What is OpenAI Moderation?
OpenAI Moderation is a content filtering API that uses advanced machine learning models to detect potentially harmful content across multiple categories. It provides real-time content analysis to identify and flag inappropriate material including hate speech, harassment, violence, sexual content, and other policy violations, helping maintain safe and compliant AI applications.Key Features of OpenAI Moderation
- Multi-Category Content Detection: OpenAI Moderation analyzes content across comprehensive categories including hate speech, harassment, violence, sexual content, self-harm, and illicit activities. The moderation API uses state-of-the-art models to provide nuanced detection with confidence scores for each category, enabling precise content filtering decisions.
- Customizable Threshold Controls: Fine-tune moderation sensitivity with adjustable confidence score thresholds for each content category. Organizations can configure custom threshold values to match their specific content policies and user community standards, balancing safety with user experience across different applications and use cases.
- High-Performance Real-Time Analysis: Built for production environments with low-latency processing and high throughput capabilities. The moderation system integrates seamlessly with OpenAI’s API ecosystem, providing consistent and reliable content filtering without impacting application performance or user experience.
Adding OpenAI Moderation Integration
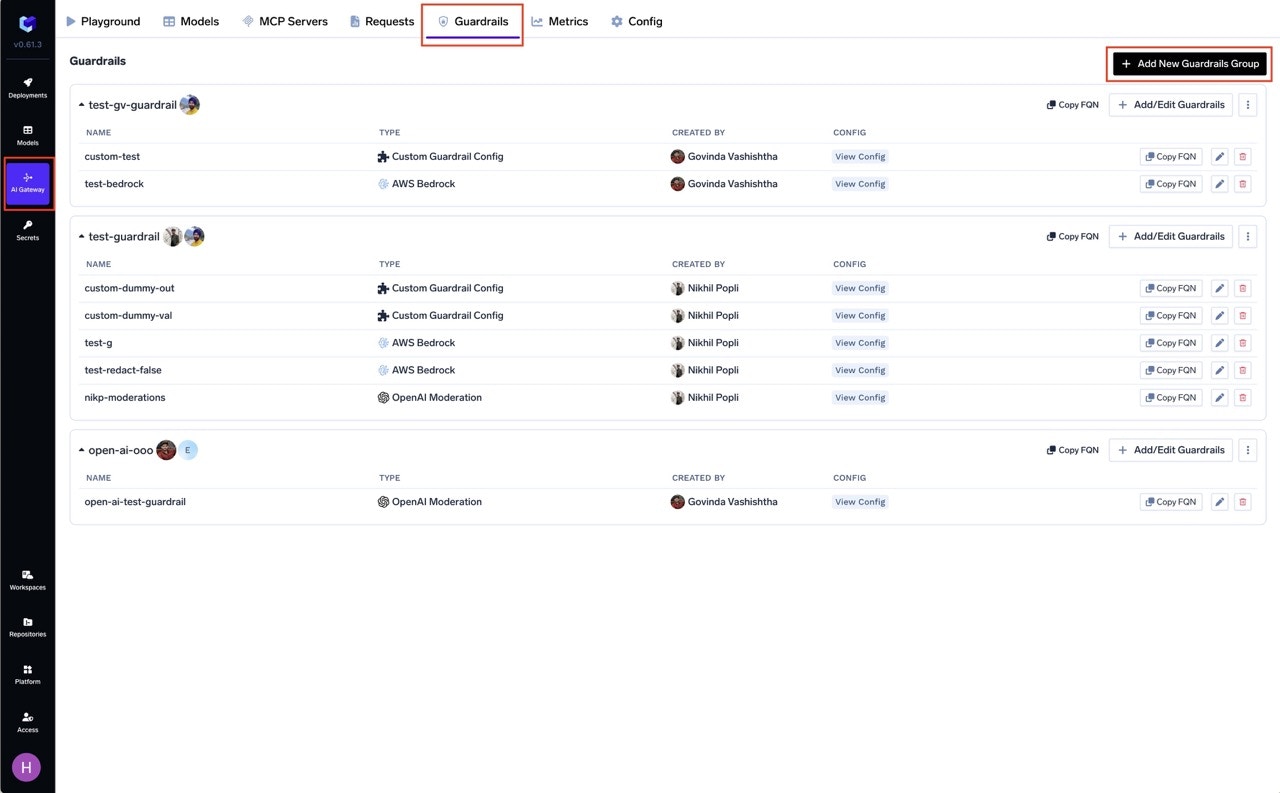
Navigate to Guardrails
- Name: Enter a name for your guardrails group.
- Collaborators: Add collaborators who will have access to this group.
- OpenAI Moderation Guardrail Config:
- Name: Enter a name for the OpenAI Moderation configuration.
- Base URL (Optional): Specify the base URL if needed.
- API Key: Enter your OpenAI API key.
- OpenAI Moderation Model: Choose the moderation model. This defaults to
omni-moderation-latest.
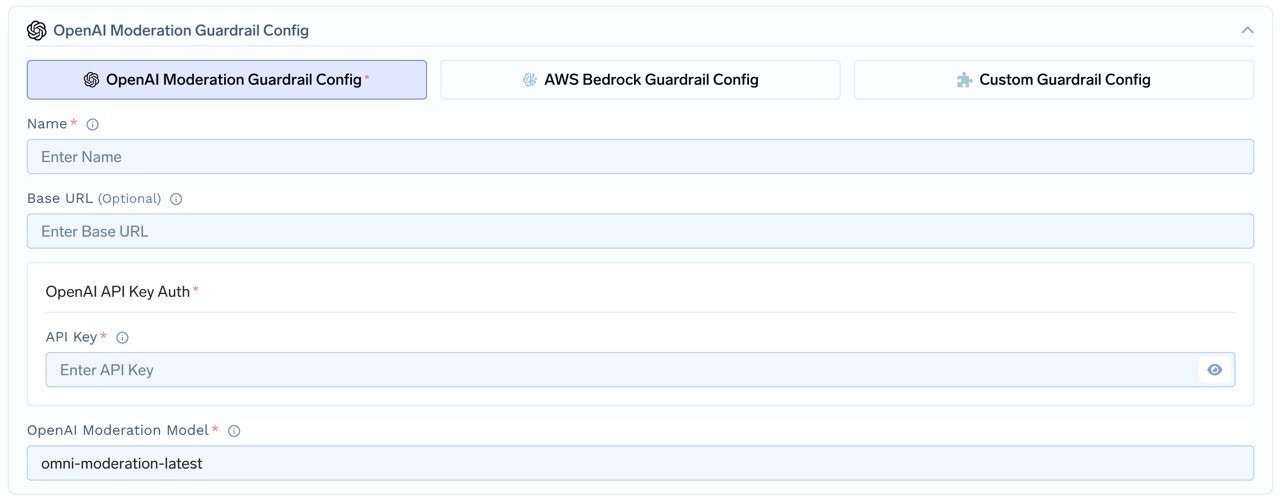
Fill in the OpenAI Moderation Form
How OpenAI Moderation Validation Works
When you integrate OpenAI Moderation with TrueFoundry, the system sends the last message to OpenAI’s moderation API and receives a response that indicates whether the content violates any safety categories.Response Structure
The OpenAI Moderation API returns a response with the following structure:Validation Logic
The system validates content by checking each category in the response:- Overall Flag: The
flaggedfield indicates if any category has been triggered. - Category-Specific Flags: Each category in the
categoriesobject returnstrueif that specific category is flagged. - Score Thresholds: The
category_scoresprovide confidence scores (0-1) for each category.
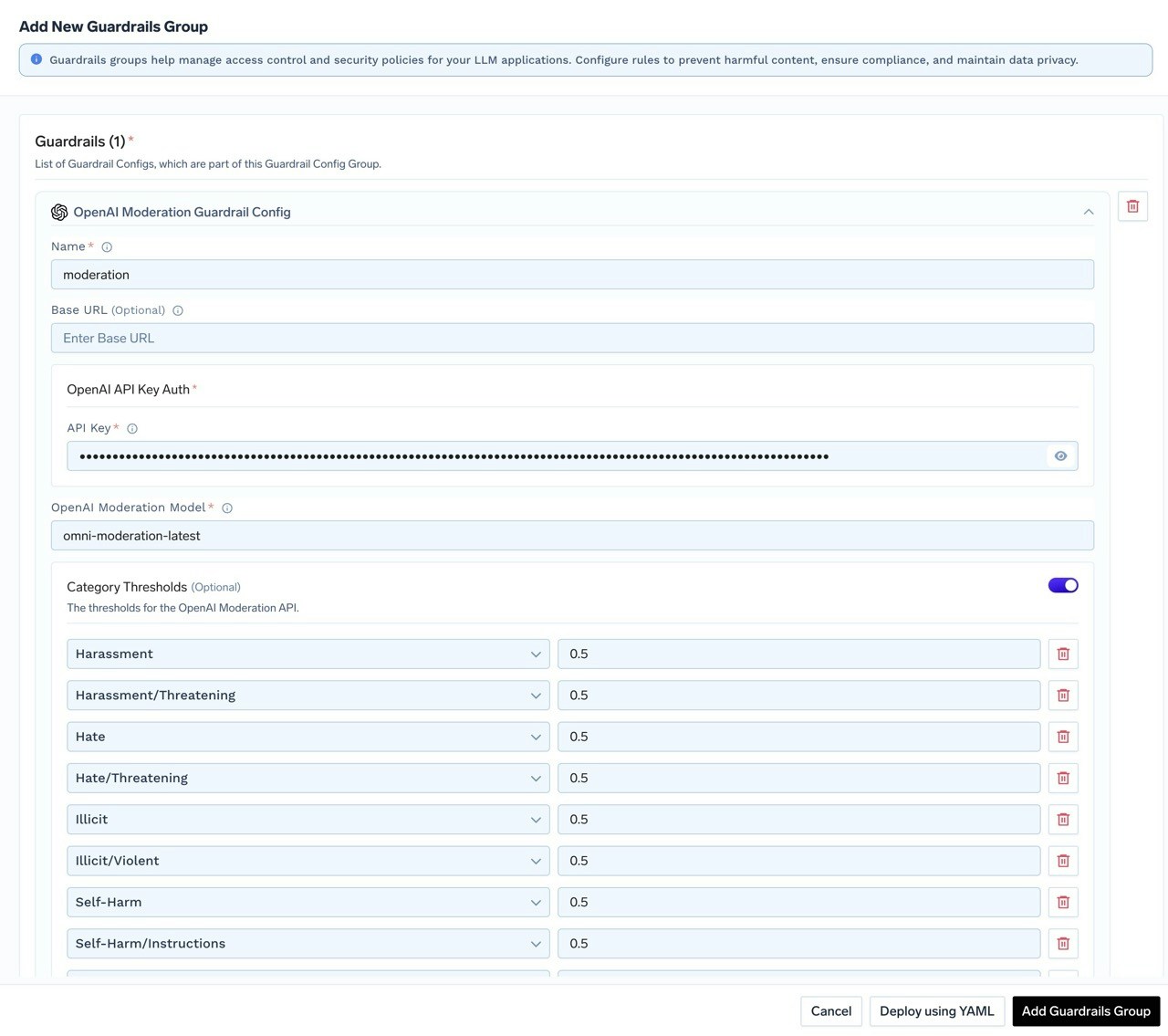
Customizable Thresholds
- If
categories.violenceistrue, or ifcategory_scores.violenceexceeds the configured threshold, the content is flagged for violence. - If
categories.harassmentisfalse, andcategory_scores.harassmentis below the threshold, the content passes the harassment check. - The
category_scores.violencevalue of0.8599265510337075indicates a high confidence (85.99%) that the content contains violence.
true or by exceeding its threshold), TrueFoundry will block the request and return an appropriate error message to maintain content safety standards.