Example: OpenAI OpenTelemetrySDK Instrumentation
This guide demonstrates how to use OpenTelemetry SDK to instrument OpenAI API calls and send traces to TrueFoundry’s OtelCollector.
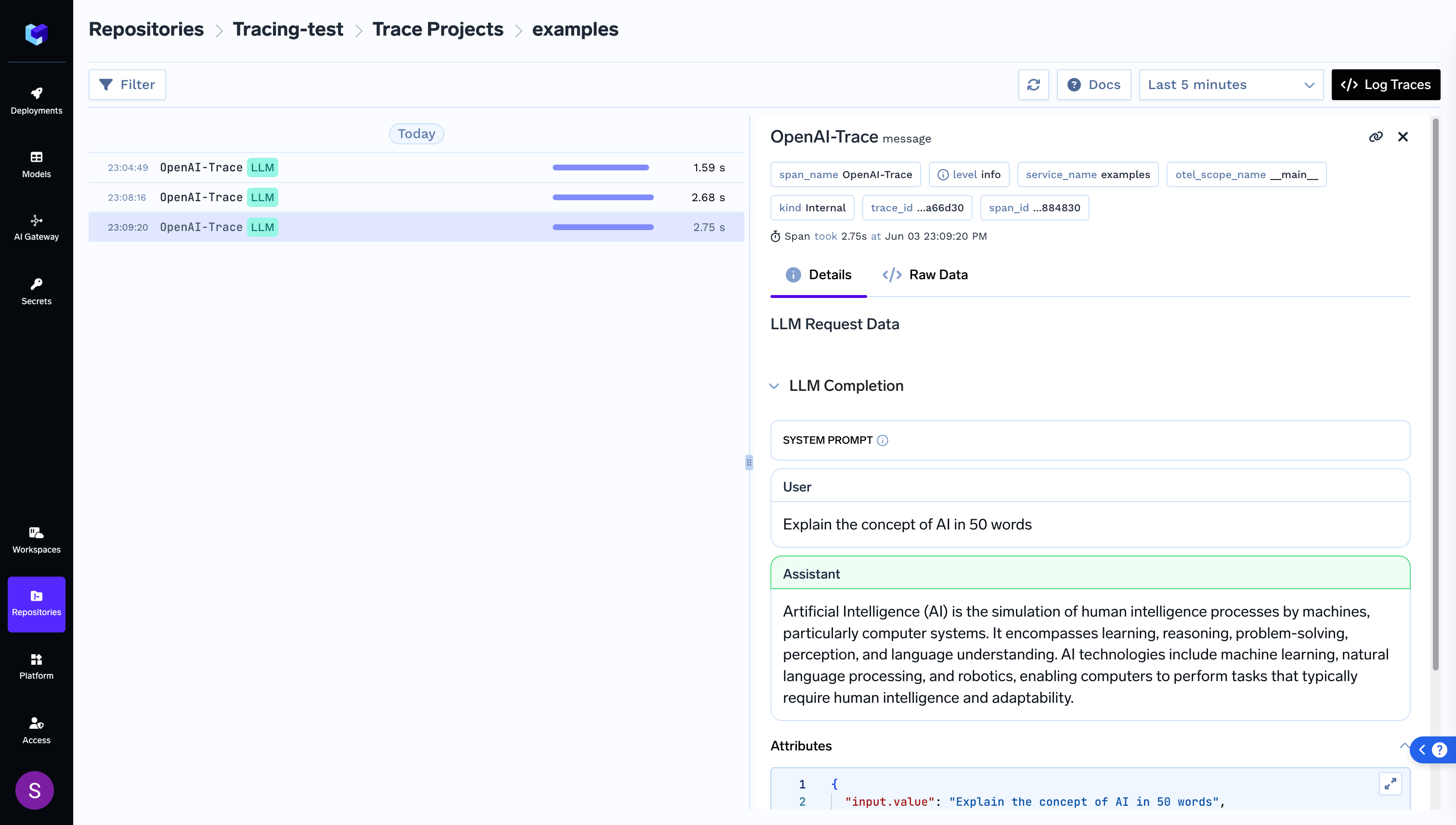
In this example, we’ll show how to instrument a Python application that makes calls to OpenAI’s API using OpenTelemetry’s context managers.
1
Create Tracing Project, API Key and copy tracing code
Follow the instructions in Getting Started to create a tracing project, generate API key and copy the
tracing code.
2
Install Dependencies
First, you need to install the following packages:
3
Add tracing code to Python application
To enable tracing, you’ll need to configure opentelemetry sdk and initialize it.
This section shows how to instrument your OpenAI API calls using OpenTelemetry’s context managers. The example demonstrates how to trace a chat completion request with proper attributes.
4
Run your application and view logged trace