- type: The type should be
gateway-load-balancing-config. It helps the truefoundry platform identify that this is a load balancing configuration file. - name: The name can be anything like
<companyname>-gateway-load-balancing-config. The name is only used for logging purposes and doesn’t have any other significance. - rules: An array of rules, the datastructure for which is described in details below. Each rule defines the subset of requests to which the rule applies and the strategy to route the request. The rules are evaluated in the order they are defined. The first rule that matches the request is applied and all subsequent rules are ignored. Hence, it’s recommended to exactly define which subset of requests each rule applies to.
YAML Structure
rules
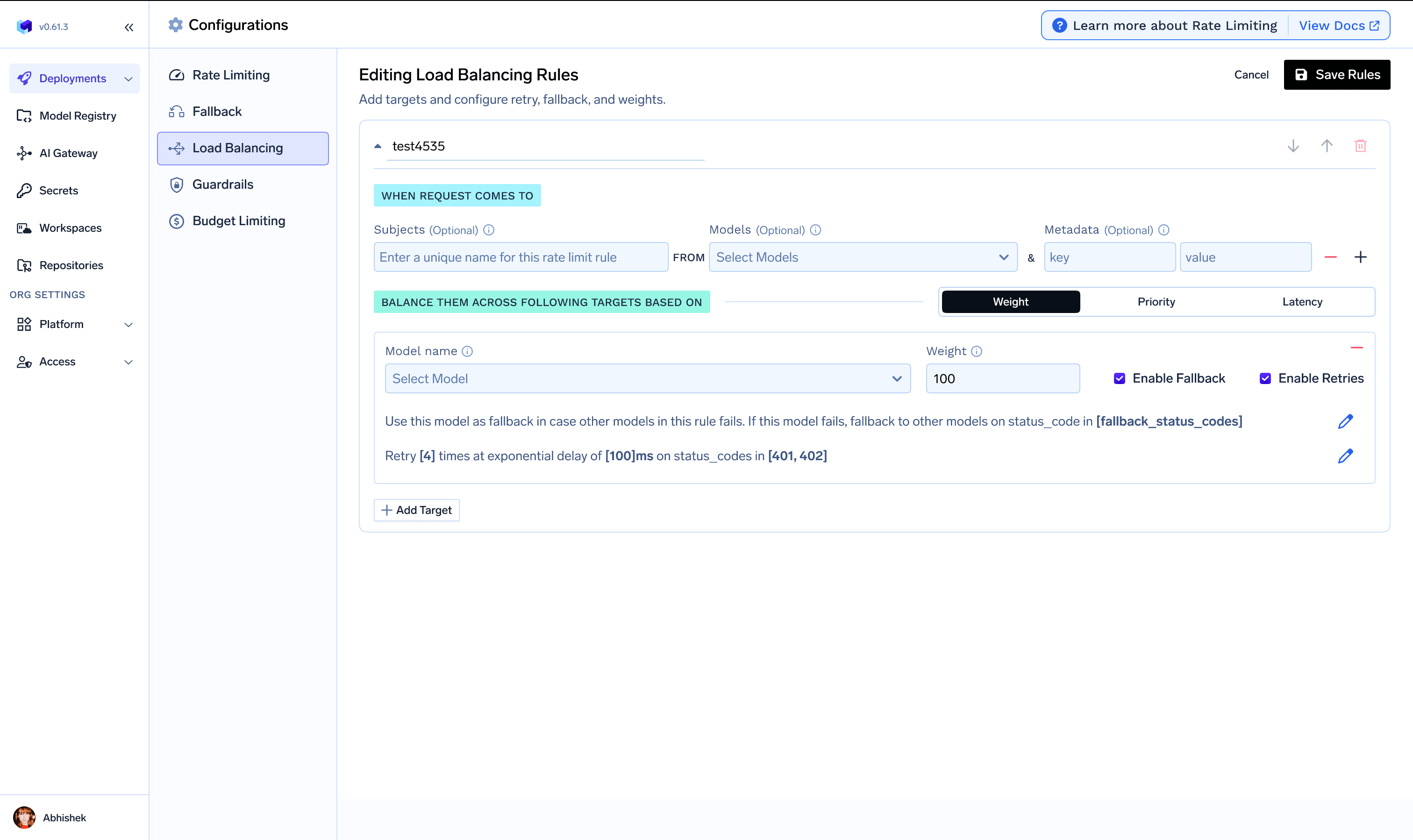
The rules section is the most important part of the load balancing configuration. It comprises of the following key parts:- id: A unique identifier for the rule. All rules in the array must have a unique id. This is used to identify the rule in logs and metrics.
-
when (Define the subset of requests on which the rule applies): TrueFoundry AI gateway provides a very flexible configuration
to define the exact subset of requests on which the rule applies. We can define based on the user calling the model, or the model name or any of the custom metadata key present in the request header
X-TFY-METADATA. The subjects, models and metadata fields are conditioned in an AND fashion - meaning that the rule will only match if all the conditions are met. If an incoming request doesn’t match the when block in one rule, the next rule will be evaluated.subjects: Filter based on the list of users / teams / virtual accounts calling the model. User can be specified usinguser:john-doeorteam:engineering-teamorvirtualaccount:acct_1234567890.models: Rule matches if the model name in the request matches any of the models in the list.metadata: Rule matches if the metadata in the request matches the metadata in the rule. For e.g. if we specifymetadata: {environment: "production"}, the rule will only match if the request has the metadata keyenvironmentwith valueproductionin the request headerX-TFY-METADATA.
-
type (Routing strategy): TrueFoundry AI gateways supports three routing strategies - weight-based, latency-based, and priority-based which are described below. The value of type field should be
weight-based-routing,latency-based-routing, orpriority-based-routingdepending on which strategy to use. To understand how these strategies work, check out how gateway does load balancing. -
load_balance_targets (
Models to route traffic to): This defines the list of models which will be eligible for routing requests for this rule. For each target, we can configure the following options:- Retry Configuration:
attempts: Number of retry attempts. Default value is 2.delay: Delay between retries in milliseconds (default value is 100ms)on_status_codes: List of HTTP status codes that should trigger a retry (Default value is:["429", "500", "502", "503"])
- Fallback Configuration:
fallback_status_codes: List of HTTP status codes that trigger fallback to other targets (Default value is:["401", "403", "404", "429", "500", "502", "503"])fallback_candidate: Boolean indicating whether this target can be used as a fallback option for other targets. Default values is true - meaning that this target can be used as a fallback option for other targets.
- Override Parameters: This allows you to override specific parameters for each target. This can be useful for setting different temperature values for different models, adjusting max_tokens based on model capabilities or configuring model-specific parameters. Example:
YAML- Weight (Only for Weight-based Routing): The weight of the target model. The weight is used to distribute the requests to the target models. The weight is a number between 0 and 100. Its a compulsory field for weight-based routing. The sum of weights for all targets in a rule should be 100.
- Priority (Only for Priority-based Routing): The priority of the target model. The priority is used to determine the order of the target models in case of fallback. The priority is a number between 0 and 100. Its a compulsory field for priority-based routing.
- Retry Configuration:
Commonly Used Routing Configurations
Here are a few examples of load balancing configurations for different use cases.Route all requests to azure/gpt4 by default. If azure/gpt4 is rate limited, route to openai/gpt4 and if that is also rate limited, route to anthropic/claude-3-opus.
Route all requests to azure/gpt4 by default. If azure/gpt4 is rate limited, route to openai/gpt4 and if that is also rate limited, route to anthropic/claude-3-opus.
Canary Deployment to gradually roll out a new gpt-4 model version.
Canary Deployment to gradually roll out a new gpt-4 model version.
Route all requests to onprem hosted llama model by default. If there is a sudden burst of traffic that exceeds the rate limits of the on-prem model, fallback to bedrock llama model. If bedrock model fails, retry twice on the model.
Route all requests to onprem hosted llama model by default. If there is a sudden burst of traffic that exceeds the rate limits of the on-prem model, fallback to bedrock llama model. If bedrock model fails, retry twice on the model.
Route to the fastest model between azure/gpt4 and openai/gpt4 at any point. If one of them is down, retry once and then fallback to the other model
Route to the fastest model between azure/gpt4 and openai/gpt4 at any point. If one of them is down, retry once and then fallback to the other model
If user is using gpt-4 in dev environment, then route to dev account. If user is using gpt-4 in prod environment, then route to the fastest model between azure/gpt4 and openai/gpt4
If user is using gpt-4 in dev environment, then route to dev account. If user is using gpt-4 in prod environment, then route to the fastest model between azure/gpt4 and openai/gpt4
Route user to the closest region model. If closest region model is down, or slow, route to the model in the other regions
Route user to the closest region model. If closest region model is down, or slow, route to the model in the other regions
Route traffic for paid customers to gpt5 model. For non-paid customers, use gpt4 model.
Route traffic for paid customers to gpt5 model. For non-paid customers, use gpt4 model.
Use the fastest model between openai/gpt4 and azure/gpt4 by default. If there is a failure on openai/gpt4, retry 2 times. Retry once for azure/gpt4. If both of them are unhealthy because of ratelimiting or any other errors, fallback to bedrock/claude. While calling claude model, change the temperature to 0.5. Apply this only in production for an application called booking-app.
Use the fastest model between openai/gpt4 and azure/gpt4 by default. If there is a failure on openai/gpt4, retry 2 times. Retry once for azure/gpt4. If both of them are unhealthy because of ratelimiting or any other errors, fallback to bedrock/claude. While calling claude model, change the temperature to 0.5. Apply this only in production for an application called booking-app.