Why do we need load balancing / fallback / retries ?
Service Outages and Downtime
Service Outages and Downtime
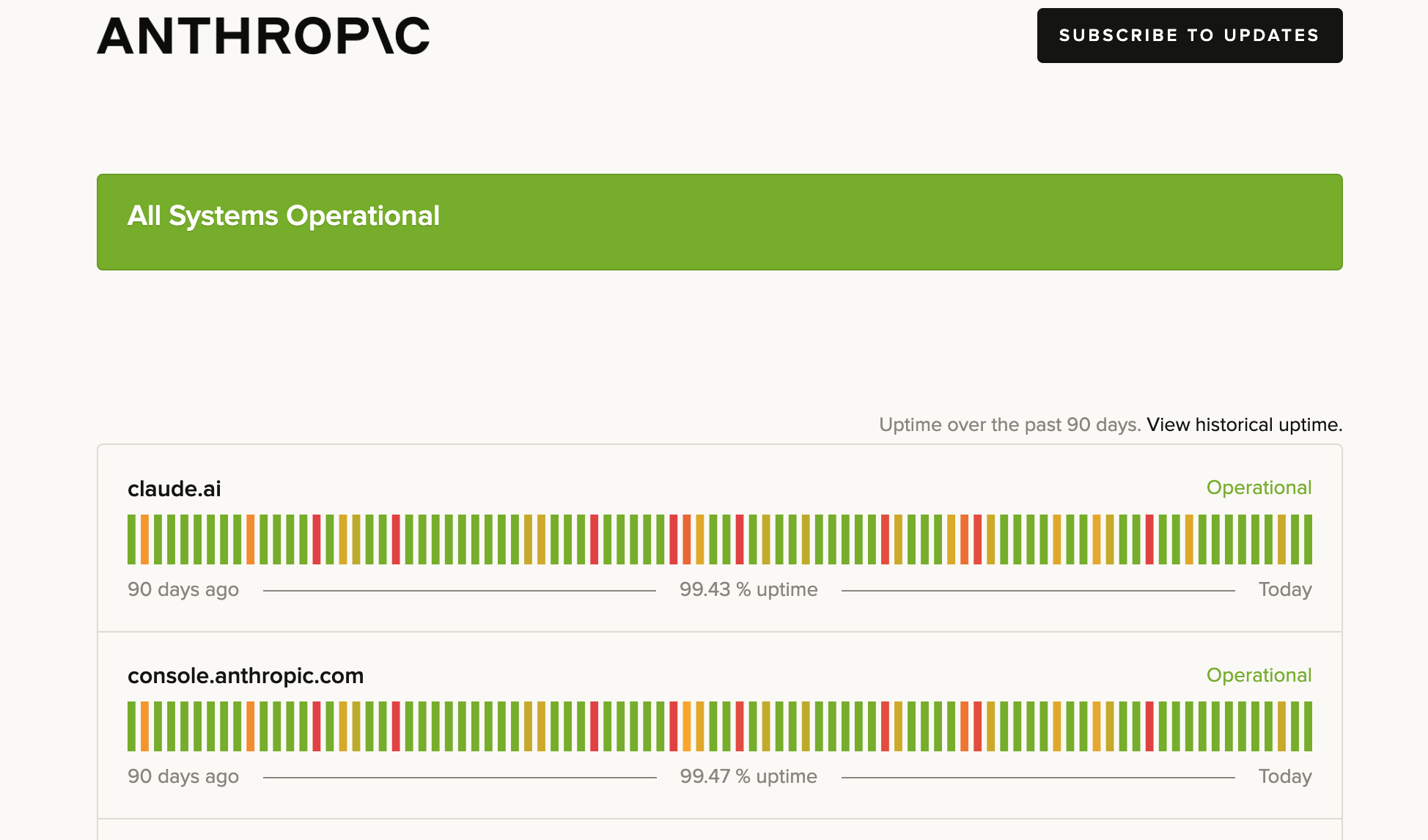
Model providers experience outages and downtimes. For e.g. here’s a screenshot of OpenAI’s and Anthropic’s status page from Feb to May 2025.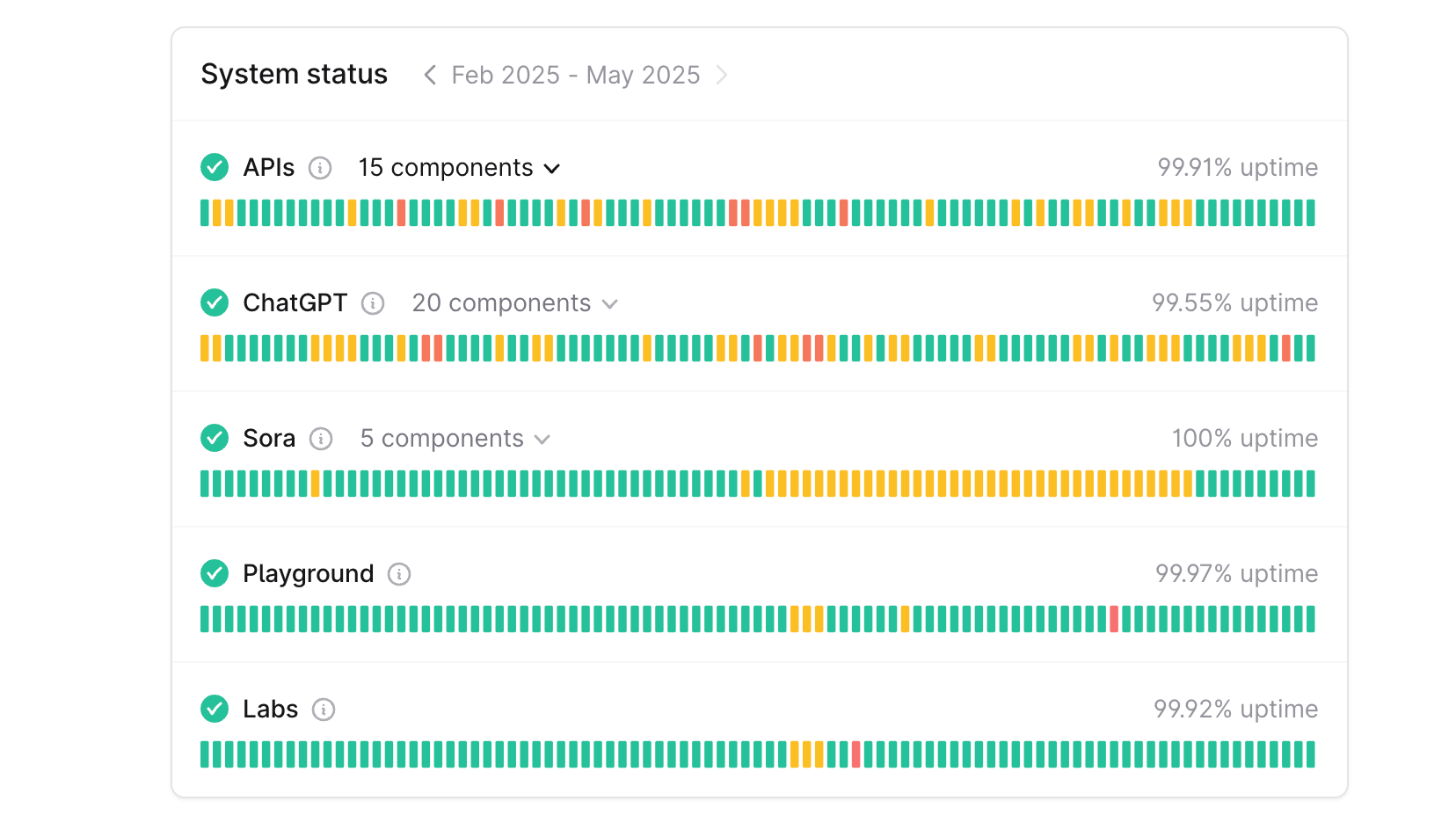
OpenAI Status Page
Anthropic Status Page
Latency Variance among models
Latency Variance among models
Latency and performance varies on time, region, model and provider. Here’s a graph of the latency variance of a few models over a course of a month.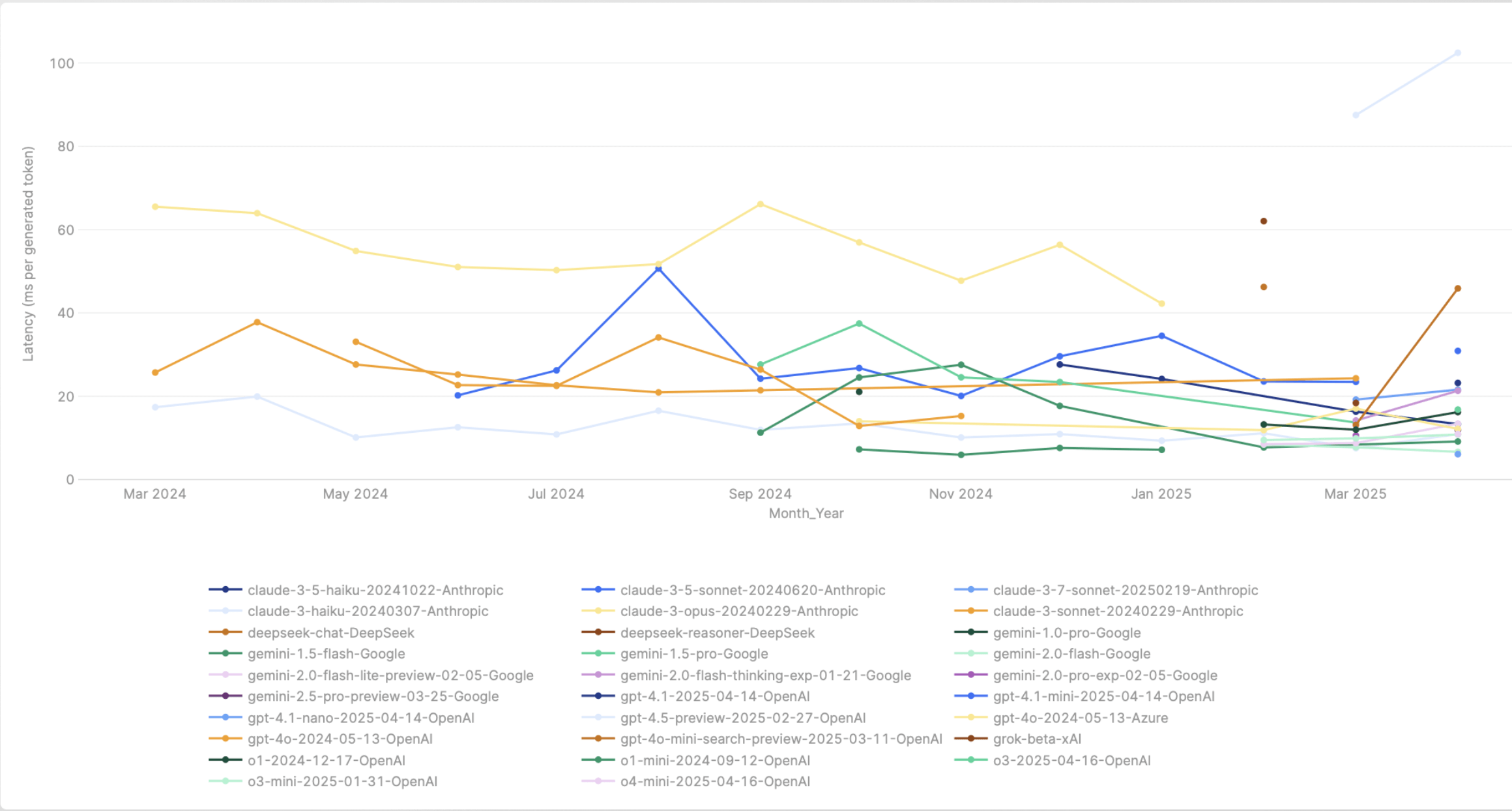
Latency Variance of models over a course of a month
Rate Limits of Models
Rate Limits of Models
A lot of the LLM providers enforce strict rate limits on API usage. Here’s a screenshot of Azure OpenAI’s rate limits: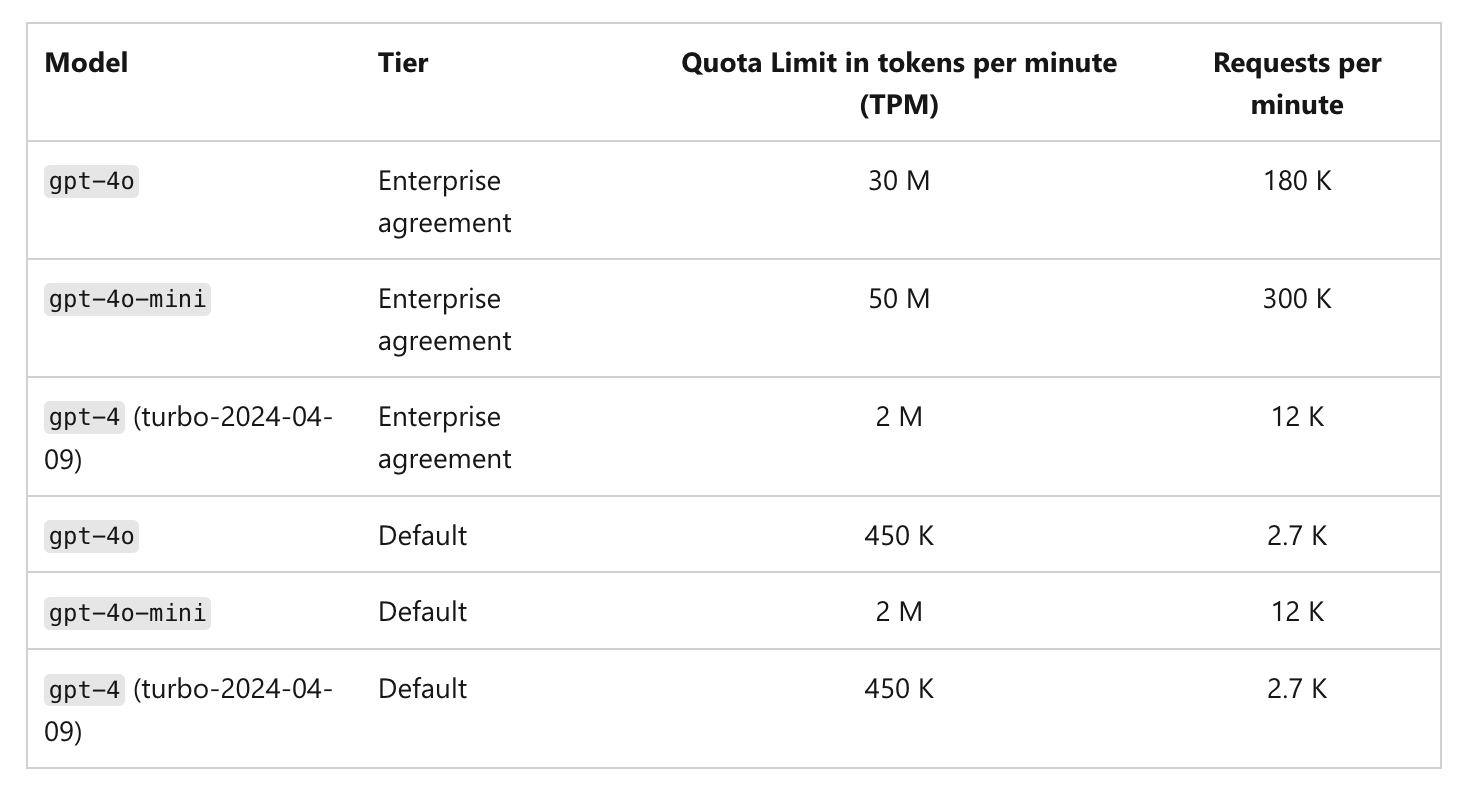
Azure OpenAI Rate Limits
Canary Testing
Canary Testing
Testing new models or updates in production carries significant risks. Dynamic load balancing can be used to route a small percentage of traffic to the new model and monitor the performance before routing all the traffic to the new model.
How TrueFoundry AI Gateway solves routing challenges?
TrueFoundry AI gateway enables us to configure load-balancing and fallback rules to enable routing to the most suitable model as defined by the user. The rules can be defined as part of a routing policy in which different rules can be defined for different subset of requests. A few examples are:- When request comes to the model
gpt-4o, route 90% of the requests toazure/gpt-4oand 10% toopenai/gpt-4o. - When request comes to the model
claude-3-opus, route 100% of the requests toanthropic/claude-3-opusand if there is a failure, fallback the request toanthropic/claude-3-sonnet.
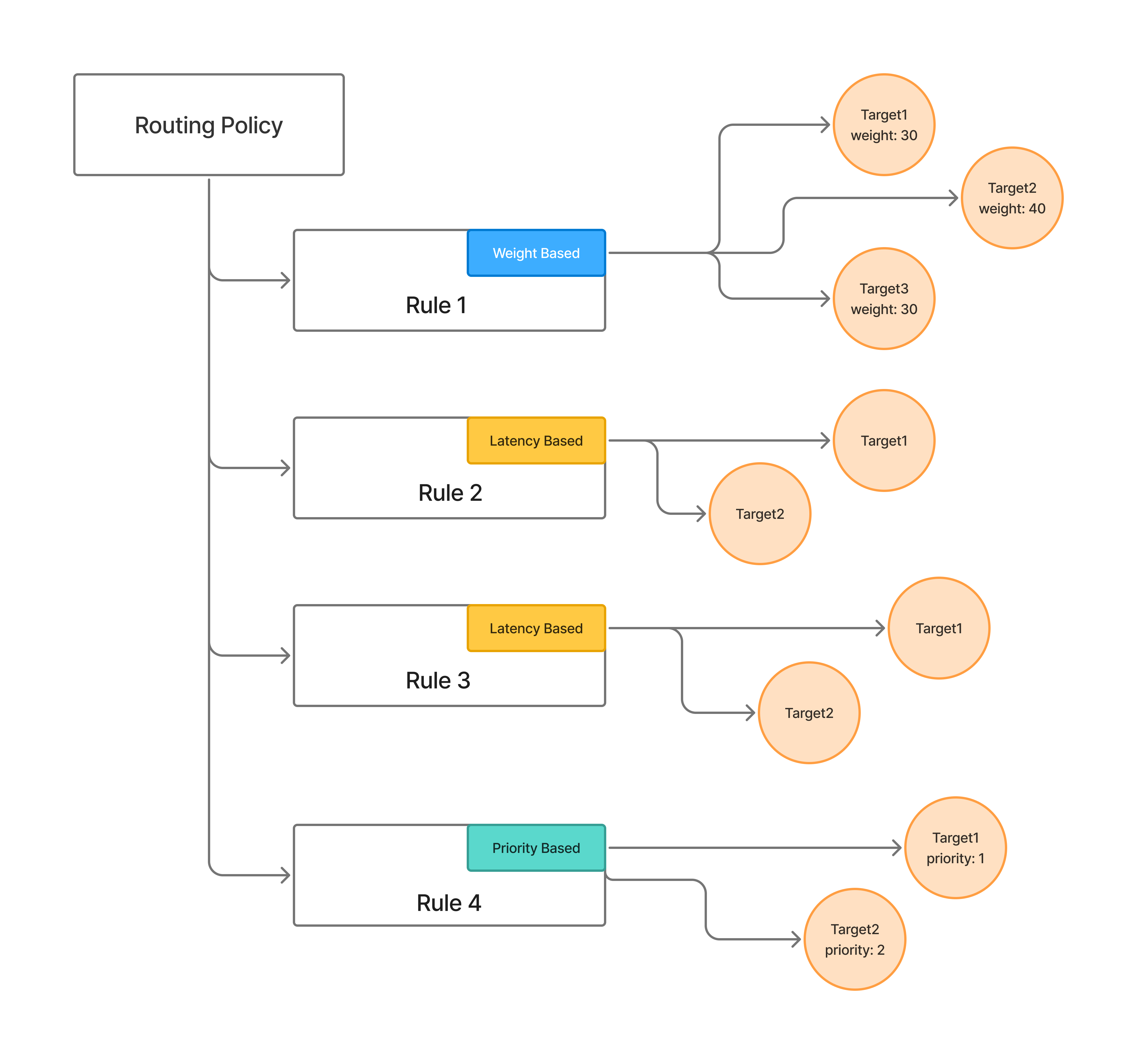
Weight-based Routing
Weight-based Routing
In weight-based routing, user assigns a weight to each target model. The gateway distributes incoming requests to the models in proportion to their assigned weights. For e.g., if a request for the model
gpt-4o is received, you can configure 90% of the requests to go to azure/gpt-4o and 10% to openai/gpt-4o.Latency-based Routing
Latency-based Routing
In case of latency-based routing, the user doesn’t need to define the weights for each of the target models. The gateway will automatically choose the model with the lowest latency. The lowest latency model is chosen based on the following algorithm:
- The time per output_token (inter-token latency) is used as a latency metric to evaluate the latency of the models.
- To calculate latency, only the requests in the last 20 mins are considered. If the count of requests in the last 20 mins is greater than 100, the last 100 requests are considered. If the count of requests in the last 20 mins is less than 100, all the requests are considered. If there are less than 3 requests in the last 20 mins, the latency is not derived and the model is considered as the fastest model so that more requests can be routed to it to get more data to derive the latency.
- Models are considered equally fast if their latency is within 1.2X of the fastest model - this is done to avoid rapid switching of models due to minor difference in latency.
Priority-based Routing
Priority-based Routing
In priority-based routing, the user defines a priority level for each target model. The gateway will route requests to the highest priority model (lowest priority number) that is healthy and available. If the highest priority model fails or becomes unavailable, the gateway will automatically fallback to the next highest priority model. Lower priority numbers indicate higher priority (0 is the highest priority).
The rules in a routing configuration are evaluated for a request serially and the first matching rule is applied. Subsequent rules are not evaluated.
Retry and Fallback Mechanisms
For each target model in a rule in the routing configuration, we can configure the following options about retry and fallback:- Retry Configuration: Define the number of attempts, delay between retries, and status codes that trigger retries. Default status codes to retry on are 429, 500, 502, 503.
- Fallback on failure of target: Define status codes that trigger fallback to other targets. Default values of status codes to fallback on are 401, 403, 404, 429, 500, 502, 503.
- Fallback candidate: Define if the target can be used as a fallback candidate - i.e. if another target model fails, can the request fallback to this target. Default value is true.
Configure Load Balancing on Gateway
The configuration can be added through the Config tab in the Gateway interface.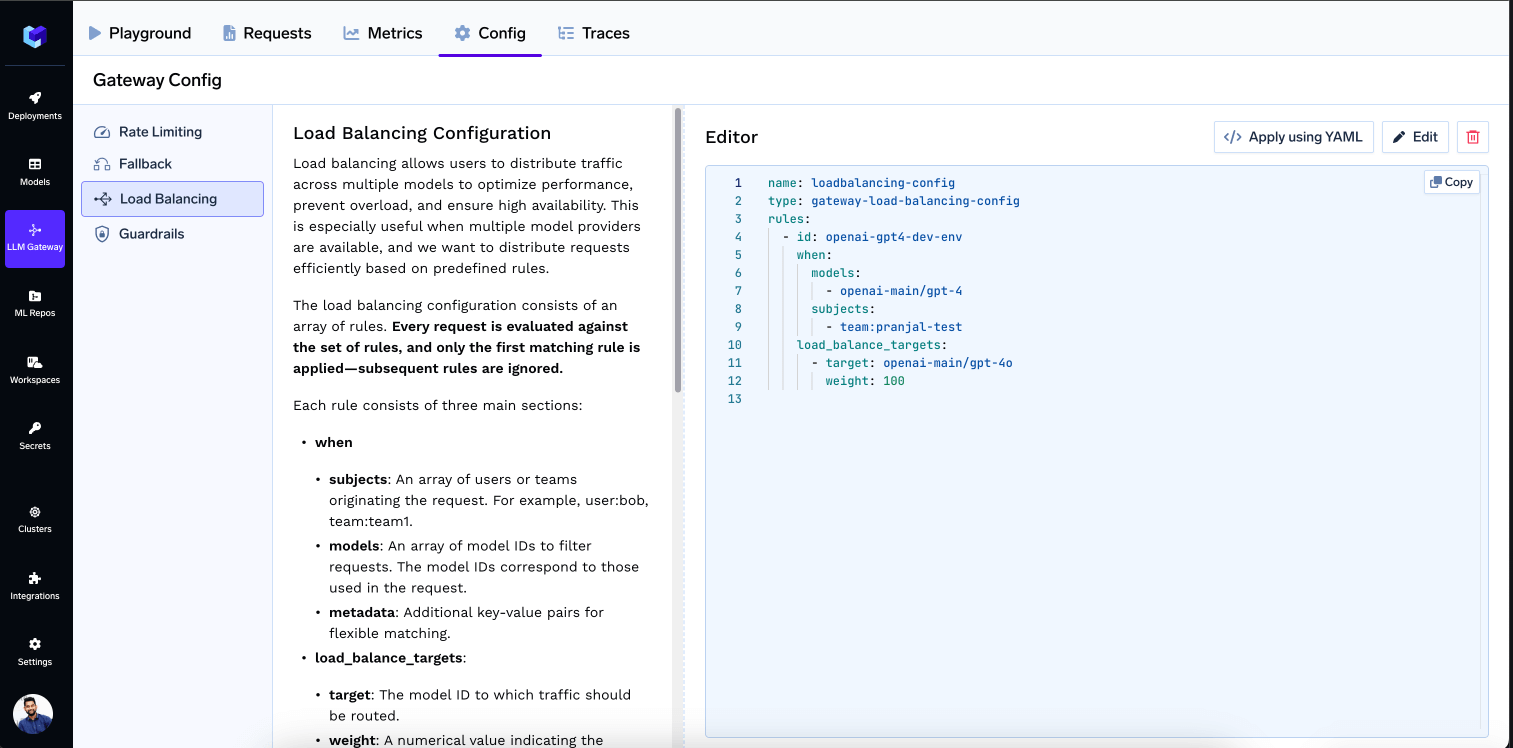
Load Balancing Configuration Interface
tfy apply command. This enables enforcing a PR review process for any changes in the load balancing configuration.