Prerequisites
To log data from your job runs, you need access to an ML Repository (MLRepo). ML Repositories store models, data, artifacts, and prompts and are backed by blob storage like S3, GCS, or Azure Blob Storage.Setting up ML Repository Access
Setting up ML Repository Access
Step 1: Create or Access an ML Repository
If you don’t have an ML Repository yet, you’ll need to create one:-
Prerequisite - Blob Storage Integration: Before creating a Repository, connect one or more Blob Storages to TrueFoundry:
- AWS S3
- Google Cloud Storage
- Azure Blob Storage
- Any S3 API Compatible Storage
- Create Repository: Go to Platform → Repositories tab and create a new ML Repository
Grant ML Repository Access to Workspace
To enable your job to log data, you need to grant access to the ML Repository for your workspace:- Go to Platform → Workspaces tab
- Edit your workspace
- In the “ML Repositories” section, grant access to your ML Repository
- Choose appropriate permissions (Viewer or Editor)
Creating Run and Logging Data
A run is used to represent a single ML experiment. You can create a run at the beginning of your script or notebook, log parameters, metrics, artifacts, models, tags and finally end the run. This provides an easy to keep track of all data related to ML experiments. A quick code snippet to create a run and end it:svm-model will be created under the ml_repo iris-demo.
Once you’ve created runs and logged data, you can view them in the TrueFoundry dashboard. Navigate to your job in the Platform → Applications tab, click on the job name, and go to the “Job Runs” tab to see all executions with their status, metrics, and parameters.

Job Runs Dashboard - Example showing multiple runs with different statuses
Logging Different Types of Data
Creating a run and ending it
Creating a run and ending it
Python
Adding tags to a run
Adding tags to a run
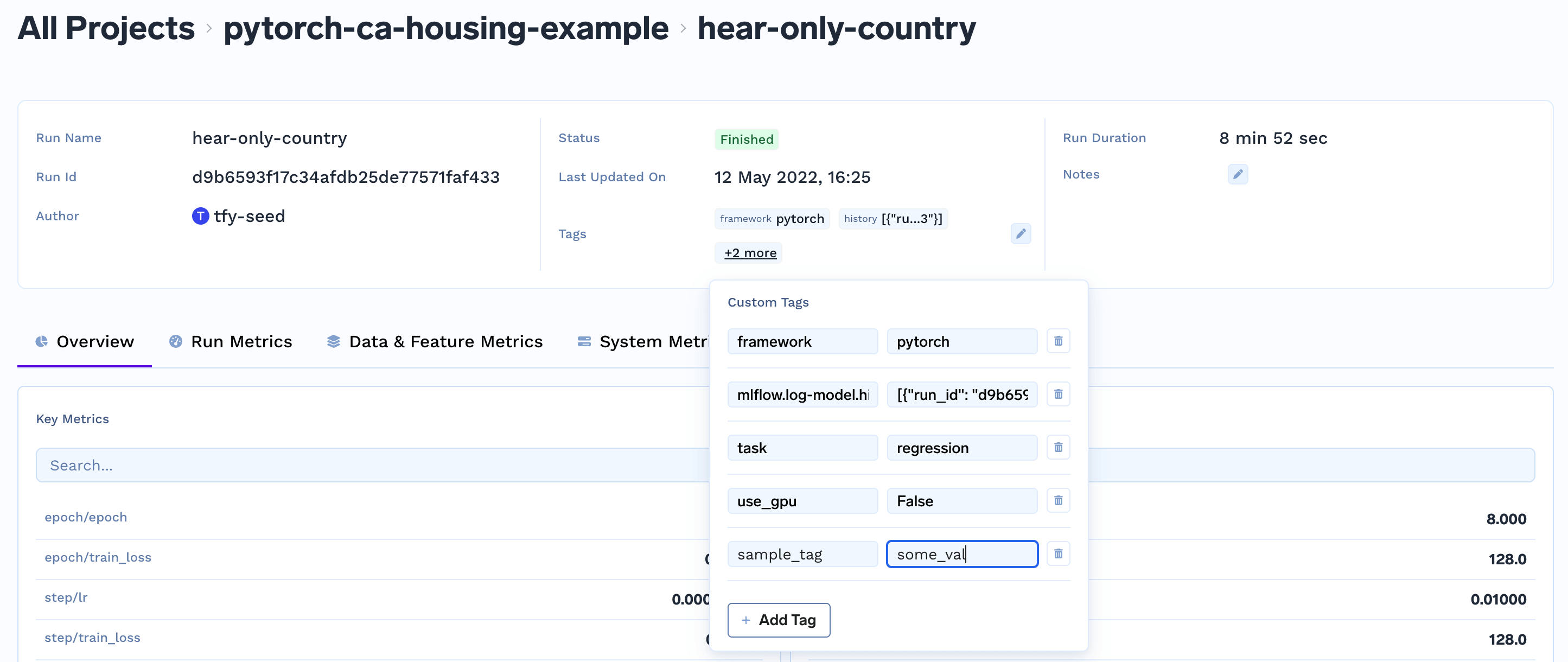
Logging parameters
Logging parameters
Parameters are used to store the configuration of a run. This can be either the inputs to your script or the hyperparameters of your model during training like 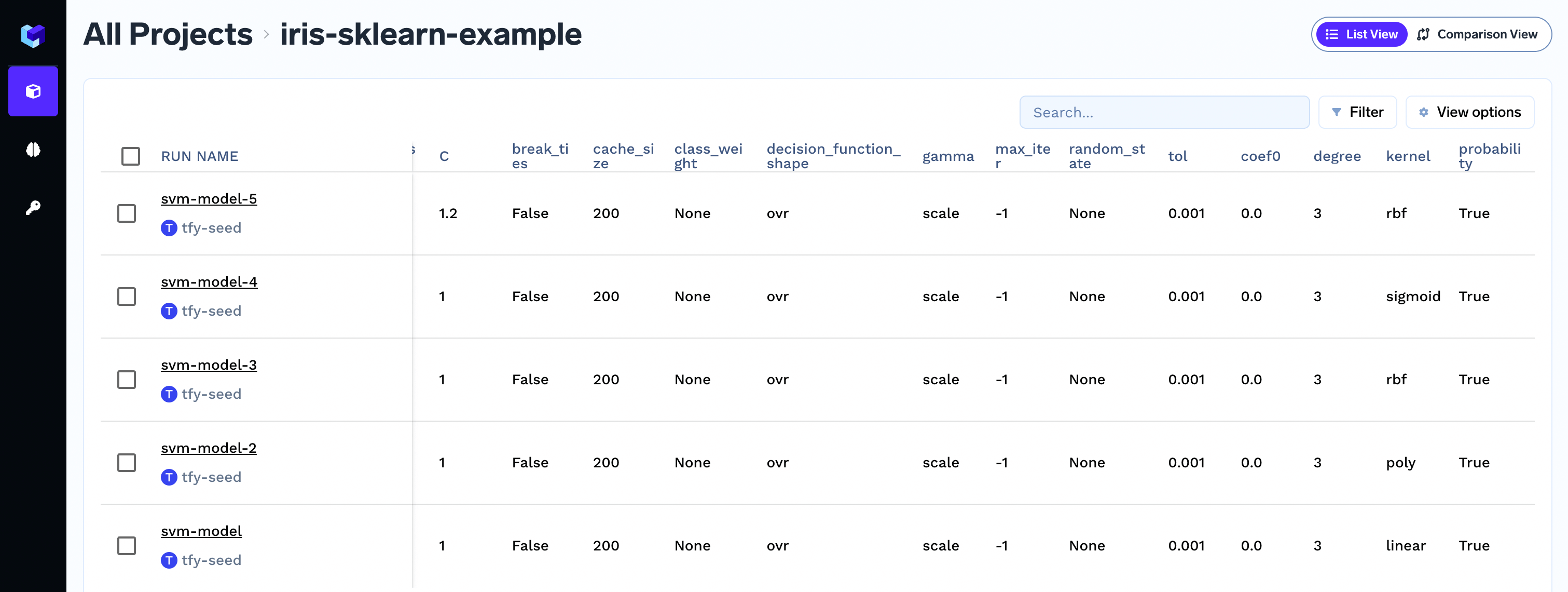
learning_rate, cache_size.
The parameter values are stringified before storing.You can log parameters using the log_params as shown below:Parameters are immutable and you cannot change the value of param once logged.
If you need to change the value of param, it basically means that you are
changing your input configuration and it’s best to create a new run for that.
Viewing logged parameter in the dashboard
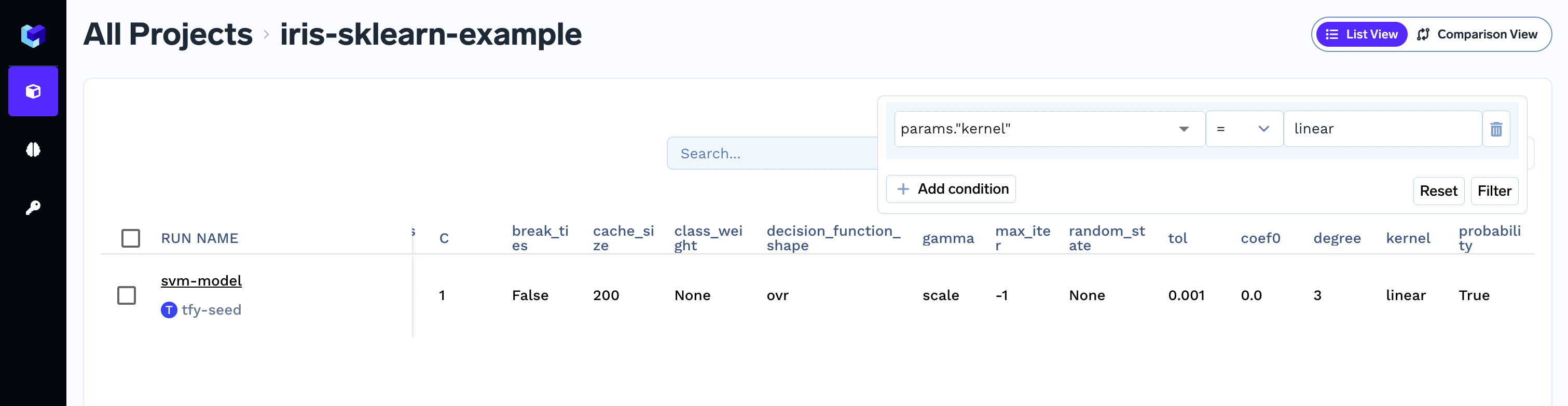
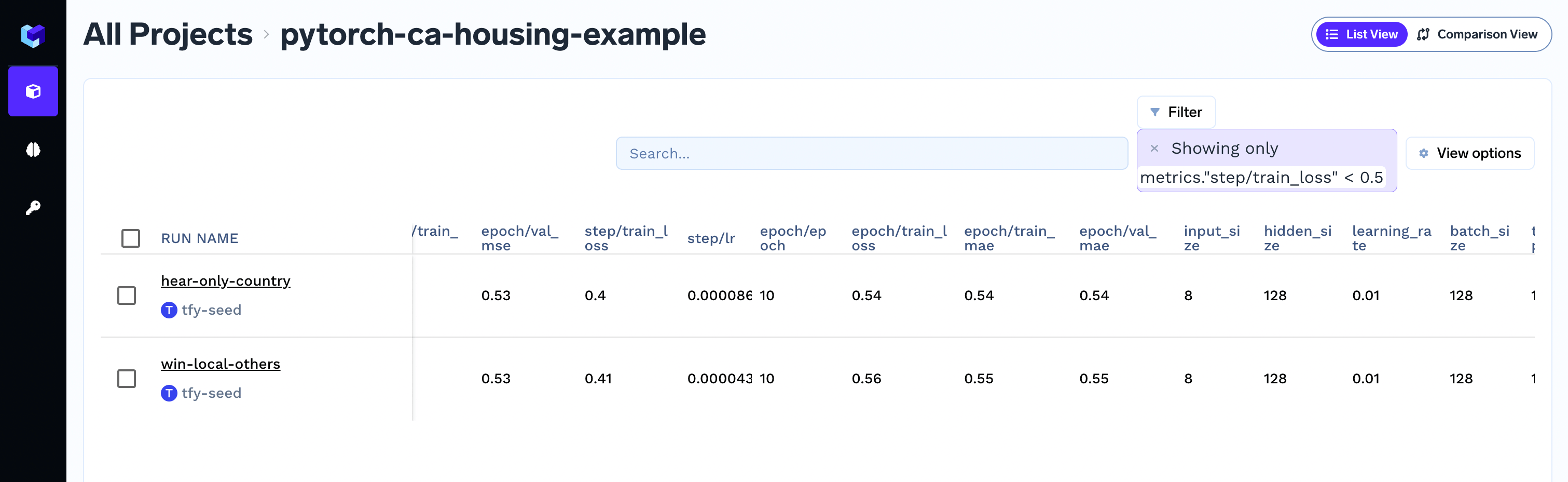
Filtering runs based on parameter value
To filters runs, click on top right corner of the screen to apply the required filter.Capturing command-line arguments in the run
We can capture command-line arguments directly from theargparse.Namespace object.Logging metrics
Logging metrics
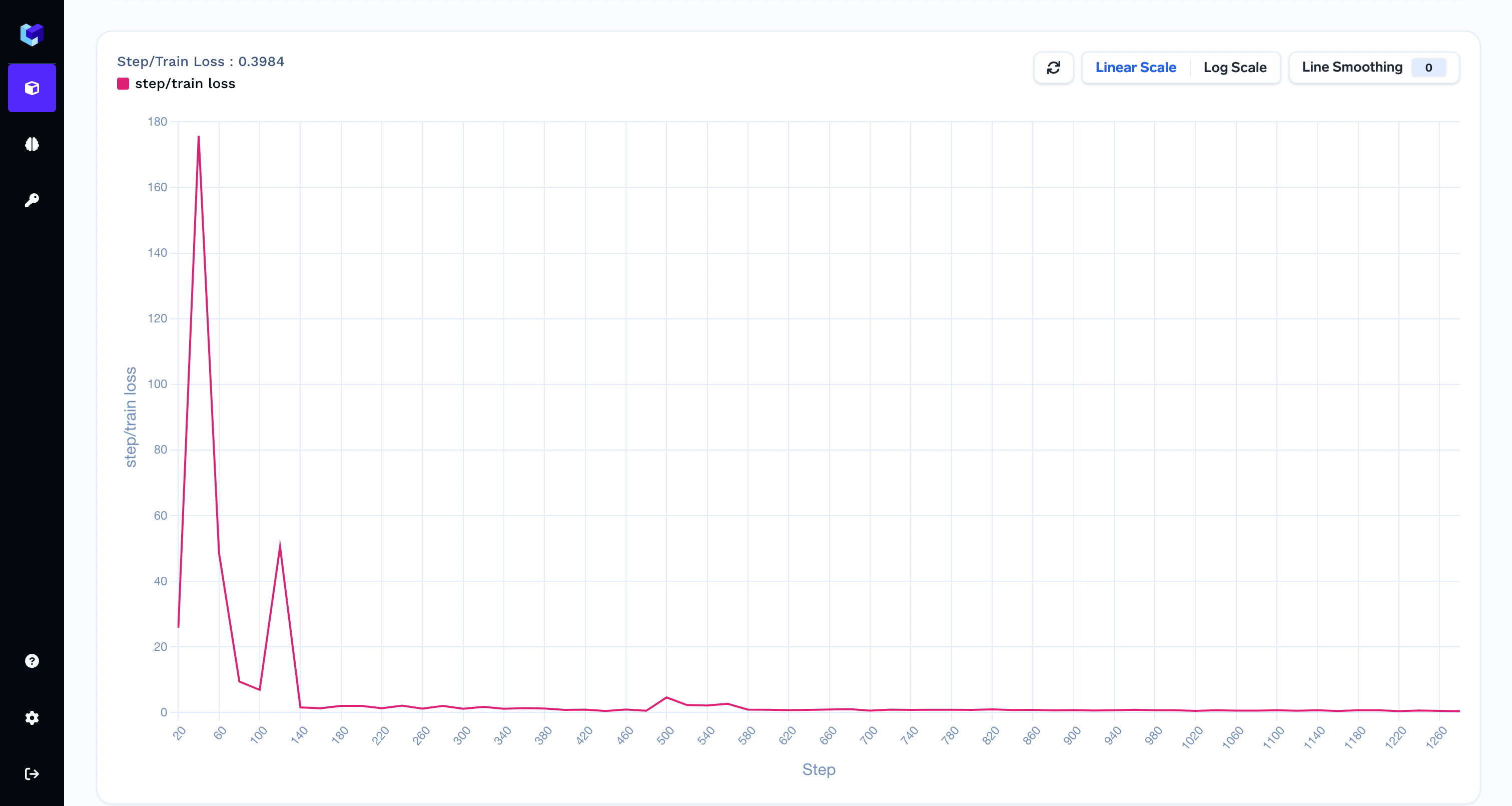
Metrics are values that help you to evaluate and compare different runs - for e.g. These metrics can be seen in Truefoundry dashboard. Filters can be used on metrics values to filter out runs as shown in the figure.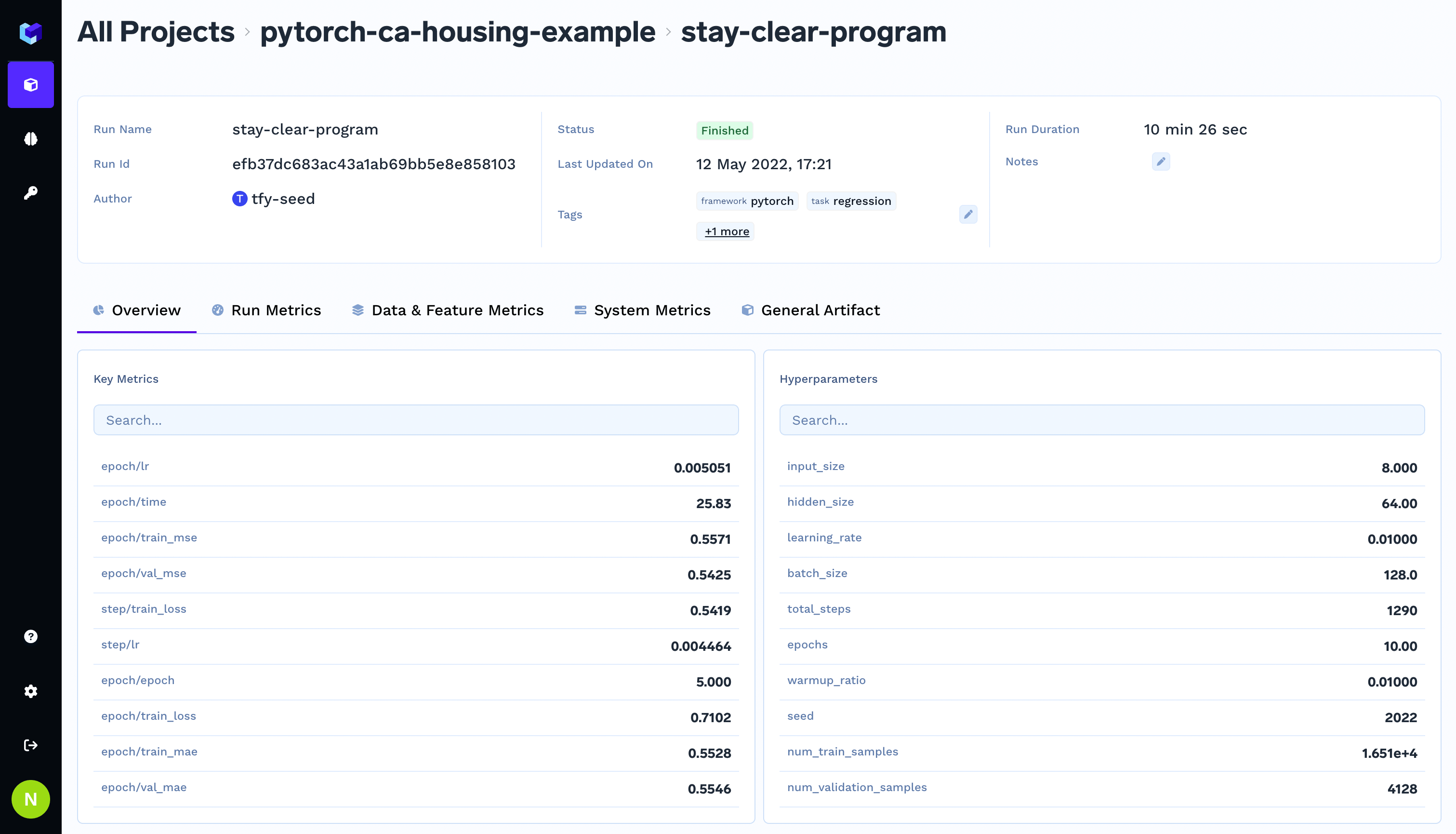
Should I use epoch or global step as a value for the
If available you should use the global step as a value for the
accuracy, f1 score. You can log any output of your script as a metric.You can capture metrics using the log_metrics method.Metrics Overview
Filter runs on the basis of metrics
Step-wise metric logging in the run
You can capture step-wise metrics too using thestep argument.Step-wise metrics
Should I use epoch or global step as a value for the step argument in the run?
If available you should use the global step as a value for the step argument. To capture epoch-level metric aggregates, you can use the following pattern.Log Artifacts
Log Artifacts
Log Models
Log Models
Log Images
Log Images
You can also log images in different steps in a run. Images can be associated with a step number, in case you are running multiple epochs in training and want to log the images at different steps.Here is the sample code to log images from different sources:Images are represented and logged using this class in TrueFoundry.You can initialize The logged images can be visualized in the TrueFoundry dashboard.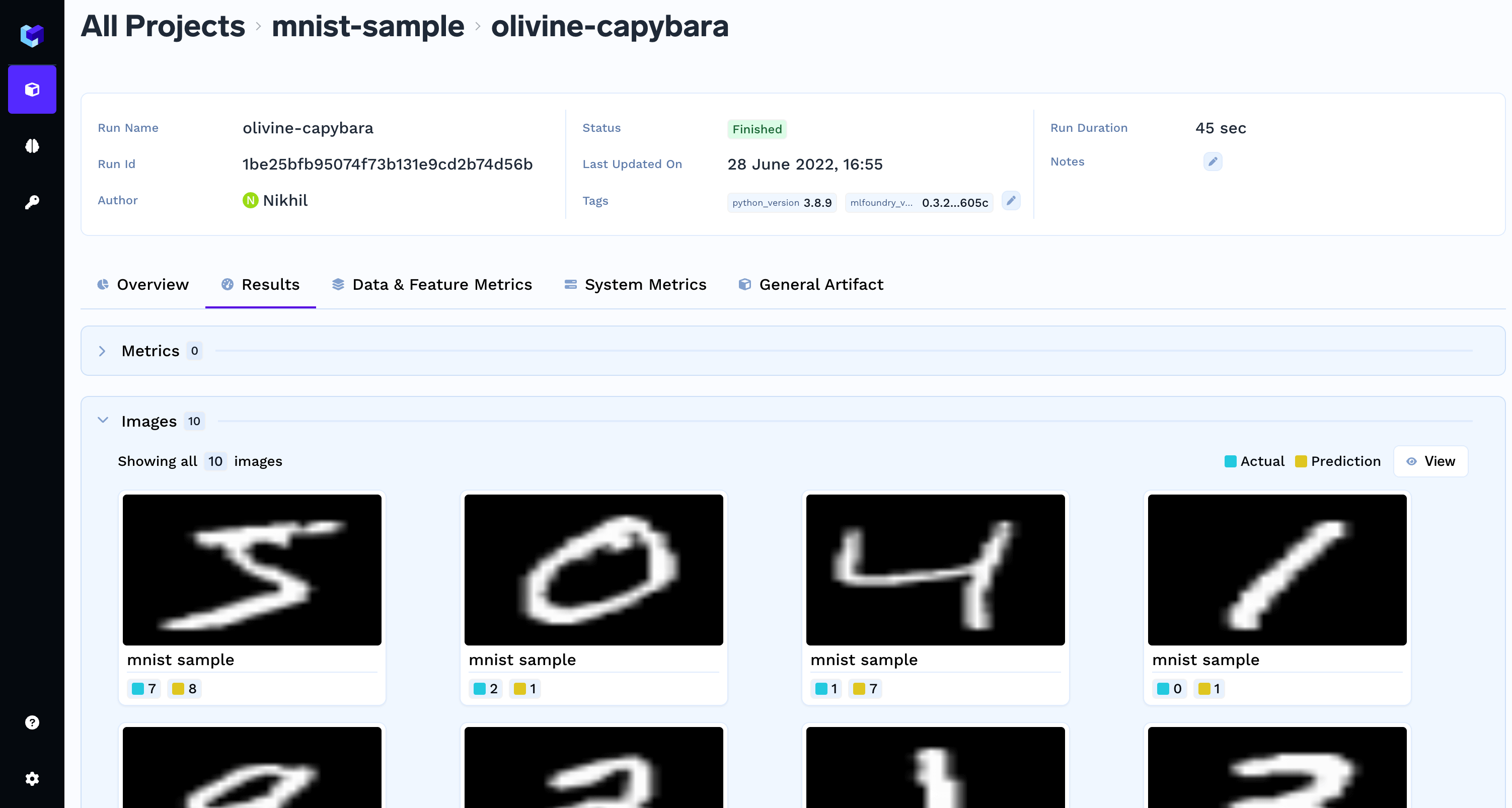
PIL package is needed to log images. To install the PIL package, runtruefoundry.ml.Image by either by using a local path or you can use a numpy array / PIL.Image object.You can also log caption and the actual and predicted values for an image as shown in the examples below.Logging images with caption and a class label
Log Plots
Log Plots
You can also log plots in a run and visualize them in the TrueFoundry Dashboard. You can associate a plot with a step number, in case you are running multiple epochs in training and want to log the plots at different steps.You can log custom matplotlib, plotly plots as shown in examples below:You can visualize the logged plots in the TrueFoundry Dashboard.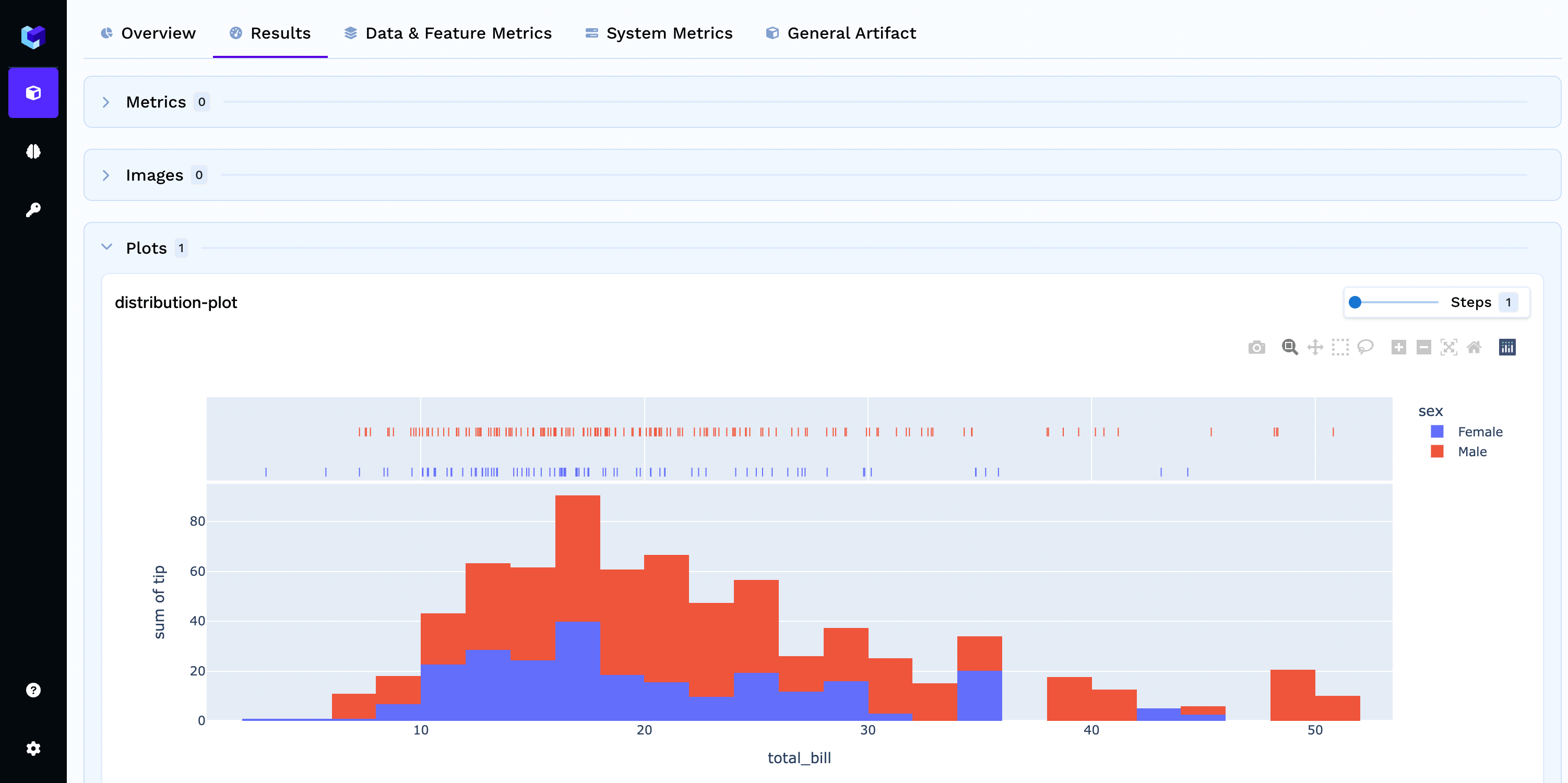
- Matplotlib Plot
- Seaborn Plot
- Plotly Plot
Complete Examples
Here are comprehensive examples that demonstrate how to deploy a job and log data during machine learning training:MNIST Training Script with Logging
MNIST Training Script with Logging
This example shows the complete training script that logs parameters, metrics, plots, and models:
Key Features Demonstrated:
- Parameter Logging: Hyperparameters like learning rate, epochs, and model configuration
- Metrics Logging: Training and validation accuracy/loss for each epoch
- Plot Logging: Sample images from the dataset
- Model Logging: Saved model with metadata and framework information
- Tag Organization: Categorizing the run for easy filtering
- Error Handling: Proper exception handling to ensure runs are marked correctly
Deploy MNIST Training Job
Deploy MNIST Training Job
This example shows how to deploy a parameterized job that can be run multiple times with different configurations:
Key Features:
- Parameterized Job: Uses
Paramobjects to make the job configurable - Python Build: Automatically builds the container from source code
- Resource Configuration: Specifies CPU and memory requirements
- ML Repository Integration: Links to an ML repository for logging
Accessing Detailed Run Information
In the Job Runs table, you’ll notice that the “RUN DETAILS” column contains clickable links. When you click on any run details link, you’ll be taken to a comprehensive view of that specific run, which includes:- Overview Tab: Key metrics and hyperparameters used in the run
- Results Tab: Detailed metrics and performance data
- Models Tab: All logged models with their metadata
- Artifacts Tab: Files and artifacts associated with the run
Pro Tip: Use the run details view to analyze your experiments, compare
different hyperparameter configurations, and track the progress of your
machine learning projects over time.