Why Use Virtual Models?
Virtual Models provide several key benefits:- Abstraction: Use a single model identifier instead of managing multiple provider-specific models
- Reliability: Automatically route to healthy models when others fail or experience issues
- Performance: Distribute traffic based on weights, latency, or priority to optimize response times
- Flexibility: Easily switch between providers or adjust routing strategies without changing your application code
Creating a Virtual Model
Navigate to Virtual Models in AI Gateway
AI Gateway > Models and select Virtual Model.
Navigate to Virtual Models in AI Gateway
Create or Select a Virtual Model Provider Group and Set Access Controls
- User Role: Allows users/teams to use the virtual models for inference
- Manager Role: Allows users/teams to modify the virtual model configuration
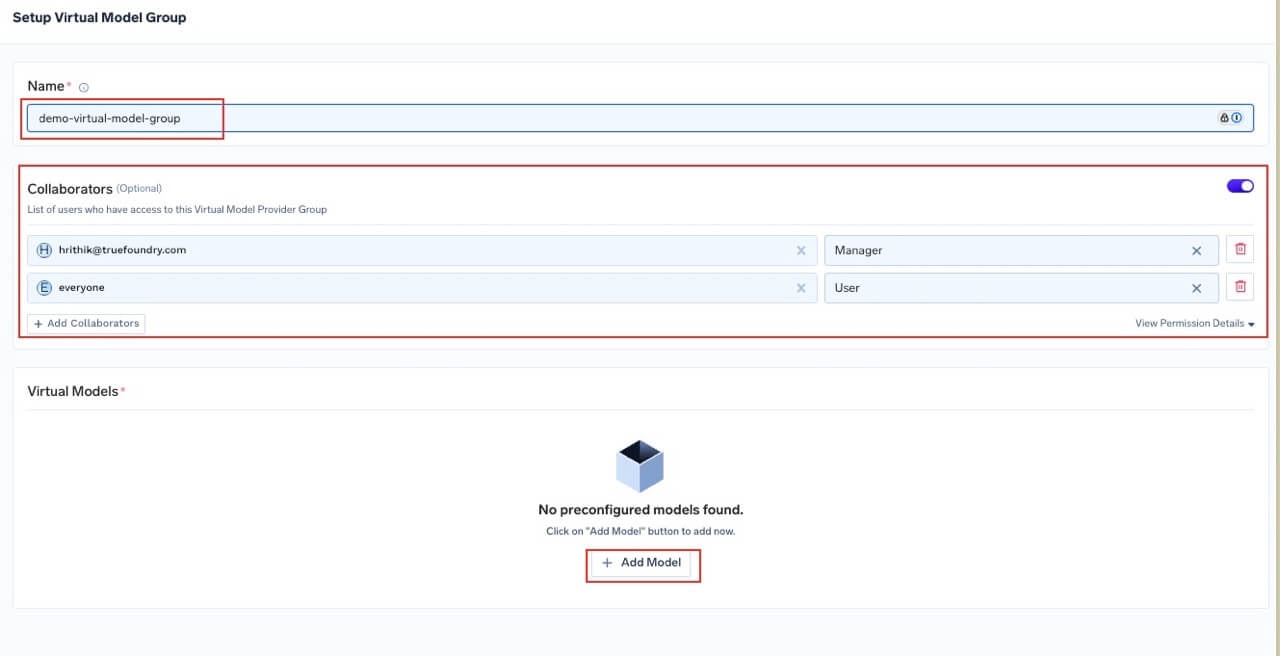
Create Virtual Model Provider Group and configure access controls
Configure Virtual Model Details, Routing Strategy, and Targets
-
Name: A unique identifier for your virtual model (e.g.,
gpt-4-production) -
Model Types: Select the supported operation types (chat, completion, embedding, etc.)
You can select multiple model types if your virtual model needs to support different operation types.
-
Routing Strategy: Choose how requests should be distributed across your target models. The AI Gateway supports three main routing strategies:
Weight-based Routing
Distribute traffic based on assigned weights. For example, with weights of 80 for one model and 20 for another, roughly 80% of requests go to the first and 20% to the second.Latency-based Routing
Route requests to the model with the lowest response latency. The gateway monitors response times (per output token) for each model and chooses the fastest healthy model.Priority-based Routing
Route requests in priority order with automatic fallback. Requests go to the highest priority model first (0 is highest). If it fails, the gateway falls back to the next one.For more on routing strategies, see the Load Balancing Overview. For configuration examples, check Commonly Used Routing Configurations. -
Target Models: For your chosen routing strategy, specify one or more target models that will receive traffic. For each target, you can configure:
- Target: Select the model from the dropdown.
- Retry Configuration: Number of retry attempts, delay between retries, and status codes that trigger retries.
- Fallback Status Codes: HTTP status codes that should cause fallback to other targets.
- Fallback Candidate: Whether this target can act as a fallback for others.
- Override Parameters: (Optional) Set request parameters to override when routing to this target (e.g., temperature, max_tokens).
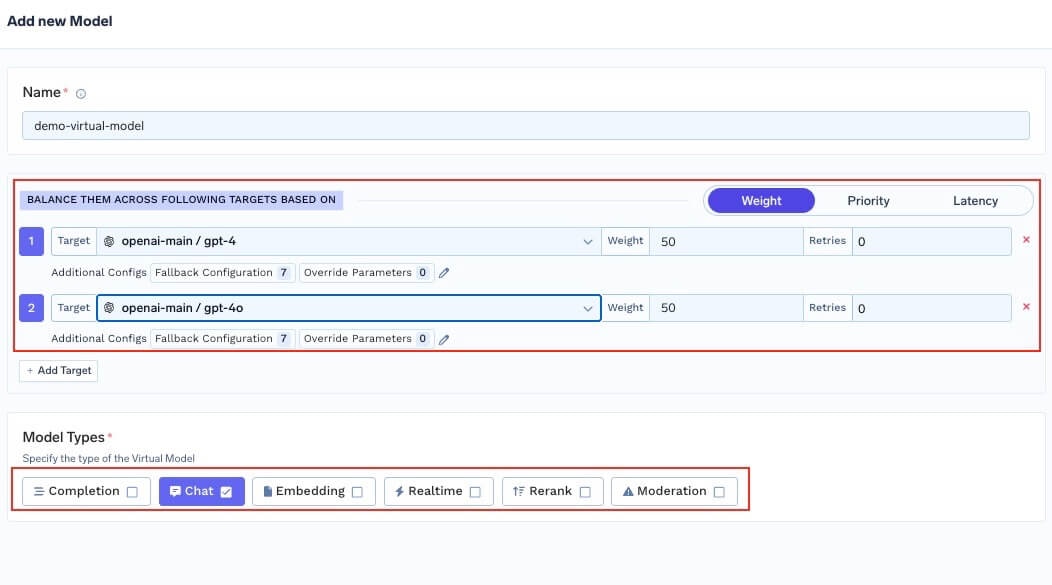
Configure virtual model details, routing strategy, and target models
Using Virtual Models
Once created, you can use virtual models just like any other model in the AI Gateway. The virtual model name follows the format:virtual-model-group-name/virtual-model-name.
Try Out Virtual Models in Playground
You can test your virtual models directly in the TrueFoundry Playground: Option 1: Click the try in playground button you see once you create the virtual model.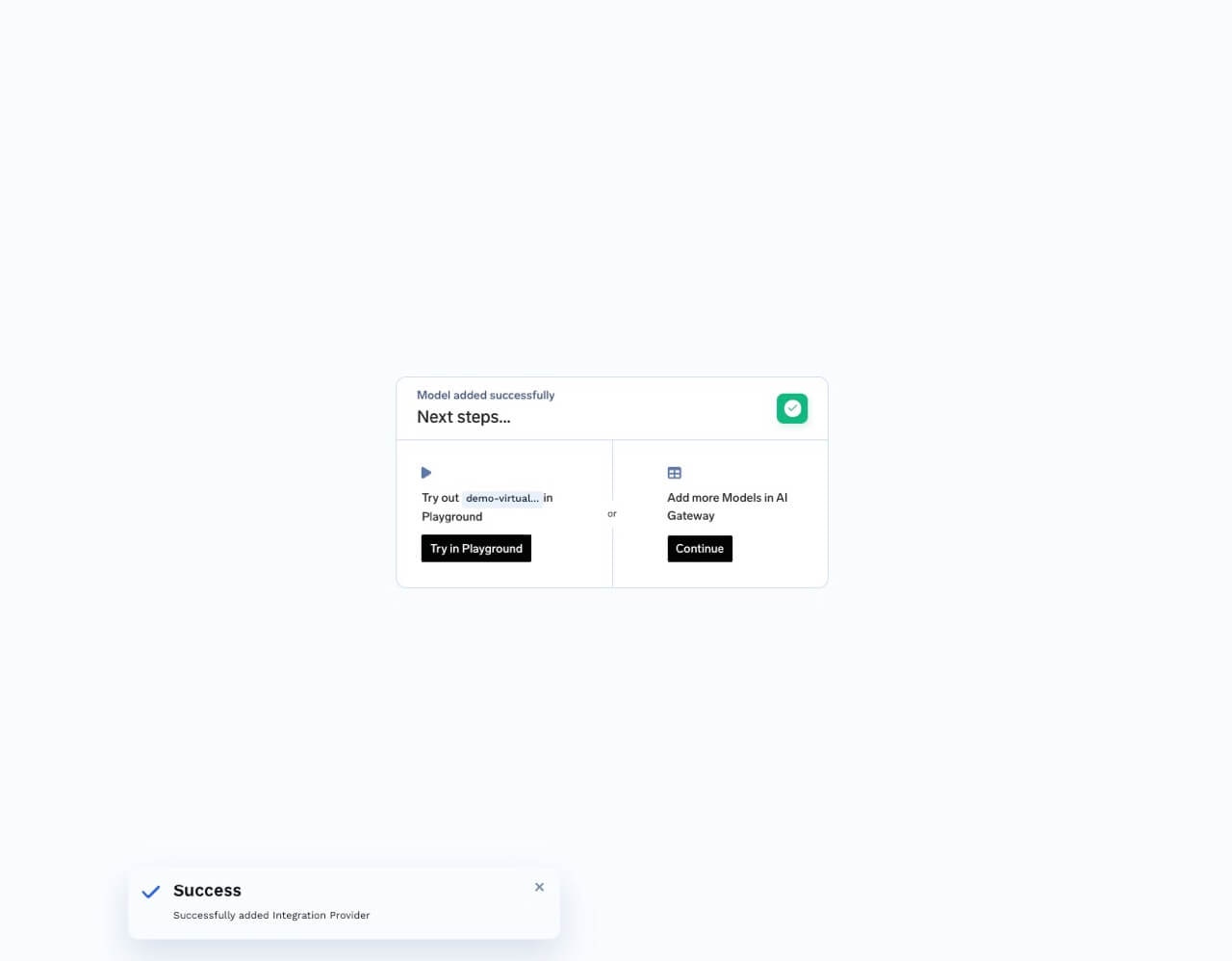
Try in playground button next to virtual model
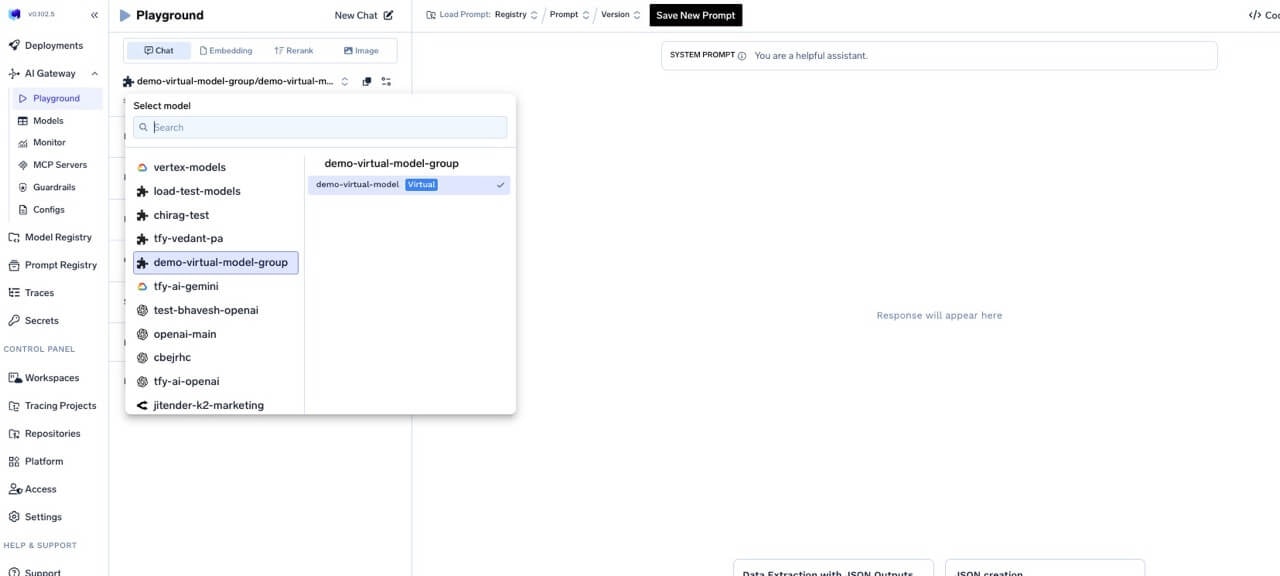
Select virtual model from playground dropdown
FAQ
Can I change the routing strategy after creating a virtual model?
Can I change the routing strategy after creating a virtual model?
How do I know which target model handled my request?
How do I know which target model handled my request?
Can I use virtual models with different model types?
Can I use virtual models with different model types?
What happens if all target models fail?
What happens if all target models fail?
Can I use virtual models in routing configurations?
Can I use virtual models in routing configurations?
What is the order of precedence between virtual model, header-based, and global routing configurations?
What is the order of precedence between virtual model, header-based, and global routing configurations?
- Virtual Model Configuration: If no header-based override is present, the routing rules defined within the virtual model itself will be used.
- Header-based routing: If you specify a routing configuration override in the request headers, this configuration will take the highest precedence for that request.
- Global Configuration: If neither of the above exist for the model or request, the system-wide (global) routing settings are applied.