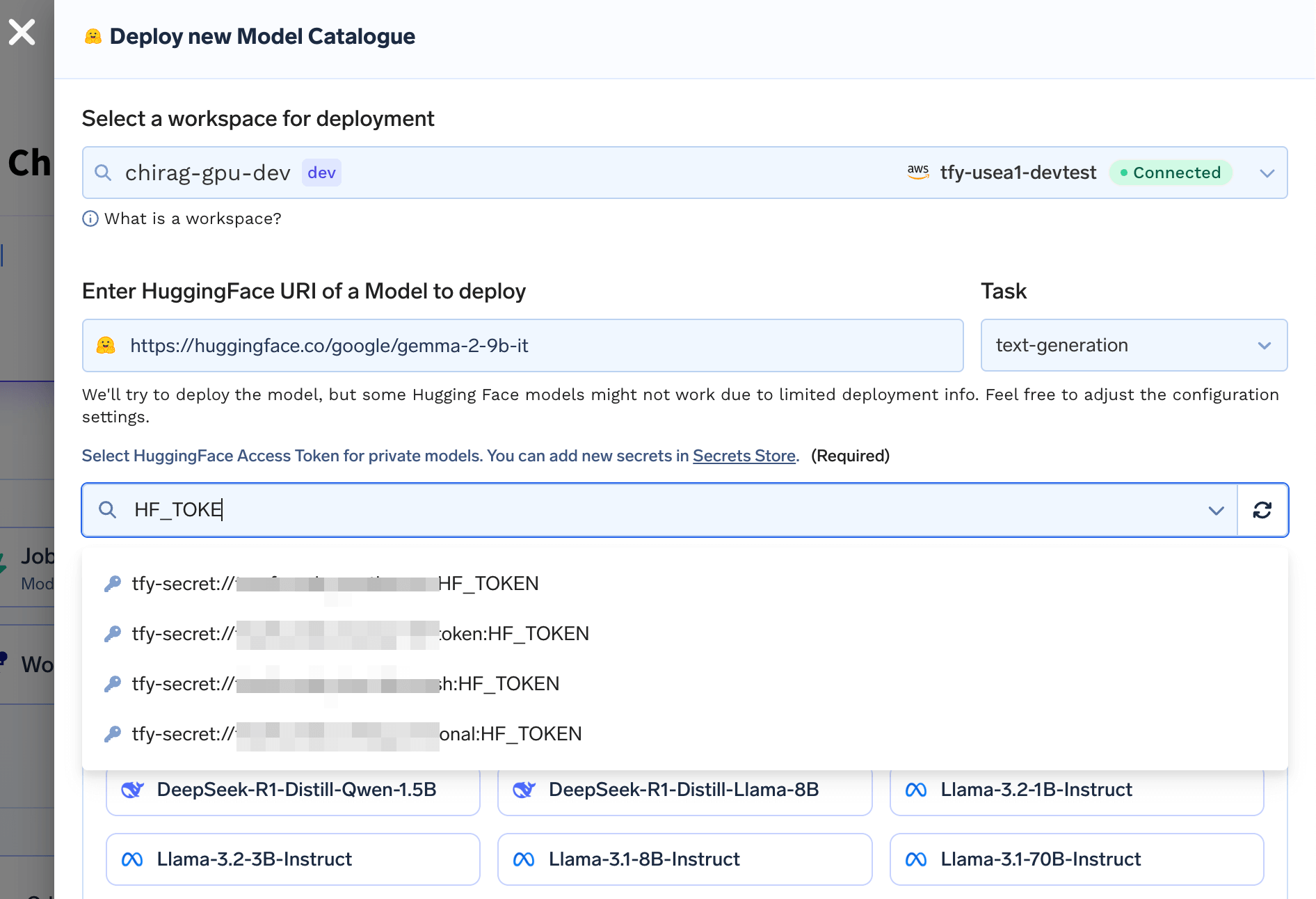
Deploying any model from HuggingFace Hub using optimized model servers
You can provide link to any HuggingFace model and TrueFoundry will be automatically able to deploy the model as an API. We analyze the HuggingFace model tags and files to understand which is the deployment framework
to serve the model and automatically generate the deployment manifests for the model.
Some models might not be supported or might need additional inputs since the HuggingFace tags might be missing or incorrect.
In some cases, you might need a HuggingFace token to access the model. This is needed if you are trying to download your own private models or using gated models like Llama which require you to accept the license and terms of use.In this case, you will need to create a secret with your HuggingFace token. You can create a secret following the guide here.You will be asked to provide the secret name as input.
Here’s the list of the most commonly used task types that are supported in TrueFoundry and how to infer from the model endpoint.
We support other tasks on a best effort basis. You can find the input formats for them here
LLMs (text-generation) and VLMs (image-text-to-text)
We use vLLM, SGLang or TRT-LLM to deploy these models.To read more on the deployment of LLMs, please refer to the LLM Deployment guide.
Embedding (sentence-similarity and feature-extraction)
If the model is trained using sentence-transformers library we use Text-Embeddings Inference or Infinity to deploy these models.You can use OpenAI SDK to generate embeddings from the model.
Copy
Ask AI
from openai import OpenAIendpoint = "<Enter service endpoint>"sub_path = "/v1"url = endpoint + sub_pathmodel_name = "<deployed model name>" # `MODEL_NAME` environment variable in the deployment manifestclient = OpenAI(api_key="EMPTY", base_url=url)response = client.embeddings.create( input="Sample text to embed", model=model_name,)output = [embed.embedding for embed in response.data]print(output)
Ranking (sentence-similarity and feature-extraction)
import requestsendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathdef infer(): payload = { "inputs": "I have a problem with my iphone that needs to be resolved asap!!", # The candidate labels which you want to classify the text into. "parameters": { "candidate_labels": "urgent, not urgent, phone, tablet, computer", # If there are more than two classes, set this to True. "multi_class": True, }, } response = requests.post(url=url, json=payload) return response.json()print(infer())
The output will look something like this.
Copy
Ask AI
{ "sequence": "I have a problem with my iphone that needs to be resolved asap!!", "labels": [ "urgent", "phone",... ], "scores": [ 0.998576283454895, 0.9949977993965149,... ]}
import requestsendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathdef infer(): # The text string which you want to get classification for. payload = { "inputs": "My name is Sarah and I live in London" } response = requests.post(url=url, json=payload) return response.json()print(infer())
The output will be subject to change based on the mode, for NER classification it would look like this.
import requestsendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathdef infer(): # The text string which you want to get classification for. payload = { "inputs": "The goal of life is [MASK]." } response = requests.post(url=url, json=payload) return response.json()print(infer())
The output will be the array of words with the percentage of how likely a work can fit and replace [MASK]
Copy
Ask AI
[ { "score": 0.1093330830335617, "token": 2166, "token_str": "life", "sequence": "the goal of life is life." },...]
import requestsendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathdef infer(): # The text string which you want to get Summarization for. payload = { "inputs": """ TrueFoundry is a Cloud-native PaaS for Machine learning teams to build, deploy and ship ML/LLM Applications on their own cloud/on-prem Infra in a faster, scalable, cost efficient way with the right governance controls, allowing them to achieve 90% faster time to value than other teams. TrueFoundry abstracts out the engineering required and offers GenAI accelerators - LLM PlayGround, LLM Gateway, LLM Deploy, LLM Finetune, RAG Playground and Application Templates that can enable an organisation to speed up the layout of their overall GenAI/LLMOps framework. Enterprises can plug and play these accelerators with their internal systems as well as build on top of our accelerators to enable a LLMOps platform of their choice to the GenAI developers. TrueFoundry is modular and completely API driven, has native integration with popular tools in the market like LangChain, VectorDBs, GuardRails, etc. """ } response = requests.post(url=url, json=payload) return response.json()print(infer())
The output will be summarized text.
Copy
Ask AI
[ { "summary_text": "TrueFoundry is a Cloud-native PaaS for Machine learning teams to build, deploy and ship ML/LLM Applications on their own cloud/on-prem Infra in a faster, scalable, cost efficient way . Enterprises can plug and play these accelerators with their internal systems as well as build on top of our accelerators to enable a LLMOps platform of their choice to the GenAI developers ." }]
import requestsdef infer(image_path, url): # Open the image file in binary mode with open(image_path, 'rb') as image_file: # Send the POST request headers = { "accept": "application/json", "Content-Type": "image/png" } response = requests.post(url, headers=headers, data=image_file) # Check the response if response.status_code == 200: print("Success:", response.json()) else: print("Failed:", response.status_code, response.text)# Example usageimage_path = "<Enter path to the image on your local>" # Replace with your image file nameendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathsend_image(image_path, url)
In this, the response will be the array of objects that will have the confidence percentage of the prediction and the prediction category.
import requestsdef infer(image_path, url): # Open the image file in binary mode with open(image_path, 'rb') as image_file: # Send the POST request headers = { "accept": "application/json", "Content-Type": "image/png" } response = requests.post(url, headers=headers, data=image_file) # Check the response if response.status_code == 200: print(response.json()) else: print("Failed:", response.status_code, response.text)# Example usageimage_path = "<Enter path to the image on your local>" # Replace with your image file nameendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathinfer(image_path, url)
The output will contain the labels along with the co-ordinates of box
import requestsdef infer(image_path, url): # Open the image file in binary mode with open(image_path, 'rb') as image_file: # Send the POST request headers = { "accept": "application/json", "Content-Type": "image/png" } response = requests.post(url, headers=headers, data=image_file) # Check the response if response.status_code == 200: print(response.json()) else: print("Failed:", response.status_code, response.text)# Example usageimage_path = "<Enter path to the image on your local>" # Replace with your image file nameendpoint = "<Enter service endpoint>"predict_path = "/predictions/model"url = endpoint + predict_pathinfer(image_path, url)
The response will be something like this
Copy
Ask AI
[{"generated_text": "a painting of people around a fire with money flying around"}]
For whisper models, we use Nvidia PyTriton to deploy these models.
Copy
Ask AI
import requestsimport osendpoint = "<Enter service endpoint>"predict_path = "/transcribe"url = endpoint + predict_pathdef infer(file_path, url): with open(file_path, 'rb') as f: files_to_upload = { 'file': (os.path.basename(file_path), f, 'audio/mpeg') } print(f"Uploading {file_path} to {url}...") response = requests.post( url, data={"parameters": json.dumps({"return_timestamps": True})}, files=files_to_upload ) response.raise_for_status() print(response.json())file_path = "<Enter path to the audio file on your local>" # Replace with your audio file nameinfer(file_path, url)
The output will be the transcription of the audio file.
Copy
Ask AI
{ "text": " My dear Fanny, you feel these things a great deal too much. I am most happy that you like the chain.", "chunks": [ { "timestamp": [ 0, 3.76 ], "text": " My dear Fanny, you feel these things a great deal too much." }, { "timestamp": [ 3.76, 5.84 ], "text": " I am most happy that you like the chain." } ]}