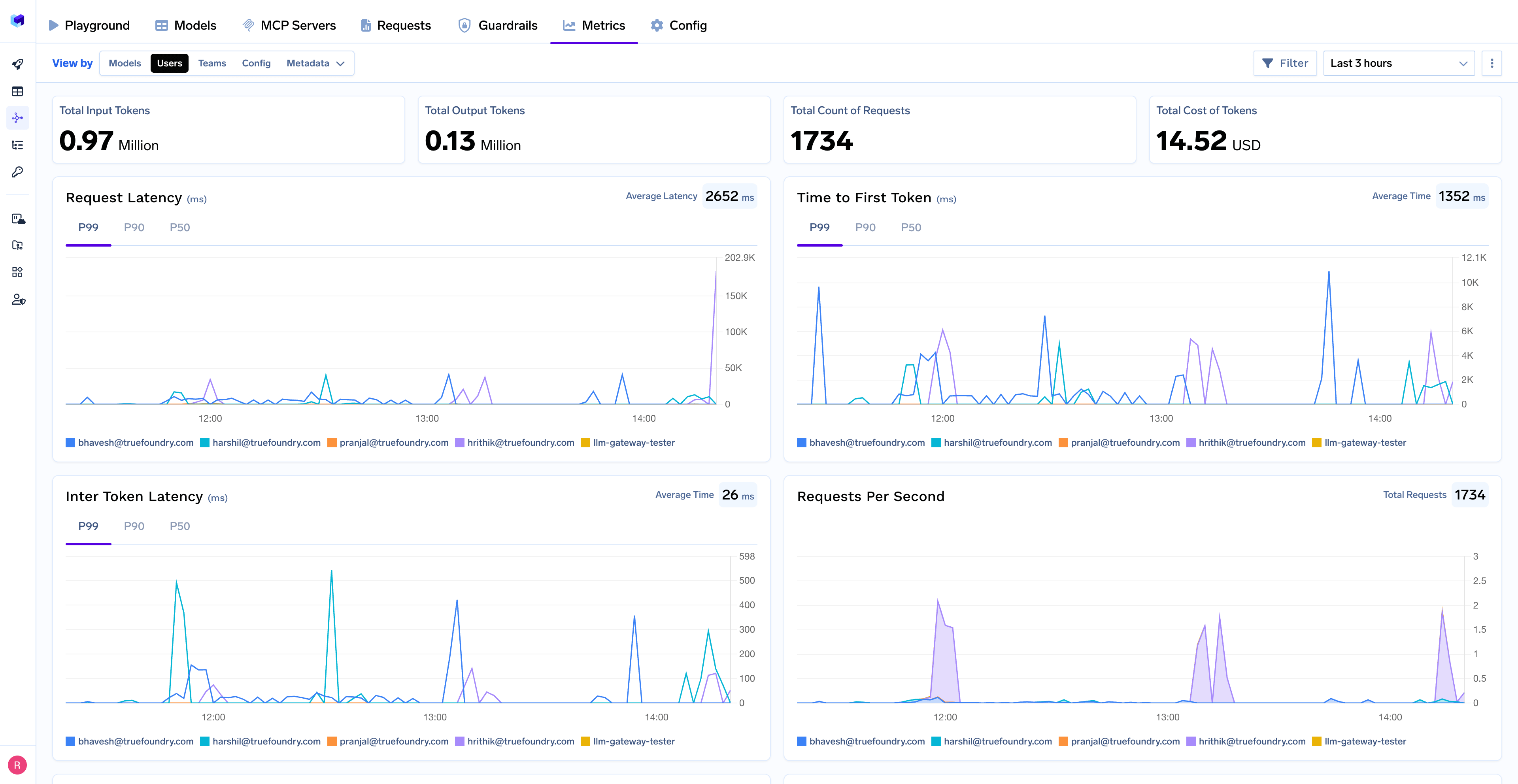
- Performance Metrics: Track key latency metrics like Request Latency, Time to First Token (TTFS), and Inter-Token Latency (ITL) with P99, P90, and P50 percentiles
- Cost and Token Usage: Gain visibility into your application’s costs with detailed breakdowns of input/output tokens and the associated expenses for each model
- Usage Patterns: Understand how your application is being used with detailed analytics on user activity, model distribution, and team-based usage
- Rate limit and Load balancing: You can set up rate limiting, load balancing and fallback for your models
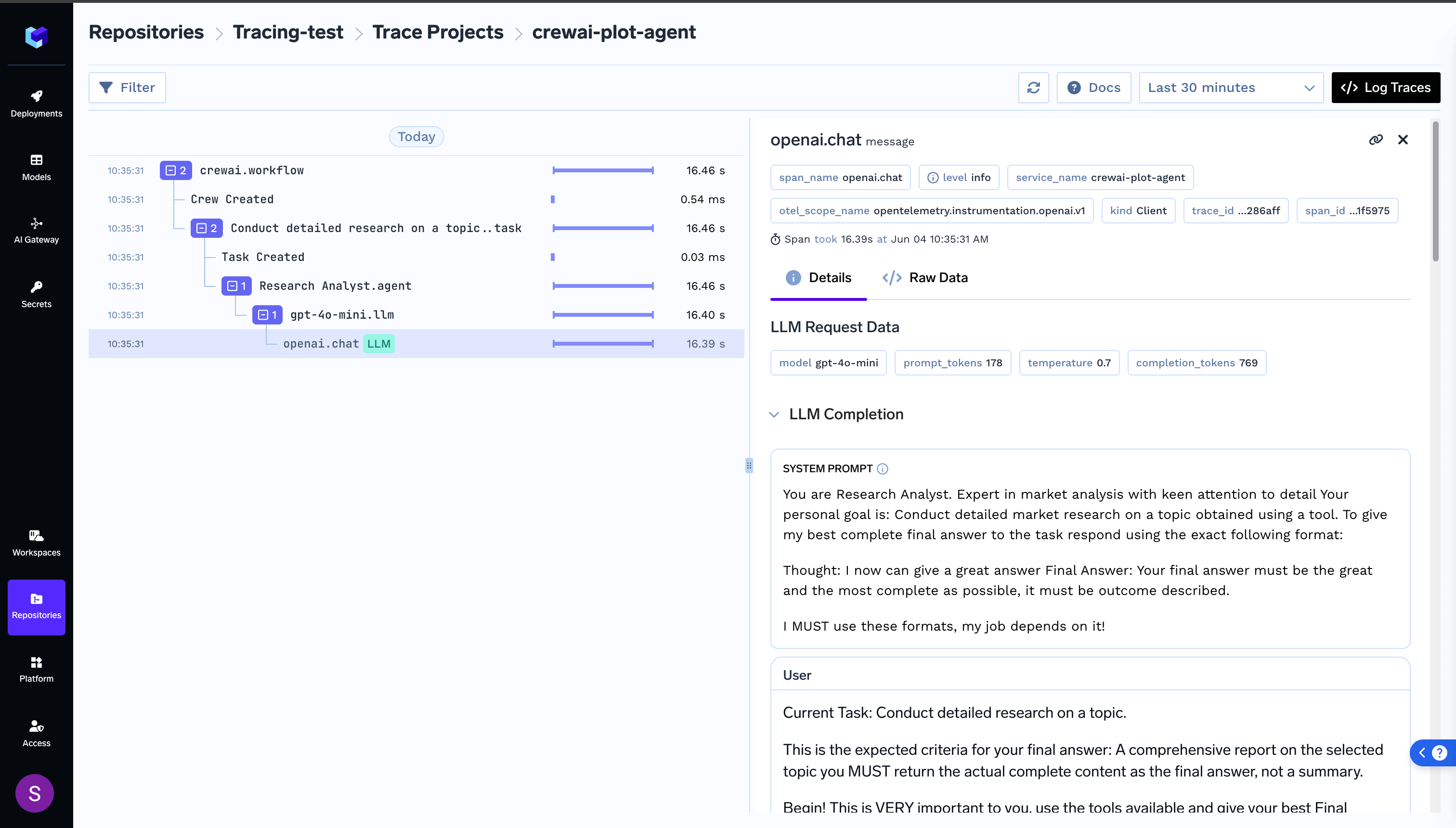
Tracing
For a more detailed understanding on tracing, please see getting-started-tracing.For tracing, you can add the Traceloop SDK: