How to Access the Playground
To access the AI Gateway Playground:- Log into your TrueFoundry dashboard
- Navigate to the
AI Gatewaysection in the main menu - Select
Playgroundfrom the dropdown options
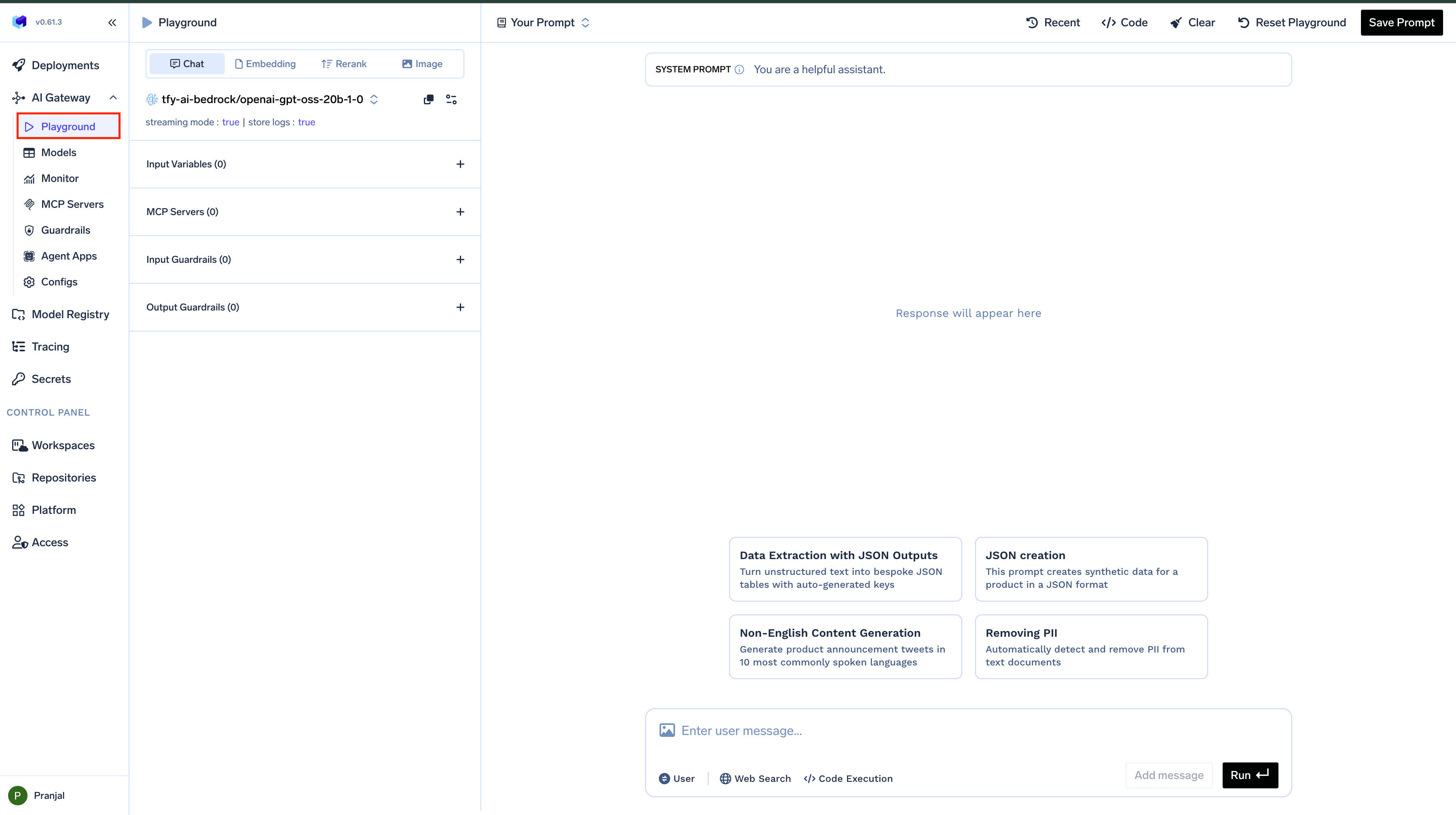
Playground Interface Overview
The Playground interface combines simplicity with powerful functionality, organized into three main sections:- Top Bar: Contains Recent History, prompt management, and code generation options
- Left Sidebar: Access to model selection, guardrails, MCP servers, and configuration options
-
Main Chat Area: Where you interact with the model and view responses

Key Components
- Model Selection: Browse and select from over 1,000 models across 15+ providers
- Interactive Chat Interface: Send prompts and view model responses in real-time
- Configuration Controls: Adjust model parameters and settings
- Guardrails: Configure safety measures for inputs and outputs
- MCP Server Integration: Connect to MCP Servers for enhanced capabilities
- Prompt Library: Save and load prompt templates with their configurations
Features
Configure Model Settings
Configure Model Settings
Fine-tune your model’s behavior by adjusting various parameters:
To access these settings, click on the settings icon next to the model selection dropdown. Changes take effect immediately for your next interaction.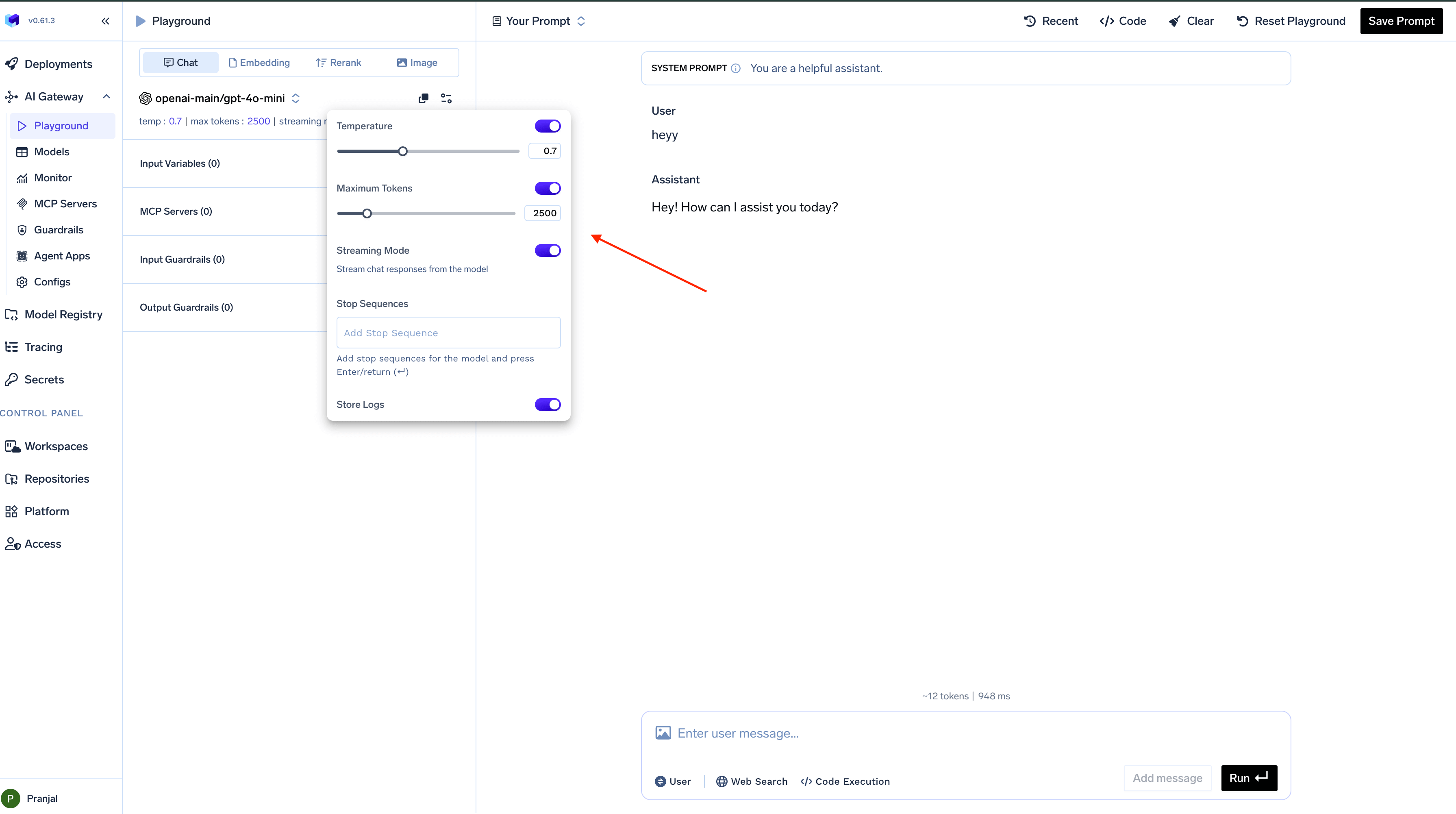
| Parameter | Description |
|---|---|
| Temperature | Controls randomness in responses |
| Response Format | Choose between streaming or complete responses |
| Maximum Tokens | Sets the length limit for model responses |
| Stop Sequence | Defines where the model should stop generating |
| Request Logging | Enables or disables logging of requests |
Test out Models
Test out Models
Selecting a Model
To select a model for your session:- Open the
model dropdownmenu from the left sidebar - Browse through available models or use the search function
- Select your desired model
chat, embedding, rerank, image). You can filter models based on these categories or search for specific model names.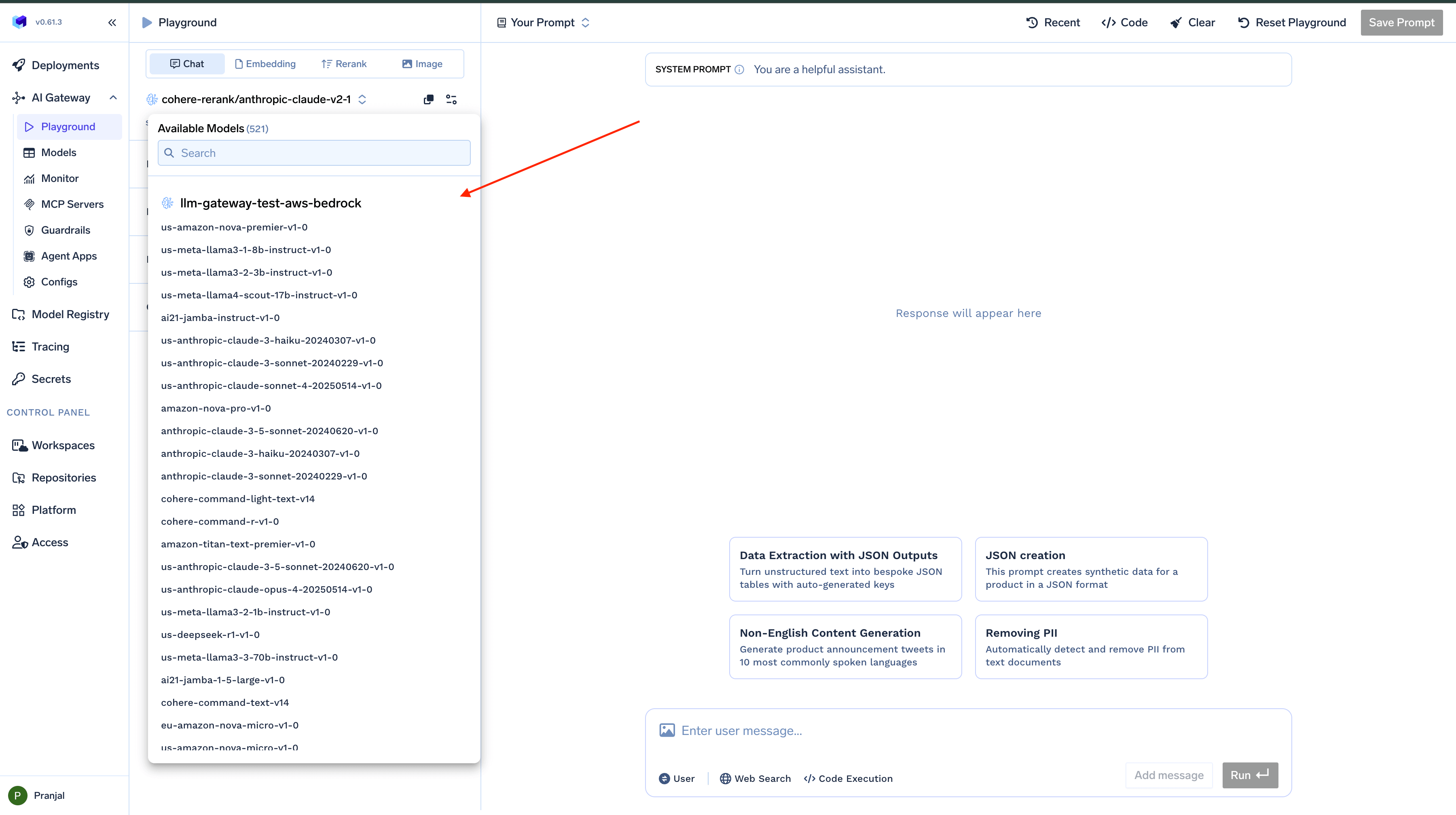
Interacting with Models
Once you’ve selected a model, you can begin interacting with it:- Type your prompt in the text input field
- Click the
Runbutton to send your prompt to the model - View the model’s response in the chat interface
Run. The Playground maintains the conversation context between turns, allowing for natural dialogue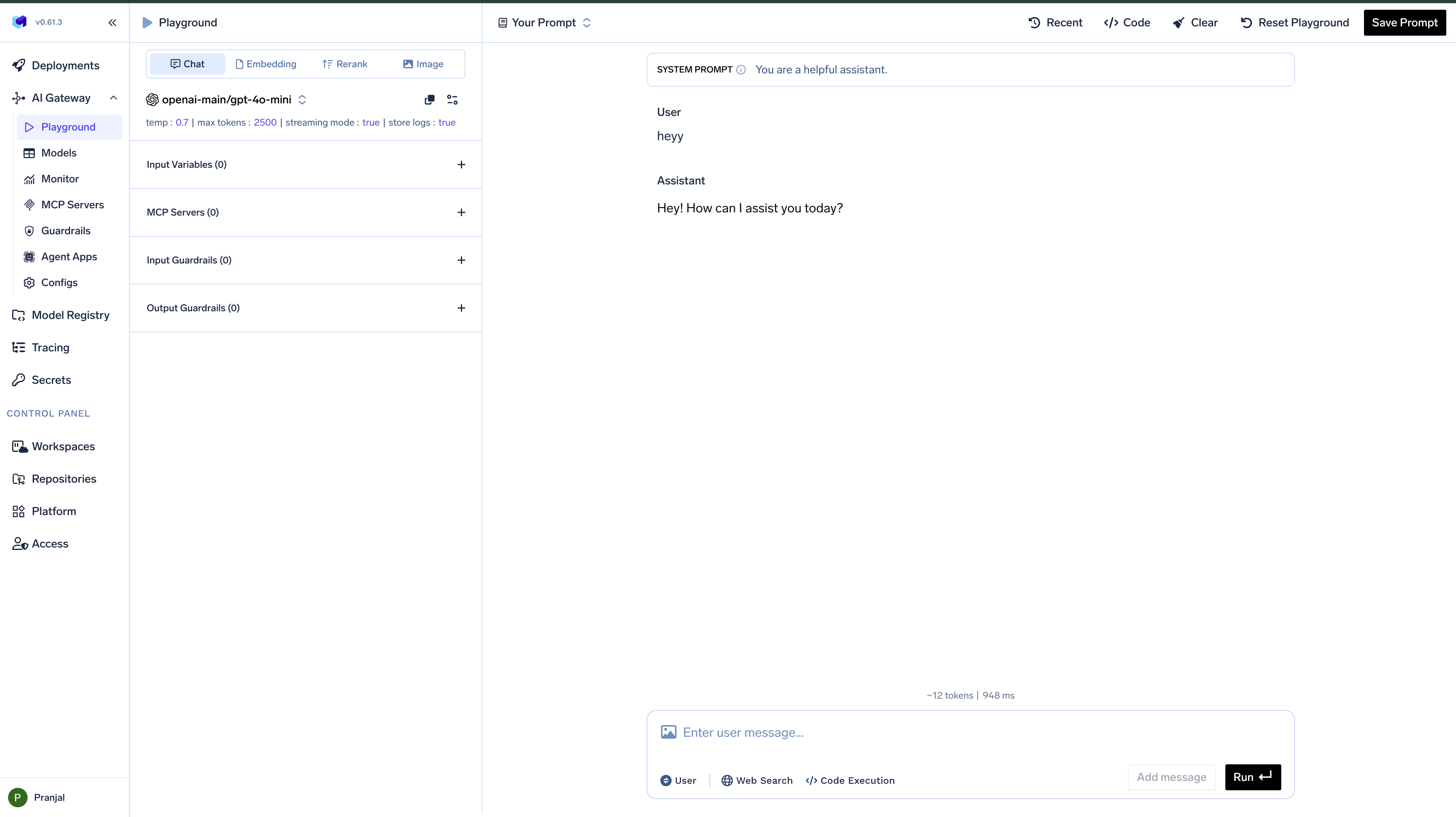
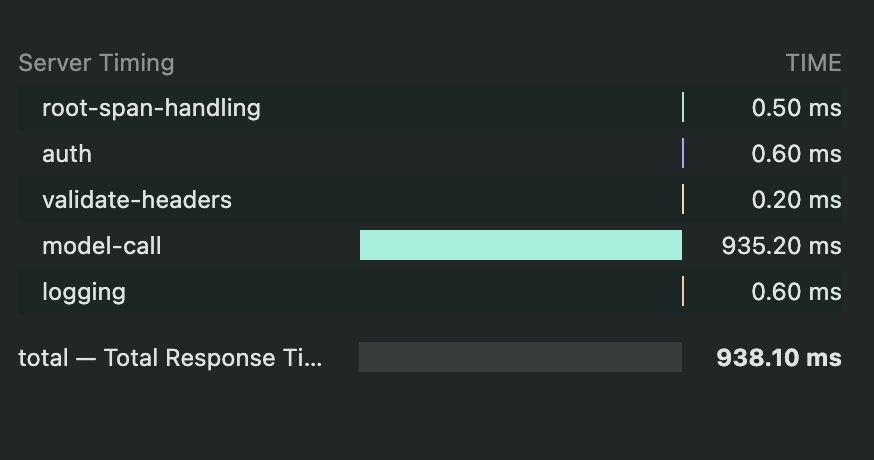
Measure Gateway Latency
Measure Gateway Latency
The Playground provides detailed performance metrics for each request, helping you understand where time is spent during model interactions:
This breakdown helps identify bottlenecks and optimize your AI implementation.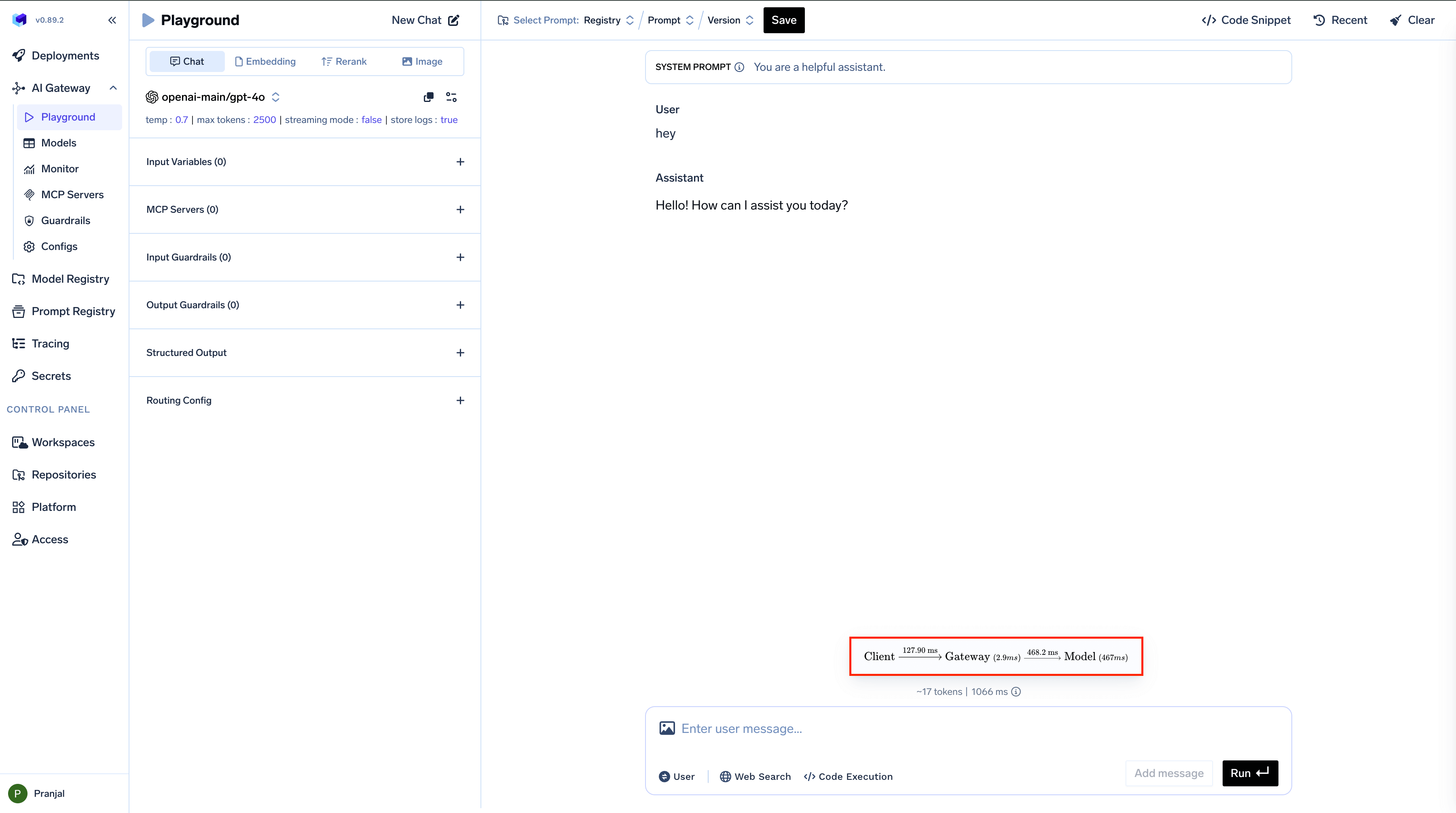
| Stage | Description | Example Time |
|---|---|---|
| Frontend to Gateway | Time for request to travel from browser to AI Gateway | 127.9 ms |
| Gateway Processing | Time spent on rate limiting, budget checks, load balancing, and guardrails | 2.9 ms |
| Gateway to Model | Time for request to reach the AI model provider | 468.2 ms |
| Model Processing | Time taken by the model to generate a response | 467 ms |
server-timing header in your browser’s developer tools:Accessing Chat History
Accessing Chat History
Access your previous conversations easily:
- Click on the
Recentbutton in the top bar - Browse through your previous chat sessions
- Select any conversation to resume from where you left off
View Code Snippets to integrate in code
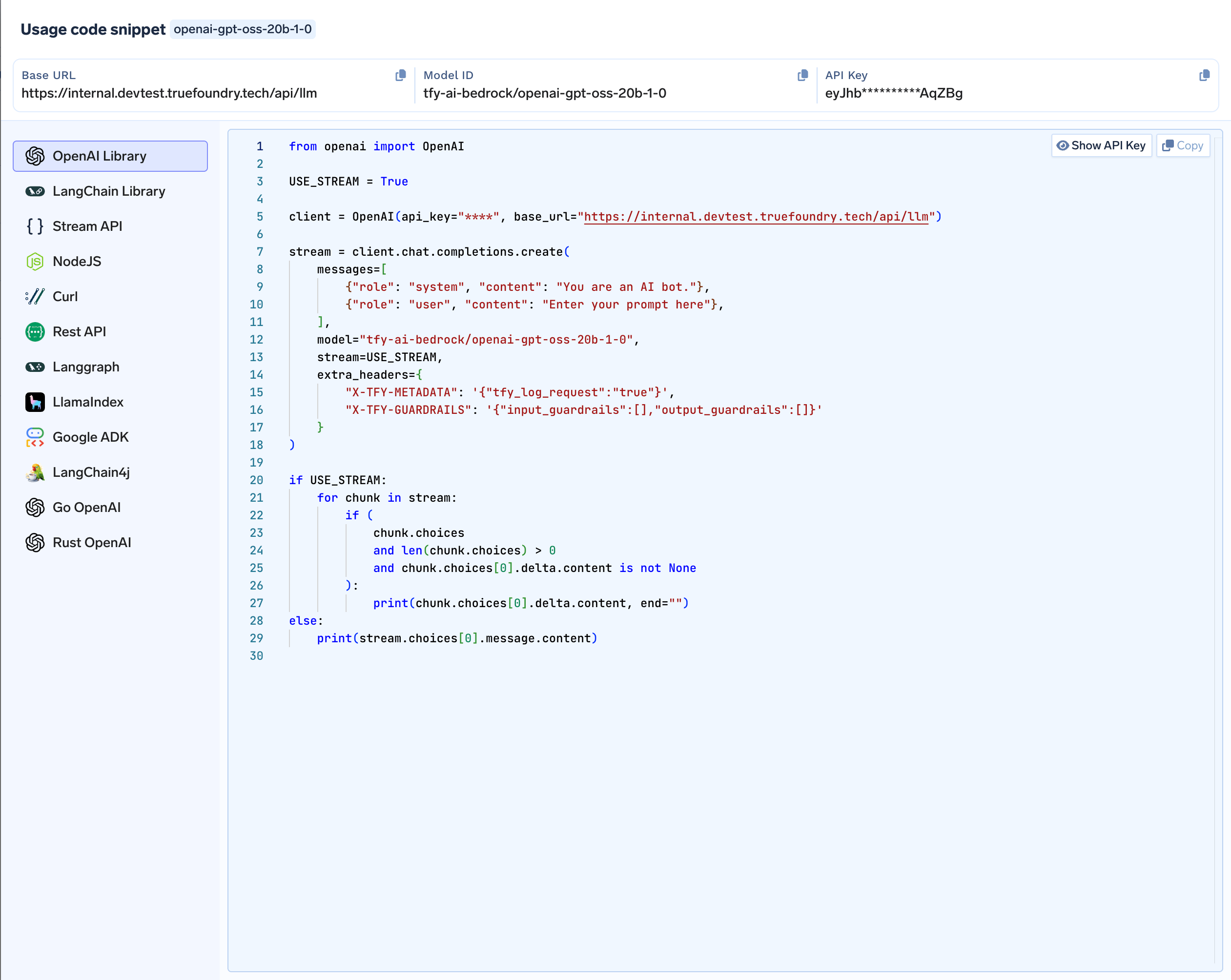
View Code Snippets to integrate in code
Generating Code Snippets
The Playground makes it easy to integrate your configured model into your applications:- Click the
Codebutton located in the top bar - Browse through the available code snippets for different libraries and frameworks
- Copy the generated code directly into your application
OpenAI SDK, Langchain, Langgraph, Google ADK, Stream API, Rest API, Go-OpenAI, Rust-OpenAI, cURL, NodeJS, llamaindex, Langchain4jThe generated code includes your current model selection and parameter settings, making it ready to use in your application.
Test, Edit and Save Prompts
Test, Edit and Save Prompts
Loading Saved Prompts
To use previously created prompts:-
Click the
Your Promptsbutton in the top bar - Browse through your saved prompts or prompts shared with you
- Select the desired prompt to load its complete configuration
-
The prompt is now ready to use
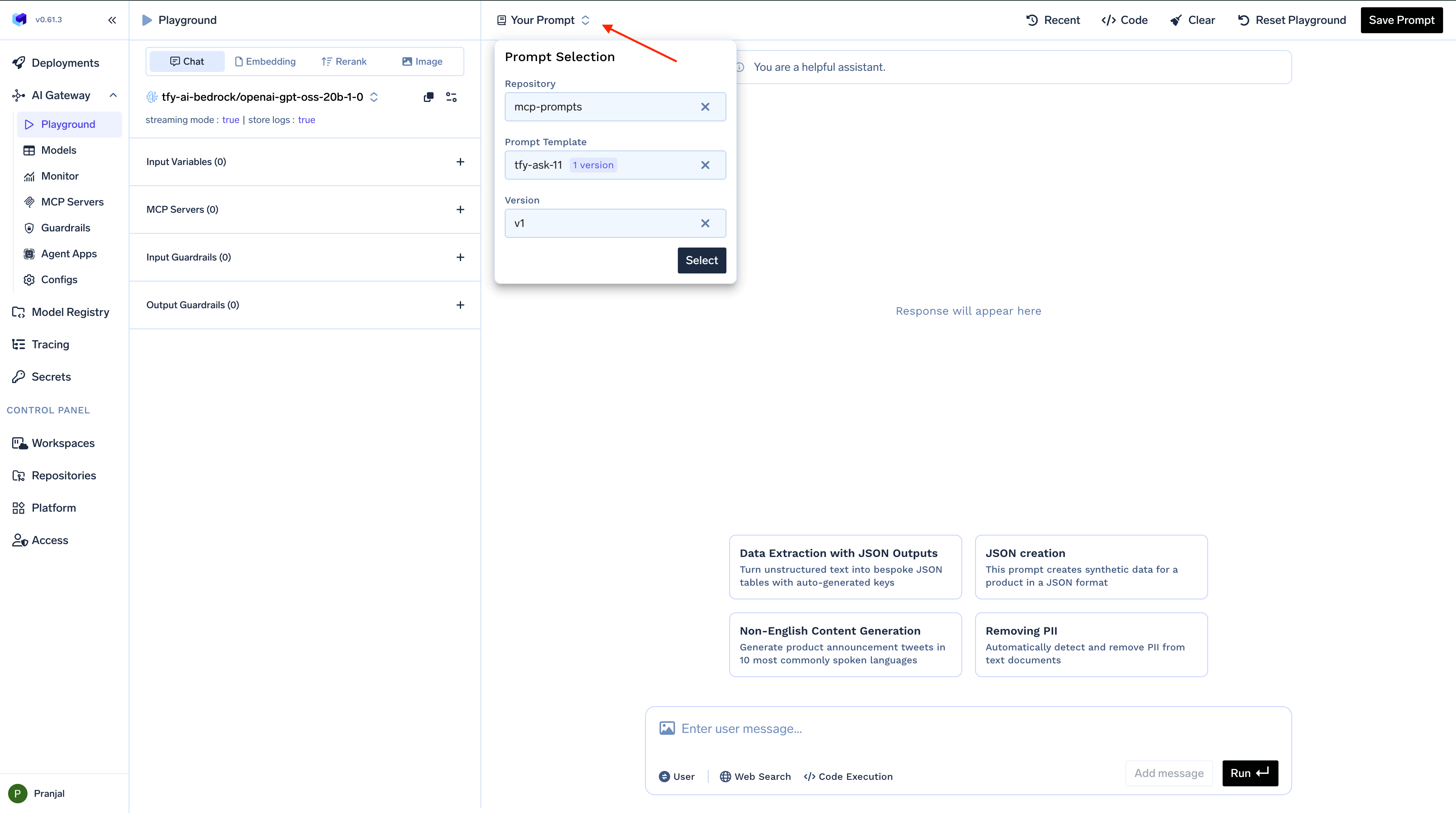
Creating and Saving Prompts
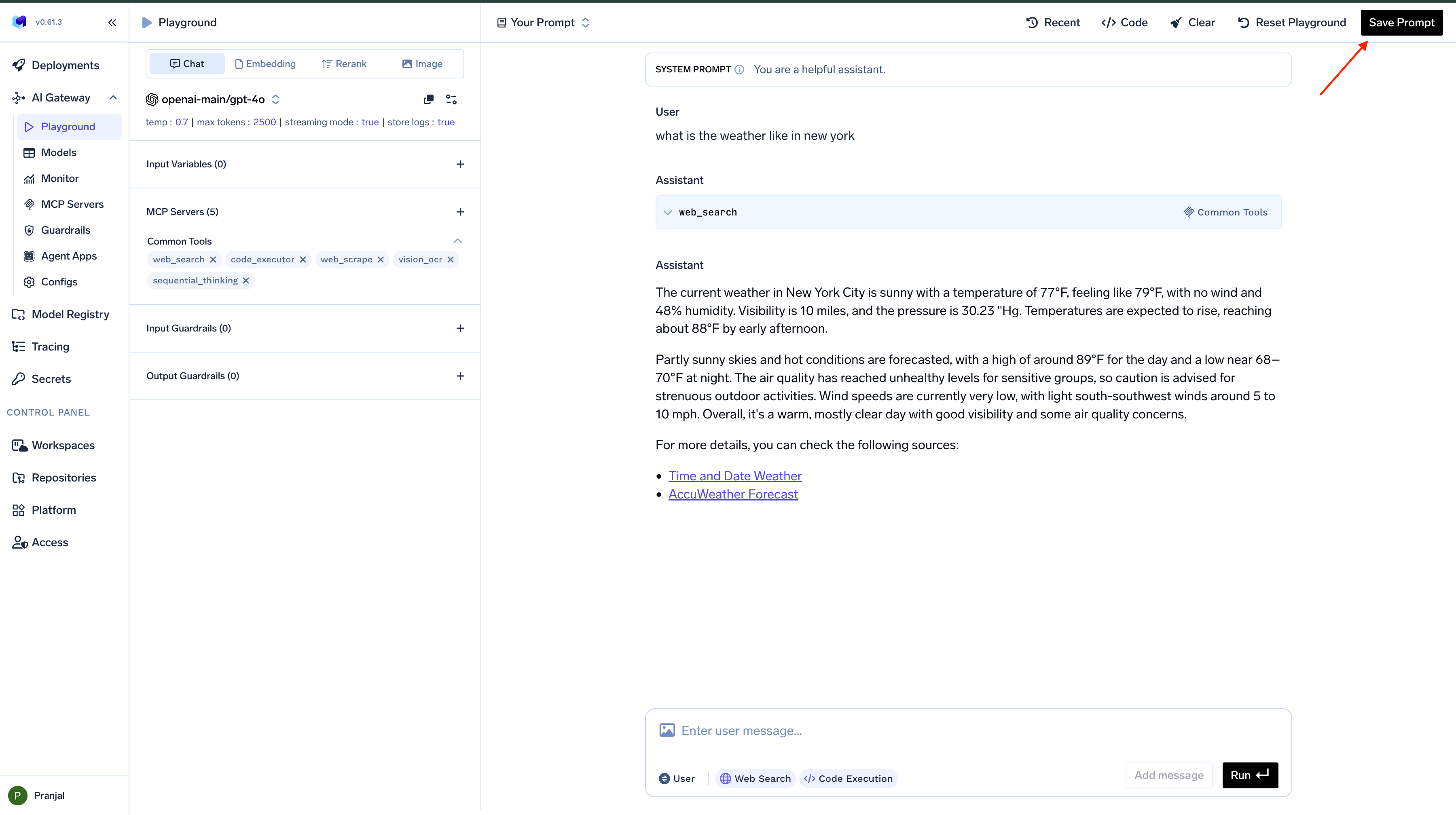
When you’ve created a configuration you want to preserve:- Set up your model, parameters, guardrails, and MCP servers as desired
- Click the
Save Promptbutton - Choose the repository you want to save your prompt into
- Name your prompt and add a commit message
- Add optional tags to categorize your prompt
- Click
Saveto store your prompt
Test MCP Servers
Test MCP Servers
MCP (Model Control Protocol) Servers allow your AI models to perform complex operations and interact with external systems.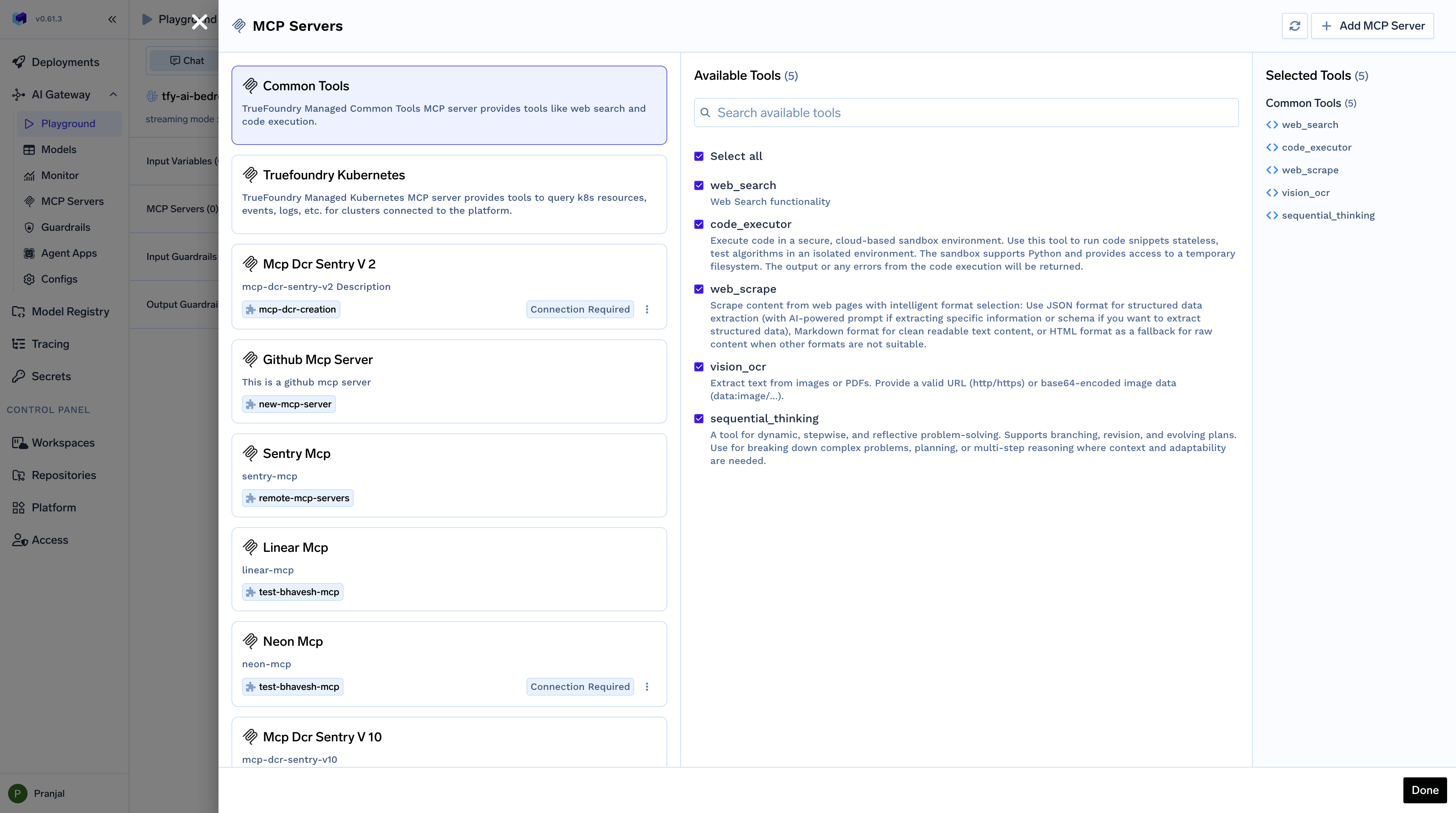
Setting Up MCP Servers
To integrate MCP Servers with your Playground session:- Click on
MCP Serverin the left bar of Playground - Choose the MCP Servers and tools you want to use
- Connect with the MCP Server if required by entering credentials
- The MCP Server is now ready to use
Using MCP Servers in Conversations
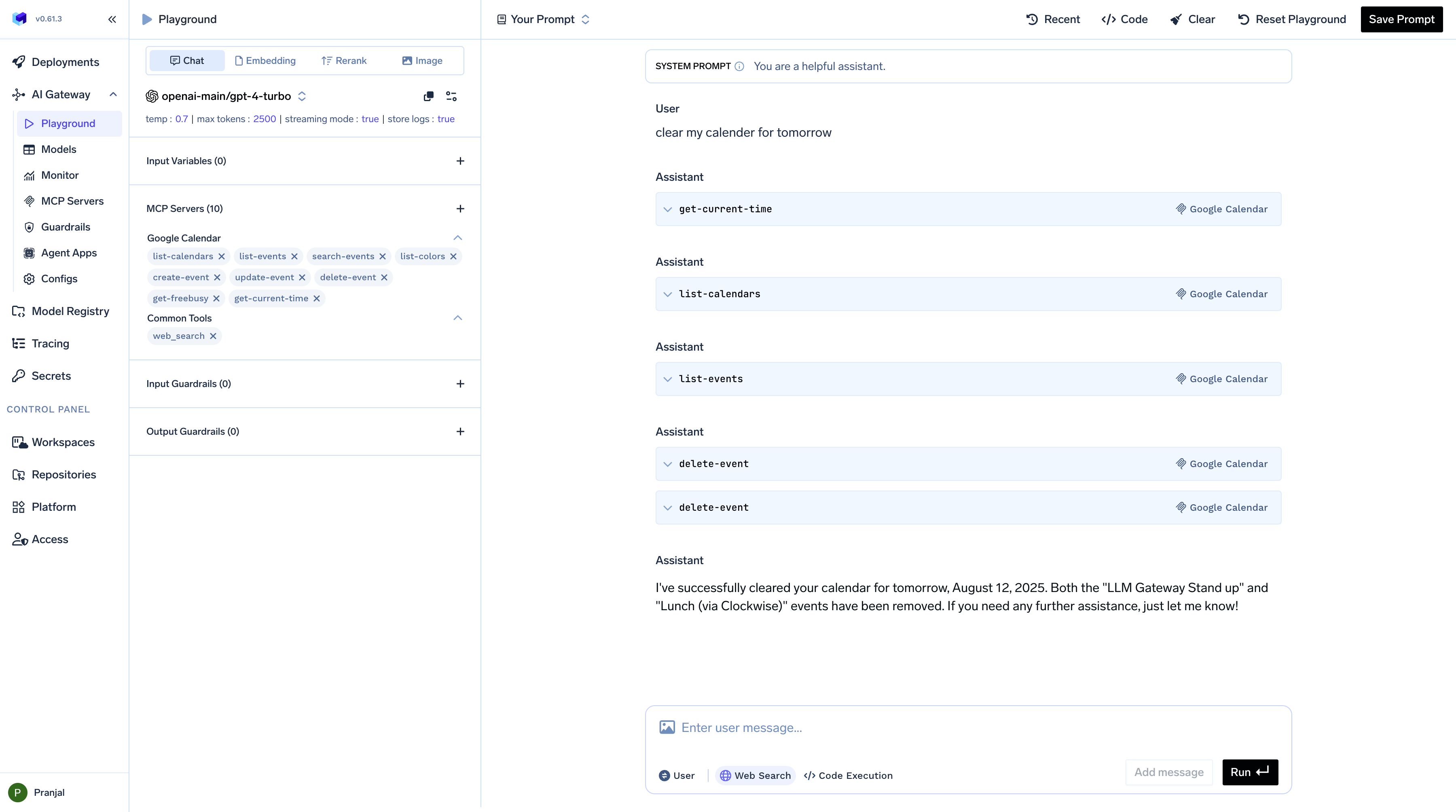
Once you’ve connected an MCP Server, you can use it in your conversations:-
Send a natural language request like
Clear my calendar for tomorrow - The model interprets the request and uses the MCP Server to access your calendar
-
The operation is performed and confirmation is provided
Configure Guardrails
Configure Guardrails
Guardrails help control AI model behavior by filtering or modifying inputs and outputs.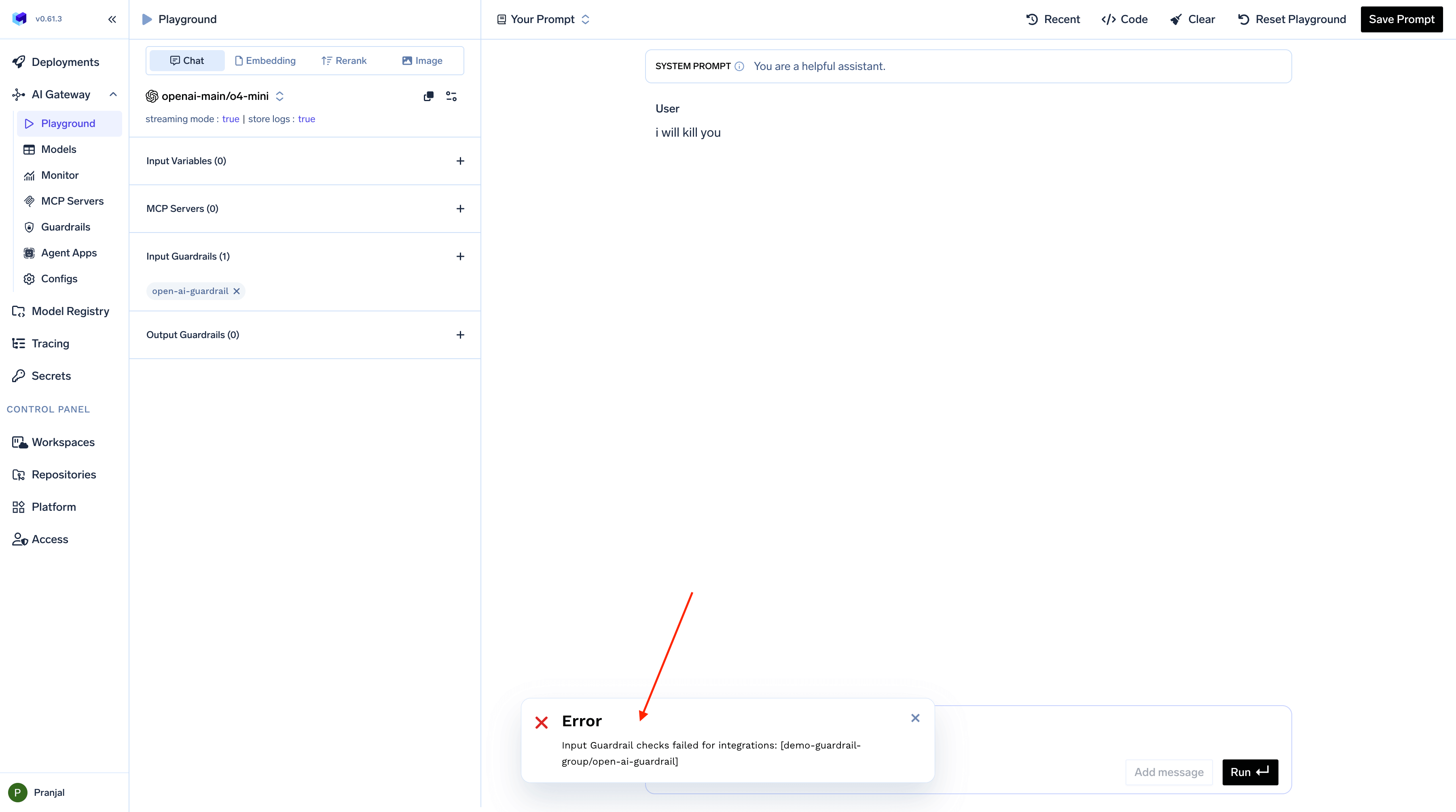
Types and Modes of Guardrails
The Playground supports two types of guardrails:- Input Guardrails: Applied to user prompts before they reach the model
- Output Guardrails: Applied to model responses before they’re shown to the user
- Validation Mode: Blocks requests or responses that fail to meet criteria
- Mutation Mode: Automatically modifies requests or responses to comply with requirements
Output Guardrails will only work for non-streaming requests. Input guardrails work on both streaming and non-streaming responses.
Setting Up Guardrails
To configure guardrails in the Playground:- Select either
InputorOutput guardrailsfrom the left bar in Playground - Choose from the dropdown of available guardrails
- You can select multiple guardrails for each Input and Output
- Send a request to see the guardrails in action
Guardrail Examples
Input Validation Example
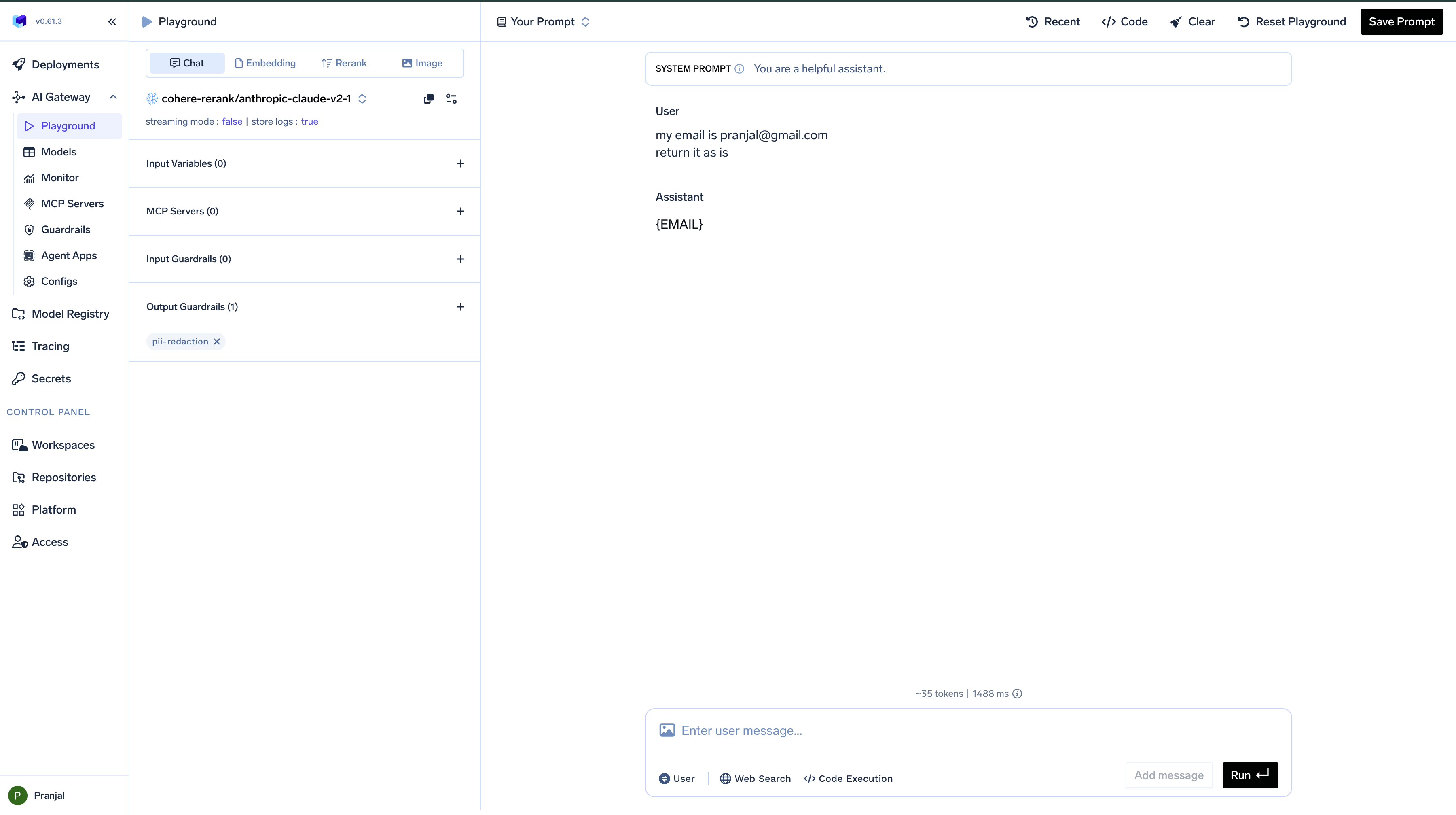
When an input guardrail detects prohibited content, it prevents the request from reaching the model and displays an error message:Output Modification Example
Output guardrails can automatically transform model responses to meet specific requirements: