- FastAPI: This is simple to understand and use. This works quite well in case your traffic is not very high (less than 20 requests/second>)
- Triton: This is more performant model server and is suitable for high traffic use cases. It comes with batching support which helps provide higher througput.
Log the model in the model registry
You will need to setup CLI before executing the following steps.
Generate the inference code
- Locate the model you want to deploy in the model registry and click the Deploy button.

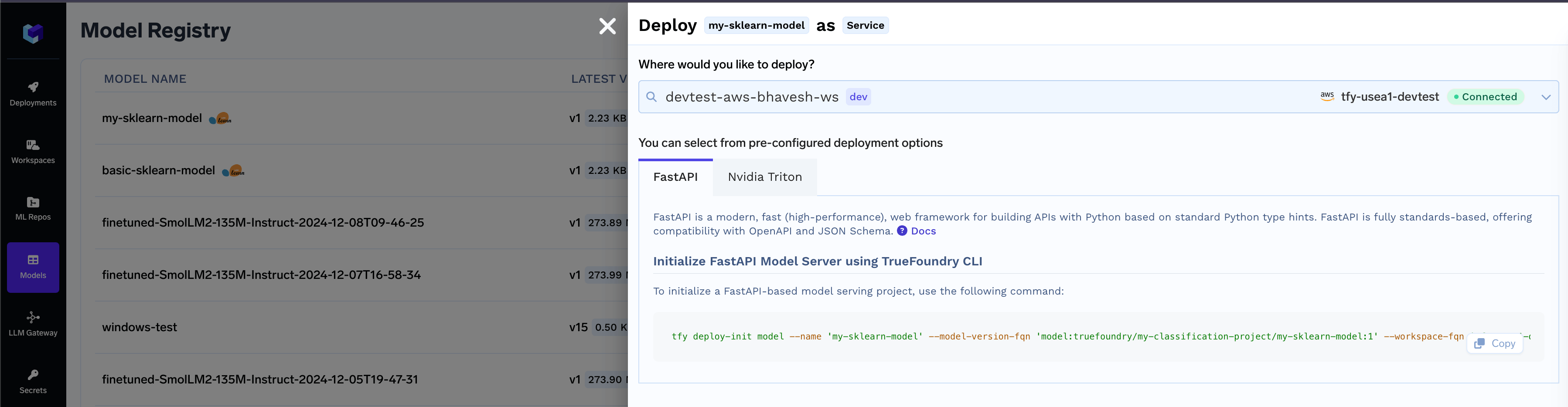
- Execute the command in your terminal to generate the model deployment package.
- Follow the instructions present on the
README.mdto deploy the code and get an endpoint for the model.
Common Issues and FAQ
Deploy Button is not showing up next to a SkLearn/XGBoost model in the model registry
Deploy Button is not showing up next to a SkLearn/XGBoost model in the model registry
Python version < 3.8 and > 3.12 is not supported for Triton deployment
Python version < 3.8 and > 3.12 is not supported for Triton deployment
The Triton deployment depends on the nvidia-pytriton library (https://pypi.org/project/nvidia-pytriton/) which supports
Python versions >=3.8 and <=3.12. If you need to use a version outside this range, consider using FastAPI as an alternative framework for serving the model.Numpy version must be less than 2.0.0 for Triton deployment
Numpy version must be less than 2.0.0 for Triton deployment
The nvidia-pytriton library specifies in its pyproject.toml file that it does not support numpy versions < 2.0. This limitation has been confirmed through practical experience. If you need to use a version outside this range, consider using FastAPI as an alternative framework for serving the model.